











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






在谷歌开源MNIST数据集上试验深度学习SWISH激活函数
2017年11月03日 由 xiaoshan.xiang 发表
220325
0
在深度学习中有一个新的激活函数Swish,它是由谷歌的研究人员研发的,Swish激活函数是f(x)= x* sigmoid(x)。非常简单。
根据他们的论文,即使超参数调整为ReLU,Swish激活函数的性能也比纠正线性单位[rectified linear units](ReLU(x)= max(0,x))更好。这是来自一个简单搜寻函数[looking function]的结果。在本文的其余部分,我将简要介绍Swish激活函数,然后将通过使用MNIST数据集的Swish激活函数来显示一些有趣的结果。希望这能帮助你决定是否要在自己的模型中使用Swish激活函数。
论文地址:https://arxiv.org/abs/1710.05941v1
图像化的Swish激活函数看起来类似于ReLU:
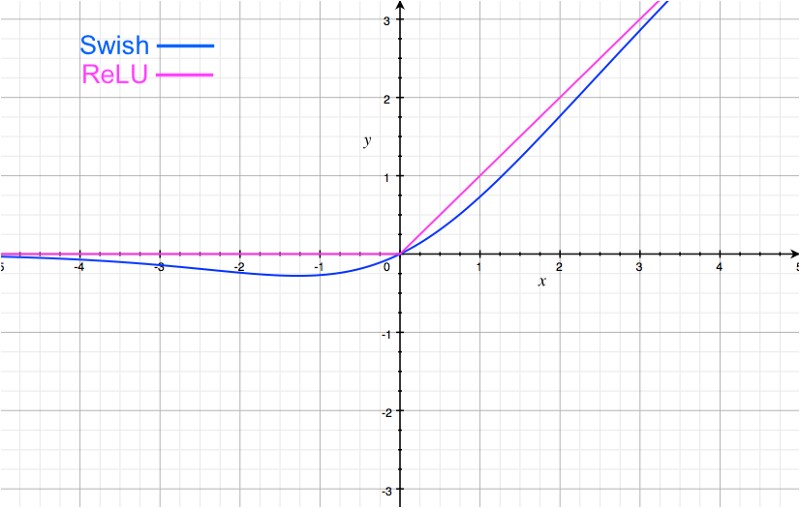
重要的区别在于x轴的负半轴区域。由于在负半轴区域中怪异的尾状,当输入增加时,Swish激活函数的输出可能会减少。这很有趣,也可能是Swish激活函数特有的。大多数激活函数(如sigmoid、tanh & ReLU)都是单调的,即当输入增加时,它们的值从不减少(值可能保持不变,就像ReLU激活函数在x < 0时的情况)。
Swish激活函数位于线性和ReLU激活函数之间。如果我们考虑一个简单的Swish 激活函数f(x)=2x*sigmoid(beta* x),其中beta是一个可学习的参数,可以看出,如果beta = 0,sigmoid部分总是1 / 2,所以f(x)变成线性。另一方面,如果beta值非常高,那么sigmoid部分就像一个二进制激活(x < 0,x > 0)。因此,f(x)接近ReLU函数。因此,标准的swish函数(beta = 1)提供了两个极端[extreme]之间的平滑插值[smooth interpolation]。为什么Swish应该工作,这是论文中最可信的论点。另一种观点是,与ReLU激活函数不同的,Swish激活函数是非单调的,与ReLU激活函数相同的是,下面有界限并且与上面无界限(所以你不会在深度网络中以梯度消失[vanishing gradients]为结束)。
