


















人工智能将超越摩尔定律,成为科技创新的驱动者
- 硬件
- 软件
- 数据
硬件
在硬件方面,机器学习的日益增长的需求正在增加硅结构的需求。机器学习(尤其是深度学习)的需求提供了类似于特定的技术架构的回归。其结果是带来大量的新硬件,以及市场上的新机遇。
iPhone X手机采用了苹果开发的第一款GPU——A11仿生处理器。今年7月,百度宣布在其公共云平台上部署Xilinx FPGA的电路,以加速其深度学习应用。华为预计将推出一款“结合CPU、GPU和人工智能功能”的应用处理器,以支持“智能计算”。
Efinix(可编程芯片初创公司)在Xilinx的主要资金支持下,将在2018年推出新的量子可编程技术,芯片会将人工智能技术推向更小、更有效的边缘。
英特尔推广的CPU占据了PC时代的主导地位。对比竞争对手如摩托罗拉的68000和PowerPC系列以及Sun的Sparc芯片,它的x86架构成为了工程师主要选择。
而且英特尔的结构性优势(拥有架构,并获得市场份额,从而导致大型经济规模的增长),让我们在x86平台上,如Nexgen、Cyrix和NEC,都能看到它。只有AMD在PC芯片市场上的份额还在下降,占据不到25%的市场份额。
在移动领域,ARM的CPU设计在我们的智能手机和平板电脑中超过九成。这些芯片正越来越多地进入笔记本电脑和其他设备。英特尔在这个市场上并没有取得任何成功,正如市场份额所证明的那样,其他许多公司也没有成功。
英特尔或ARM能主宰人工智能领域吗? 许多分析师,如Ark投资公司的詹姆斯·王认为,英伟达在这一领域有着重要的领先地位。英伟达的GPU是深度学习的选择工具。人们认为,在2008年的深度学习中取得的学术突破,是由英伟达发布的一种名叫CUDA的编程方法创造的。其结果是,自那以后,无论是单独的还是大规模的集群,大多数的机器学习都开始在英伟达的GPU芯片上运行。
近十年前,英伟达还没有成为机器学习人工智能社区的宠儿。但它一直在不断地进步:
1.英伟达将其芯片的架构效率提高了10倍,超过了4代的GPU;
2.英伟达支持所有用于深度学习的软件框架,而其竞争对手主要支持TensorFlow和Caffe;
3.英伟达开源的深度学习加速器,专门用于推断TPU,鼓励创业公司在现有基础设施的基础上进行建设。
英伟达不久前宣布了其新的自动驾驶平台Pegasus,该平台每秒可执行320万亿次计算,是其前代产品处理能力的10倍以上。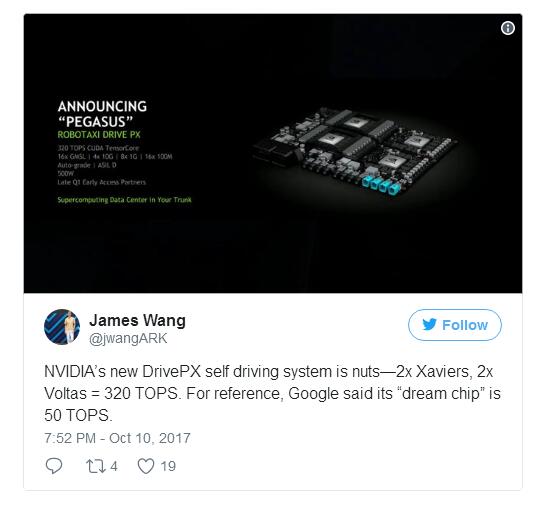 那么英伟达能否追赶上英特尔呢? 它的定位很好,因为和英特尔一样,它有市场份额,有开发人员使用它,而且它的规模经济增长。这些特征通常将平台推至非常大的市场份额。
那么英伟达能否追赶上英特尔呢? 它的定位很好,因为和英特尔一样,它有市场份额,有开发人员使用它,而且它的规模经济增长。这些特征通常将平台推至非常大的市场份额。
