


















将深度学习专门化: 吴恩达的21节Deeplearning.ai课程学习经验总结
 截止到2017年10月25日,吴恩达在Coursera上目前有3门新的深度学习课程:
截止到2017年10月25日,吴恩达在Coursera上目前有3门新的深度学习课程:1.神经网络和深度学习(Neural Networks and Deep Learning)
2.改善深度神经网络:调优超参数,正则化和优化(Improving Deep Neural Networks: Hyperparamater tuning, Regularization and Optimization)
3.构建机器学习项目(Structuring Machine Learning Projects)
这三门课程都非常有用,大家能从吴恩达那里学到了很多实用的知识。他在课程上的讲解上非常出色地过滤掉了行业中的各种流行语,并以一种清晰简洁的方式解释了这些概念。例如,吴恩达明确指出,监督深度学习只不过是一个多维曲线拟合过程,而任何其他的代表性的理解,如对人类生物神经系统的通用参照,都是最宽松的。专门化只需要在Python中使用基本的线性代数知识和基本的编程知识。
第1课:为什么深度学习越来越热门?
在过去的两年中,90%的数据都是被收集的。深度神经网络(DNN)能够利用大量的数据。因此,深度神经网络可以在较小的网络和传统的学习算法中占据主导地位。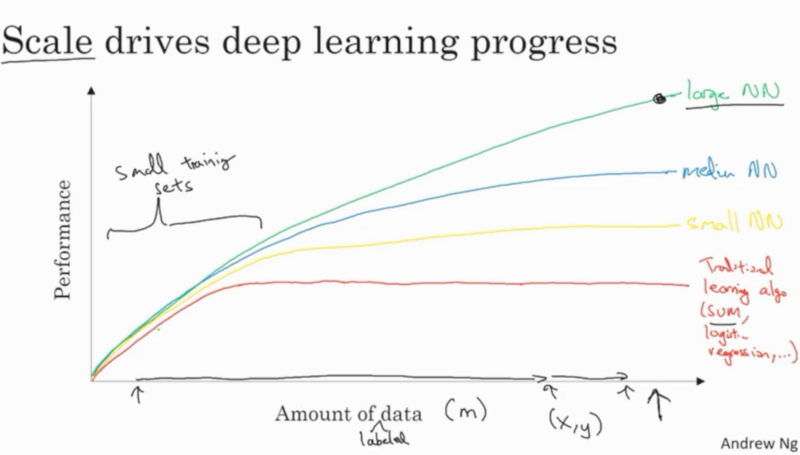
Scale如何在深度神经网络中推动性能
此外,有许多算法的创新使深度神经网络的训练速度变得更快。例如,从一个sigmoid激活函数转换成一个RELU激活函数,对梯度下降这样的优化过程产生了巨大的影响。这些算法的改进使得研究人员可以更快速地迭代代码周期,从而带来更多的创新。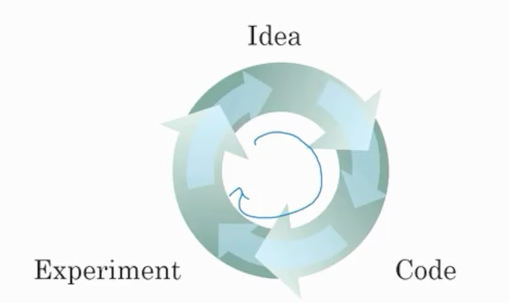
深度学习开发循环
第2课:深度学习中的矢量化
在上这门课之前,我没有意识到一个神经网络可以在没有任何明确的循环的情况下实现(除了层之间)。吴恩达在表达Python中一个矢量化代码设计的重要性方面做得非常出色。课程中的作业为你提供了一个样板化的代码设计,你可以轻松地将其转移到你自己的应用程序中。
第3课:对深度神经网络的深刻理解
第1课的方法实际上是让你从头开始实现numpy中的正向和反向的传播步骤。通过这样做,你可以对诸如TensorFlow和Keras等高级框架的内部工作原理有了更深入的了解。吴恩达解释了一个计算图背后的想法,这让大家可以更容易理解TensorFlow是如何执行“神奇的优化”的。
第4课:为什么要深度?