现在我们已经很好地理解了Swish激活函数,让我们看看它如何很好地按时测试MNIST数据集。我使用一个非常简单的带有2个隐藏层的前馈结构,并训练具有五个不同激活的五个模型:线性(没有激活),sigmoid,ReLU、标准Swish(β是固定值1.0)和一个Swish的变分[variation],其中参数beta的初始设置为1.0,但随着时间的推移通过神经网络进行学习。在所有的5个模型中,权值都是通过高斯分布用相同的随机种子初始化的,唯一的区别就是激活函数。同样,我尝试了三种不同标准偏差(sigma = 0.1,0.5,1.0)的高斯分布。如果标准偏差太大,权值将被初始化,远离它们的最优值,网络将很难收敛。我想看看Swish激活函数是否能在初始化时帮助收敛。下面是结果:
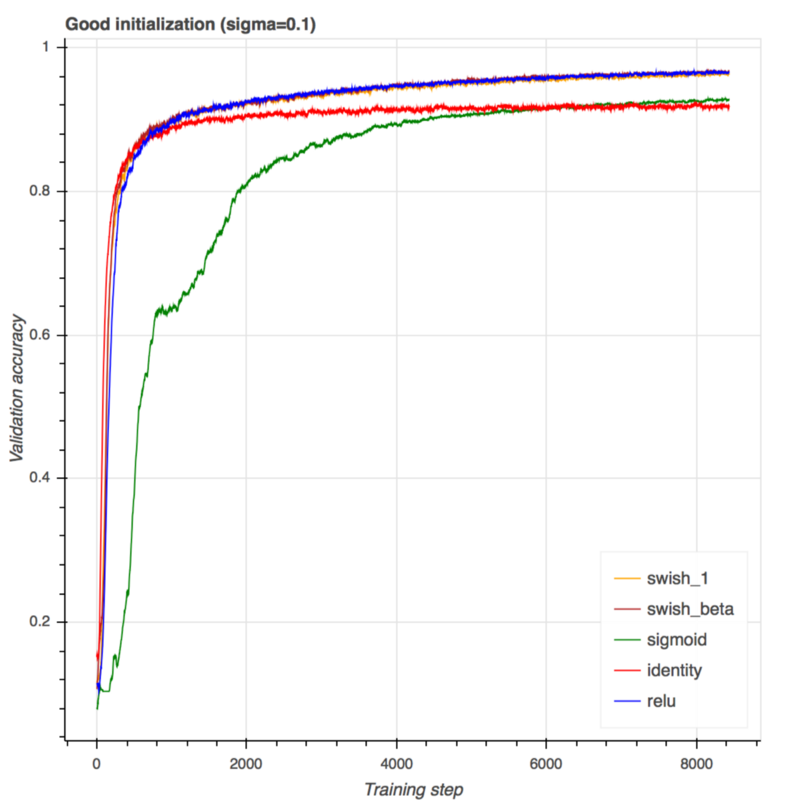
当使用一个很好的权值初始化时,ReLU,swish_1(beta = 1)和swish_beta几乎都执行相同的操作。可能由于问题很简单,学习参数beta没有明显的优势。
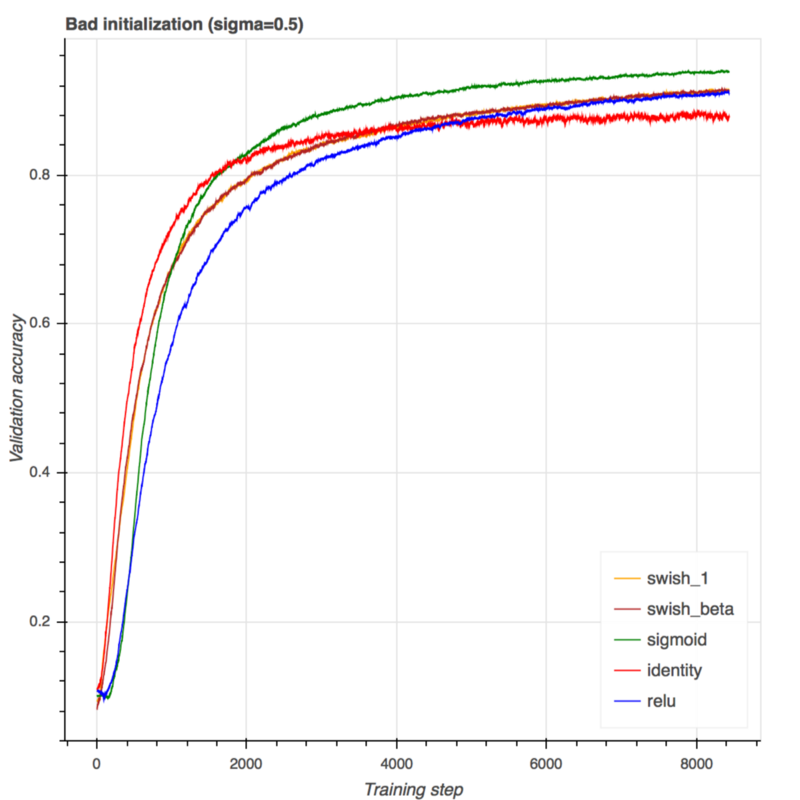
这是一个相当糟糕的初始化。这个问题有点挑战性。令人惊讶的是sigmoid在这里工作得很好。在ReLU & swish中,swish比ReLU好得多(尽管两者最终都收敛到相同的性能)。和上次一样,学习参数beta没有太大的优势,也没有提高性能。
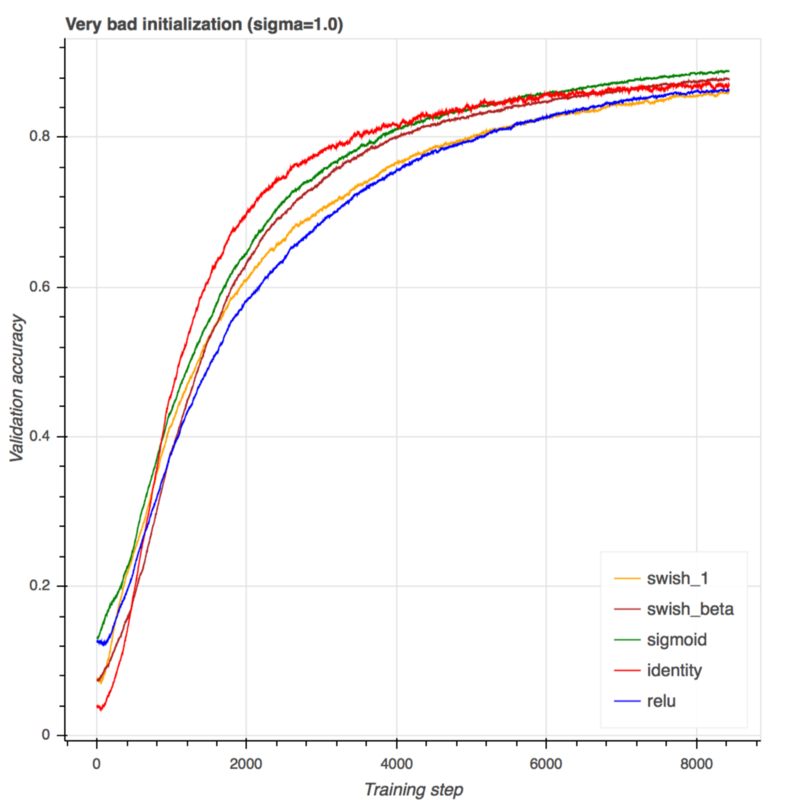
这是一个非常糟糕的初始化。Sigmoid和线性激活效果非常好,这更多的是由于MNIST数据集本身的线性可分性而非激活。其中,swish_1显示出了ReLU比更好的性能。如果有足够的训练步骤,它们都收敛于相同的性能。在这里,我们看到了学习参数beta的巨大优势。Swish_beta在这个困难的问题上有明显的更好的性能。
下面的图像是在案例中评估学习参数beta的演变:
