











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






AWS研究热点:BMXNet - 基于MXNet的开源二进神经网络实现
2017年10月29日 由 yuxiangyu 发表
890662
0
近年来,深度学习技术在学术界和产业界取得了许多瞩目的成绩和突破。然而,最先进的深度学习模型计算代价昂贵,并且消耗大量的存储空间。移动平台,可穿戴设备,自主机器人和IoT设备等领域的众多应用也非常需要深度学习。这样,如何在低功耗的设备上应用深度学习模型就成为了一个极具挑战性的难题。
最近提出的二进神经网络(BNN)可以通过应用逐位运算替代标准算术运算来大大减少存储器大小和存取率。通过显着提高运行时的效率并降低能耗,让最先进的深度学习模型也能在低功耗设备上使用。这种技术结合了对开发者友好的OpenCL(与VHDL或Verilog相比),同时也让FPGA成为深度学习的可行选择。
在这篇文章中,我们要介绍BMXNet,它是一种基于Apache MXNet的开源BNN(二进神经网络)库。成熟的BNN层可以很好地应用于其他标准库组件,并且在GPU和CPU模式都可以工作。BMXNet由Hasso Plattner研究所的多媒体研究小组维护和开发,并根据Apache许可发布。库、示例项目以及预训练的二进制模型集合可从https://github.com/hpi-xnor下载。
框架
BMXNet提供支持输入数据和权重二值化的激活,卷积和完全连接的层。这些层被设计成相应MXNet变体的嵌入式替代,称为QActivation,QConvolution和QFullyConnected。它们提供了一个额外的参数act_bit,它可以控制由层计算的位宽度。在列表1和列表2中展示了使用推荐的二进制层与MXNet相比较的Python示例。在网络中的第一层和最后一层不能使用二进制层,因为这可能会大大降低精度。BMXNet中BNN的标准块结构:QActivation-QConvolution或QFullyConnected-BatchNorm-Pooling如下所示。

在传统的深度学习模型中,全连接层和卷积层主要依赖于矩阵的点积,这需要大量的浮点运算。相反,使用二值化权重和输入数据可以通过利用CPU指令xnor和popcount来执行高性能矩阵乘法实现。现在大多数的CPU都针对这些类型的操作进行了优化。每一行的A和每一列的B的乘法和加法的点积近似于,首先将它们与xnor操作结合起来然后统计结果中位组为1的数量,也就是位1计数。这样我们就可以利用这种按位操作的硬件支持。位1计数指令在支持SSE4.2的x86和x64 CPU上可用,而在ARM架构中,它包含在NEON指令集中。使用这些说明的未优化的GEMM(通用矩阵乘法)实现如列表3所示:

编译器内置的popcount由gcc和clang支持,它编译并转换为支持的硬件上的机器指令。BINARY_WORD是封装的数据类型,存储32(x86和ARMv7)或64(x64)矩阵元素,每个元素代表一个位。我们实施了几个优化版本的xnor的GEMM内核,我们尝试通过阻止和打包数据以及使用unrolling和并行化技术来利用处理器缓存层次结构。
训练和推理
在训练阶段,当将权重和输入值限制在离散值-1和+1之间时,我们仔细设计二值化层以精确匹配MXNet内置层的输出(使用BLAS点产品操作计算)。在计算点积后,我们将结果映射回所提出的xnor样式点积的值范围,如下式所示:
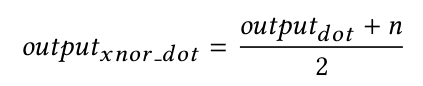
其中n是值范围参数。此设置可通过应用CuDNN实现GPU支持的大规模并行训练。然后,训练后的模型可用于对功能不强大的设备(无GPU支持和小型存储空间)进行推理,其中预测的前向传递将使用xnor和popcount操作而不是标准算术运算来计算点积。
在使用BMXNet训练网络后,权重存储在32位浮点变量中。这同样适用于以1位位宽训练的网络。我们提供一个model_converter,它读取二进制训练的模型文件,并封装QConvolution和QFullyConnected的权重。转换后,每个权重仅使用1位存储和运行时内存。例如,具有完全精确权重的ResNet-18网络(在CIFAR-10上)的大小为44.7MB。我们的模型转换器的转换实现29倍压缩,压缩后的文件大小为1.5MB。
分类精度
我们用BNN在MNIST(手写数字识别),CIFAR-10(图像分类)数据集上进行了实验。实验在具有Intel(R)Core TM i7-6900K CPU,64GB RAM和4TITAN X(Pascal)GPU的工作站上进行。

上表列出了我们在MNIST和CIFAR-10上训练的二进制和全精度模型的分类测试精度。我们能看到表内显示二进制模型非常小。并且准确性仍然很不错。我们还在ImageNet数据集上进行了二值化,部分二值化和全精度模型的实验,其中部分二值化模型结果不错,而完全二值化的模型仍具有很大的改进空间(更多细节访问论文:https://arxiv.org/abs/1705.09864)。
效率分析
我们对基于ubuntu160.04/64位平台的不同GEMM方法的效率进行了实验,采用英特尔2.50GHz×4 CPU,配有popcnt指令(SSE4.2)和8G RAM。测量在卷积层内进行。在这里,我们修改参数如下:filter number = 64,kernel size = 5×5,batch size = 200,矩阵大小M,N,K分别为64,12800,kernel_w×kernel_h×inputChannelSize。下图显示了结果。
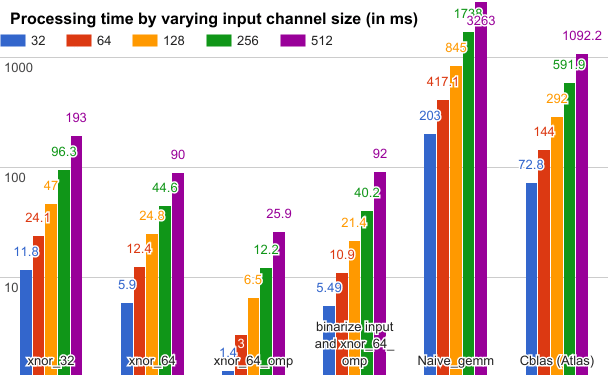
不同颜色的柱形表示不同输入通道大小的处理时间(以毫秒为单位):xnor_32和xnor_64表示xnor和gemm在32位和64位中操作;xnor_64_omp表示通过使用OpenMP并行程序库加速的64位xnor和gemm;“binarize input and xnor_64_omp”进一步累加了输入数据二值化的处理时间。通过积累输入数据的二值化时间,我们仍然实现了比Cblas方法快约13倍的加速度。
结论
我们在基于MXNet的C/C++中引入了BMXNet,一种开源二进制神经网络实现。在我们目前的实验中,我们已经实现了高达29倍模型大小的节省和更高效的二进制gemm计算。我们开发了针对Android和iOS的图像分类的示例应用程序,并使用了一个二进制的resne-18模型。
GitHub地址:https://github.com/hpi-xnor
编译自AWS博客。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消