吴恩达对深度神经网络的分层方面有一个直观的理解。例如,在人脸检测方面,他解释道,先处理的层用于将面部的边缘集合,其后的层用于将这些边缘识别为面部组件(如鼻子、眼睛、嘴巴等等),然后更进一步的层用于把面部组件聚集到一起识别人的身份。吴恩达还解释了“电路理论”的概念,这个理论基本上描述了:一些存在的函数,需要一个指数级的隐藏单元来匹配一个浅网络中的数据。指数问题可以通过添加有限数量的额外层来得到缓解。
第5课:处理偏差和方差的工具
吴恩达描述了一个研究人员如何采取相对应的步骤来识别和处理偏差和方差的问题。下面这张图给出了一个系统性的答案:
解决偏差和方差问题的方法
他还提到了偏差和方差之间通常被引用的“权衡(tradeoff)”。他解释说,在现代的深度学习时代,我们有分别处理每一个问题的工具,这样就不再存在这种权衡。
第6课:正则化
为什么在成本函数中加入一个惩罚项会减少方差效应呢? 在上这门课之前,我认为的是它迫使权重矩阵更接近于零,产生一个更“线性”的函数。但是,吴恩达给出了另一种涉及tanh激活函数的解释:较小的权重矩阵产生较小的输出,它将输出集中围绕在tanh函数的线性区域上。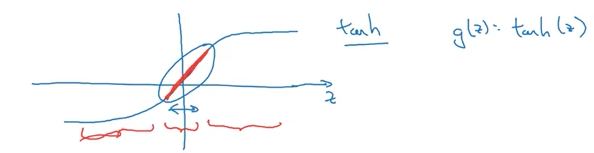
tanh 激活函数
他还对dropout给出了一个有趣的解释。在上这门课之前,我认为dropout基本上是在每次迭代中杀死随机的神经元,所以就像越小的网络线性程度就越强一样。吴恩达却认为应该从一个神经元的角度来看待生命。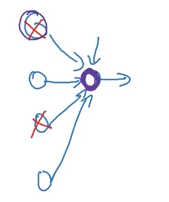
单个神经元的角度
由于dropout随机地杀死了连接,神经元被鼓励在其父系神经元中更均匀地分布它的权重。通过扩散权重,它可以减少权重的 平方范数(squared norm)的收缩效果。他还解释说,dropout只不过是L2正则化的一种适应性形式,这两种方法都有相似的效果。
第7课:为什么要将工作标准化?
通过绘制等高线图,吴恩达描述了为什么标准化倾向于提高优化过程的速度。他明确地举例说明了一个在标准化和非标准化等高线图上的梯度下降例子。
第8课:初始化的重要性
吴恩达表示,参数的初始化可能会导致梯度的消失或爆炸。他演示了几个程序来解决这些问题。基本思想是确保每一层的权重矩阵都有一个大约为1的方差。他还讨论了用于tanh激活函数的Xavier初始化。
第9课:为什么使用小批量梯度下降法?
通过使用等高线图,吴恩达解释了小批量和大批量训练之间的权衡。基本的原则是,一个较大的批量会使每一次迭代变慢,而较小的批量能加快进展,但不能对收敛效果做出相同的保证。最好的方法是在两者之间做一些使你能够更快地取得进展的事情,而不是立刻处理整个数据集。这种方法同时还利用了矢量化技术。
第10课:对高级优化技术的理解
吴恩达解释了像动量(momentum)和RMSprop这样的技术是如何允许梯度下降控制它的路径逼近最小值的。他还对这个过程给出了一个很好的物理解释(球滚下了山坡)。他把这些方法联系起来解释了著名的亚当(Adam)优化。
第11课:基本的TensorFlow后端理解
吴恩达解释了如何使用TensorFlow实现神经网络,并解释了一些在优化过程中使用的后端过程。课程中的一项作业鼓励你使用TensorFlow来实现dropout和L2正则化。这进一步增强了大家对后端进程的理解。
第12课:正交化
吴恩达论述了正交化在机器学习策略中的重要性。基本的原则是,我们希望实现那些只影响算法性能的单一组件的控制。例如,为了解决偏差问题,你可以使用更大的网络或更鲁棒的优化技术。我们希望这些控制只会影响偏差,而不是其他问题,比如泛化。一个缺乏正交性的控制的例子是提前停止优化过程(早期停止)。这是因为它同时影响了模型的偏差和方差。
第13课:单一数字(single number)评估指标的重要性