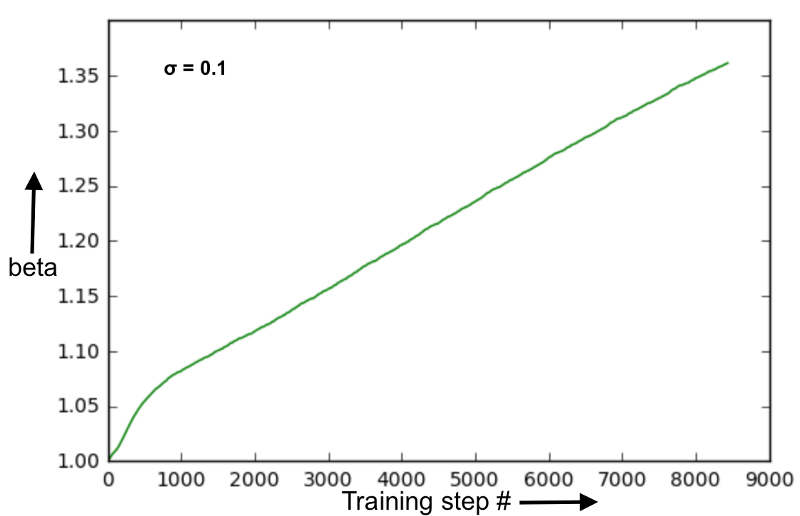
当初始化接近最优值时,beta演变顺利。这些训练步骤不足以使参数beta值饱和。请记住,在这种情况下,学习参数beta并没有带来更好的性能。在训练期间预测网络最终性能的同时监控参数beta值似乎是一件很难的事(参见下面sigma = 1.0的图像)。
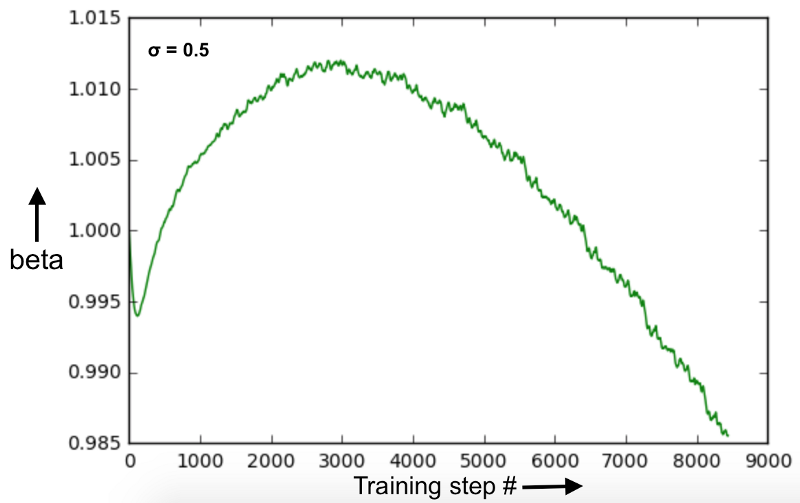
由于初始化离最优值有点远,参数beta似乎不太稳定。与固定的beta = 1.0相比,也不会导致性能显著提高或损失。
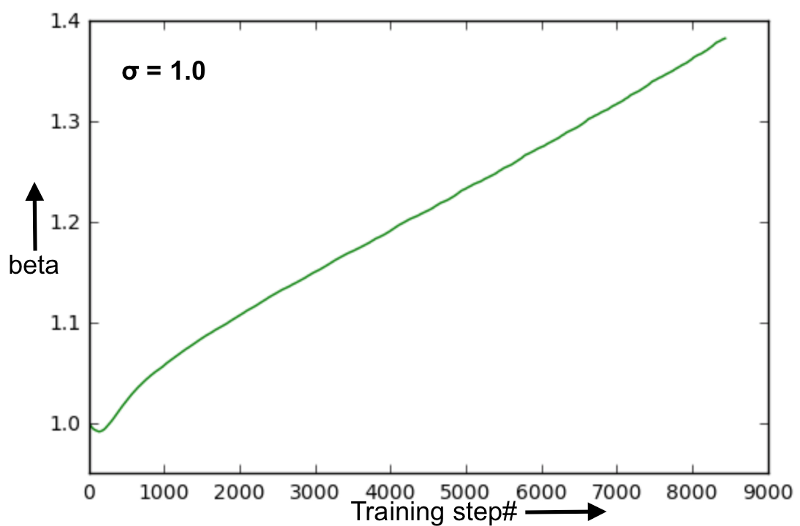
虽然最初的权值远离最优值,但参数beta的演化还是平稳的。尽管这一趋势与sigma = 0.1非常相似,但在这种情况下,通过学习参数beta,性能有了显著的提高,但在之前的案例中并没有这种情况。这进一步表明,在训练期间监控beta的进化过程,很难分辨出神经网络将如何执行。
这些结果是通过简单的数据集上简单的神经网络得到的。所以,我们不应该过分解读它们。这里有一些关键的结论:
我在GitHub上上传了重新生成这些结果的完整代码。
代码地址:https://github.com/dataplayer12/swish-activation
根据他们的论文,即使超参数调整为ReLU,Swish激活函数的性能也比纠正线性单位[rectified linear units](ReLU(x)= max(0,x))更好。这是来自一个简单搜寻函数[looking function]的结果。在本文的其余部分,我将简要介绍Swish激活函数,然后将通过使用MNIST数据集的Swish激活函数来显示一些有趣的结果。希望这能帮助你决定是否要在自己的模型中使用Swish激活函数。
论文地址:https://arxiv.org/abs/1710.05941v1
激活函数Swish与ReLU之间的区别
图像化的Swish激活函数看起来类似于ReLU:
重要的区别在于x轴的负半轴区域。由于在负半轴区域中怪异的尾状,当输入增加时,Swish激活函数的输出可能会减少。这很有趣,也可能是Swish激活函数特有的。大多数激活函数(如sigmoid、tanh & ReLU)都是单调的,即当输入增加时,它们的值从不减少(值可能保持不变,就像ReLU激活函数在x < 0时的情况)。