这是否足以阻止来自激进的新架构的竞争? 当谷歌宣布其新的围棋系统“AlphaGoZero”时,它不仅宣布了一种新的方法(无监督学习),还宣布了一种新的芯片架构。Go的第一个版本运行在176个英伟达GPU上。新的(更好的版本)运行在Google自己的一个张量处理单元上。
从投资角度来看,英伟达的股价在过去4年里增长了近14倍。不过,撇开早期优势不谈,目前还不清楚英伟达是否能够长期赢得这个市场。
软件
用于管理或应用机器学习的大多数关键框架都是开源的。行业领导者是谷歌的TensorFlow,它是软件资源库GitHub上访问最多的深度学习框架。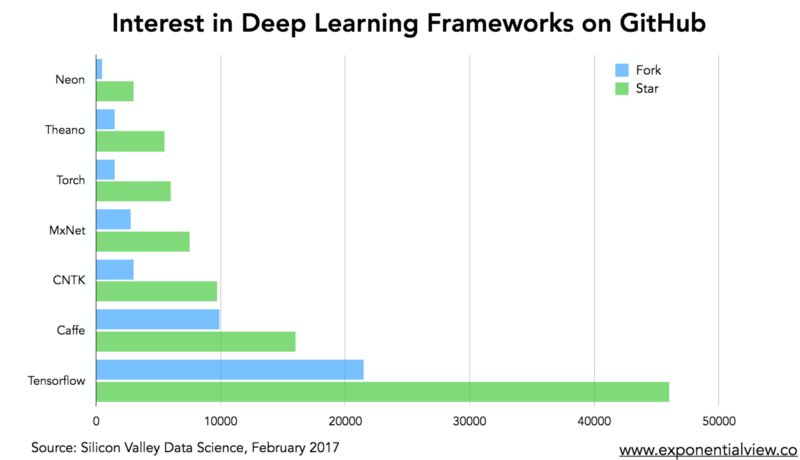 但其他几种工具包也在取得进展,比如百度的Paddle和亚马逊MxNet。虽然对深度学习应用程序的广泛讨论往往集中在这些工具包上,但它们只是用于机器学习工作所需的全部软件堆栈的一小部分。
但其他几种工具包也在取得进展,比如百度的Paddle和亚马逊MxNet。虽然对深度学习应用程序的广泛讨论往往集中在这些工具包上,但它们只是用于机器学习工作所需的全部软件堆栈的一小部分。
思考如何使机器学习有用的一种方法是,把它想象成一个工厂的操作。输入是数据。推论是过程。输出是预测,比如什么时候到达目的地,或者顾客想把什么东西放到他们的购物车里。但是输出并不总是正确的,因此输出的质量需要被度量。“学习”这个词的关键在于,良好的机器学习部署将会学习如何从期望的水平上减少输出的偏差。
你操作算法的方式需要通过机器学习管道。它就像一个工厂。它有一个装货间(数据被加载),入站供应的质量控制是一组切割过程,然后将值添加到数据中,最后产品被产出。
任何公司在任何规模上使用机器学习,都需要部署一个机器学习管道。在加州大学伯克利分校,AMP(Algorithms, Machine & People)实验室是大数据和机器工具的“孵化”场所。实验室负责像Spark(一个非常快的实时数据处理引擎)和Mesos(一个用于集群计算的资源编制平台)这样的项目。Spark和Mesos都已经变成了全面的Apache开源项目。AMP实验室有一个名为“崛起实验室”的堂兄弟,该实验室正遵循类似的策略,以开发日益增长的对软件框架的需求,该框架可以满足大规模实时机器学习系统的需求。
开源已经改变了软件行业。将软件授权的成本降至零,而且已经掀起了一波创新浪潮。但是在人工智能领域,商业开源并没有产生任何巨大的成功。
作为最大的开源公司,RedHat的市价达到了约213亿美元,营收为24亿美元,这是一家中等规模的上市科技公司。Mesosphere (一个围绕Apache Mesos构建的商业企业)已经筹集了近1.25亿美元的私人资本,可能还会打破这种模式。
在软件公司中,软件公司本身并没有大赢家。显然,使用机器学习来推动业务的谷歌和Facebook得到了一笔不错的投资。而且建立在开源基础上的服务业务也做得相当不错。但是软件工具为了其利益通常都有适度的结果。所以不能确定AI是否一定会改变这种现象。