吴恩达强调选择一个单一数字评估指标来评估你的算法的重要性。如果你的目标发生了变化,那么你应该在模型开发过程中较晚地更改评估指标。吴恩达给出了一个在猫咪分类应用中识别色情图片的例子。
第14课:测试/开发分布
始终确保开发集和测试集具有相同的分布。这确保了你在迭代过程中瞄准了正确的目标。这也意味着,如果你决定在测试集中纠正错误的数据,那么你还必须更正开发集中的错误标签数据。
第15课:处理不同的训练和测试/开发分布
吴恩达给出了为什么我们对在训练集和测试集/开发集没有相同的分布这个问题感兴趣的原因。他的想法是,因为你希望评估指标能在你真正关心的实例中计算出来。例如,你可能希望使用与你的问题不相关的示例,但是你不希望你的算法对这些示例进行评估。这使得你的算法能够得到更多的数据。从经验上看,这种方法在很多情况下会给你带来更好的性能。缺点是你的训练集和测试集/开发集有不同的分布。解决的办法是,在你的训练集里留下一小部分,并确定训练集的泛化能力。然后,你可以将这个误差率与实际的开发误差进行比较,并计算一个“数据不匹配”度量。吴恩达接下来解释了解决数据不匹配问题的方法,例如人工数据合成。
第16课:训练集/开发集/测试集大小
在深度学习的时代,设置训练集/开发集/测试集的分割(split)的指导方针已经发生了巨大的变化。在上这门课之前,我通常知道的是60/20/20的分割。吴恩达强调,对于一个非常大的数据集,你应该使用大约98/1/1,甚至是99/0.5/0.5的分割。这是因为开发集和测试集只需要足够大能确保团队提供的置信区间即可。如果你正在使用1000万个训练示例,那么可能100,000个示例(或1%的数据)就足够可以保证你的开发集和/或测试集的置信区间了。
第17课:近似贝叶斯最优误差
吴恩达解释了在某些应用中,人类的等级性能如何被用来作为贝叶斯误差的替代物。例如,对于像视觉和音频识别这样的任务,人类的水平误差将非常接近贝叶斯误差。这使你能够量化你的模型所具有的可避免偏差的数量。如果没有像贝叶斯这样的基准,就很难理解你的网络中存在的方差和可避免的偏差问题。
第18课:误差分析
吴恩达展示了一种很明显的技术,可以通过误差分析极大地提高算法性能的有效性。基本的想法是手动给你的错误分类的例子进行标注,并把你的精力集中在误差上,这是造成你错误分类数据的最大来源。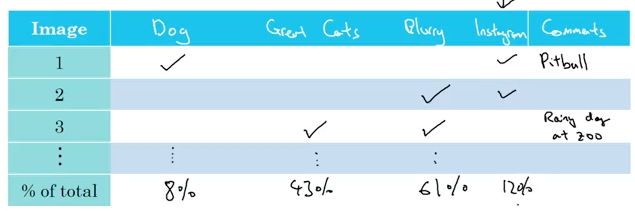
猫咪识别应用误差分析
例如,在猫咪识别中,吴恩达判断模糊的图像对误差的影响最大。这种敏感性分析可以让你看到你的努力在减少总误差方面有多大价值。还有一种可能是,修复模糊的图像是一项极其艰巨的任务,而其他的误差则是显而易见并且易于修复的。在决策过程中,敏感性和近似的工作都会被考虑进去。
第19课:什么时候使用迁移学习?
迁移学习允许你将知识从一个模型转移到另一个模型。例如,你可以将图像识别知识从猫识别应用转移到放射诊断。实现迁移学习要对网络的最后几层进行再次训练,用于相似的带有更多数据的应用领域。迁移学习的想法是,在网络早期的隐藏单元有一个更广泛的应用,它通常不针对你使用网络的具体任务。总而言之,当两个任务都有相同的输入特性,并且当你想要学习的任务比你要训练的任务有更多的数据时,迁移学习就会起作用。
第20课:何时使用多任务学习?
多任务学习迫使单个神经网络同时学习多个任务(而不是为每个任务建立一个单独的神经网络)。吴恩达解释说,当一组任务可以从共享的低级别特性中受益,并且当每个任务的数据量大小相似时,这种方法可以很好地工作。
第21课:什么时候使用端到端深度学习?
端到端深度学习需要多个阶段的处理,并将它们组合成一个单一的神经网络。这使得数据能在没有人工设计步骤引进偏差的前提下自主进行优化过程。相反,这种方法需要更多的数据,并且可能排除潜在的手工设计的组件。
Deeplearning.ai课程地址:https://www.coursera.org/specializations/deep-learning