Swish激活函数位于线性和ReLU激活函数之间。如果我们考虑一个简单的Swish 激活函数f(x)=2x*sigmoid(beta* x),其中beta是一个可学习的参数,可以看出,如果beta = 0,sigmoid部分总是1 / 2,所以f(x)变成线性。另一方面,如果beta值非常高,那么sigmoid部分就像一个二进制激活(x < 0,x > 0)。因此,f(x)接近ReLU函数。因此,标准的swish函数(beta = 1)提供了两个极端[extreme]之间的平滑插值[smooth interpolation]。为什么Swish应该工作,这是论文中最可信的论点。另一种观点是,与ReLU激活函数不同的,Swish激活函数是非单调的,与ReLU激活函数相同的是,下面有界限并且与上面无界限(所以你不会在深度网络中以梯度消失[vanishing gradients]为结束)。
实验
现在我们已经很好地理解了Swish激活函数,让我们看看它如何很好地按时测试MNIST数据集。我使用一个非常简单的带有2个隐藏层的前馈结构,并训练具有五个不同激活的五个模型:线性(没有激活),sigmoid,ReLU、标准Swish(β是固定值1.0)和一个Swish的变分[variation],其中参数beta的初始设置为1.0,但随着时间的推移通过神经网络进行学习。在所有的5个模型中,权值都是通过高斯分布用相同的随机种子初始化的,唯一的区别就是激活函数。同样,我尝试了三种不同标准偏差(sigma = 0.1,0.5,1.0)的高斯分布。如果标准偏差太大,权值将被初始化,远离它们的最优值,网络将很难收敛。我想看看Swish激活函数是否能在初始化时帮助收敛。下面是结果:
当使用一个很好的权值初始化时,ReLU,swish_1(beta = 1)和swish_beta几乎都执行相同的操作。可能由于问题很简单,学习参数beta没有明显的优势。
这是一个相当糟糕的初始化。这个问题有点挑战性。令人惊讶的是sigmoid在这里工作得很好。在ReLU & swish中,swish比ReLU好得多(尽管两者最终都收敛到相同的性能)。和上次一样,学习参数beta没有太大的优势,也没有提高性能。