数据
经济学家认为数据是世界上最有价值的资源。对于情报信息时代的公司来说,权力不仅在于积累丰富的数据,还在于获取更多的信息,从而为用户提供便利、效率和洞察力。
随着从手表到汽车的设备连接到互联网,容量也在增加:有人估计自动驾驶汽车每秒钟将产生100千兆字节的容量。与此同时,人工智能技术,如机器学习,从数据中提取出更多的价值。算法可以预测客户何时可以购买某种东西,或者一个人是否有患病的风险。这些都反映了数据的重要性。所以像通用电气和西门子这样的工业巨头现在把自己作为数据公司出售一点也不奇怪。
最强大的互联网公司有很大的优势。如果你是谷歌或亚马逊,你已经有了大量关于消费者行为的数据。如果你没有,那么你需要建立一个数据策略。
这反过来又为企业家创造了机会。以Q Data和Tasko.Ai为例,Q Data是一个销售和购买原始数据和汇总数据的市场,而Tasko则提供了按需数据收集。这两家公司的发展都处于早期阶段,所以现在就断言它们是否会起作用还为时过早。但很显然,从销售数据中赚钱是很有可能的。以汤森路透或普氏金融服务公司为例,它们都通过出售有用的数据获得了巨额收入。
一项技术可以帮助那些公司将数据货币化,那就是区块链。
Trent大学的McConaghy说:
- 这是这个问题。许多企业都有大量的数据,但不知道如何使它们变得可用。它们隐藏着潜在的价值。相反,很多初创公司都知道如何利用人工智能将数据转化为价值,但他们却渴望获得更多的数据。
数据共享的一个衰减因素是,调整营利性公司的数据性质的动机是很困难的。数据不像物理小部件。如果你给我看一个小部件,我就不能免费复制它。但数据可以。另外,如果我复制你的数据并利用它,数据不会阻止你使用它。这与现代经济的运作方式格格不入。
基于区块链的处理数据的方法可能会改变这种情况。这条链将会让我们知道谁是谁的数据来源,谁使用了它。区块链的分散控制机制将使参与者能够信任整个系统。它可能会为数据的合作创造合适的基础,从而有合适的经济激励来鼓励投资。
换句话说,为未来的工厂供应需要大量不同类型的数据。为公司提供这些数据或生成数据的机会是存在的。在更久以后,区块链可以创建共享网络,让公司可以使用自己的数据(并从中获益)。
结论
目前,只有少数几家公司对机器学习的计划有了控制,并实施了这一计划。这些公司大多是消费者互联网公司(如亚马逊或Facebook)。绝大多数公司还没有实施这样的系统。实际上,这些公司中没有一家拥有谷歌的内部能力,而且将依赖于第三方提供的现成服务、工具或训练。许多行业都在加倍努力,提高数据输入的范围和质量,以掌握他们的业务。
在过去的几年里,我们一直在大力学习,并取得了巨大的成绩。其他方法(如强化学习、概率模型)将开始收获回报,启动我们可以开发和部署的新型应用程序。
最后,那些用新颖的方法来“喂养”AI的公司可能会有一种考虑,他们认为最令人兴奋的领域是数据和区块链的结合,为人工智能应用程序创建共享网络。