这是一个非常糟糕的初始化。Sigmoid和线性激活效果非常好,这更多的是由于MNIST数据集本身的线性可分性而非激活。其中,swish_1显示出了ReLU比更好的性能。如果有足够的训练步骤,它们都收敛于相同的性能。在这里,我们看到了学习参数beta的巨大优势。Swish_beta在这个困难的问题上有明显的更好的性能。
下面的图像是在案例中评估学习参数beta的演变:
当初始化接近最优值时,beta演变顺利。这些训练步骤不足以使参数beta值饱和。请记住,在这种情况下,学习参数beta并没有带来更好的性能。在训练期间预测网络最终性能的同时监控参数beta值似乎是一件很难的事(参见下面sigma = 1.0的图像)。
由于初始化离最优值有点远,参数beta似乎不太稳定。与固定的beta = 1.0相比,也不会导致性能显著提高或损失。
虽然最初的权值远离最优值,但参数beta的演化还是平稳的。尽管这一趋势与sigma = 0.1非常相似,但在这种情况下,通过学习参数beta,性能有了显著的提高,但在之前的案例中并没有这种情况。这进一步表明,在训练期间监控beta的进化过程,很难分辨出神经网络将如何执行。
结论
这些结果是通过简单的数据集上简单的神经网络得到的。所以,我们不应该过分解读它们。这里有一些关键的结论:
- 如果神经网络足够简单,那么ReLU和Swish激活函数应该执行相同的操作。在这种情况下,ReLU激活函数会有一个优势,因为Swish激活函数需要一个乘法步骤(x * sigmoid(x)),这意味着在性能上没有明显的增益;
- 即使标准Swish激活函数运行良好,也不可能通过学习参数beta获得额外的增益。当问题无法用ReLU激活函数来解决时,学习参数beta似乎效果最好;
- 如果在训练过程中参数beta的演变为模型的最终性能提供一些线索,是最好的。从这些有限的测试看来,事实并非如此。
代码
我在GitHub上上传了重新生成这些结果的完整代码。
代码地址:https://github.com/dataplayer12/swish-activation

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消