











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






TensorFlow实践教程:使用神经网络对犬种进行图像识别分类
2017年11月09日 由 xiaoshan.xiang 发表
450899
0

问题
几天前,我注意到由Kaggle主办的犬种识别挑战赛。我们的目标是建立一个模型,能够通过“观察”图像来进行犬种分类。我开始考虑可能的方法来建立一个模型来对犬种进行分类,以及了解该模型可能达到的精度。在现代机器学习框架中,像TensorFlow,公开可用的数据集和预先训练的图像识别模型,可以在不应用过多的工作和花费过多的时间和资源的情况下,以相当好的准确性解决问题。我将分享使用TensorFlow构建犬种分类器的端到端流程。
repo包含了使用经过训练的模型进行训练和运行推断所需的一切。
repo地址:https://github.com/stormy-ua/dog-breeds-classification
训练数据集
拥有一个良好的培训数据集是向健壮的模型迈出的一大步。斯坦福的犬种数据集有20K图像,包含120个品种的狗。数据集里的每一个图像都标注了狗的品种。你可能已经注意到了,只有20K张的120个不同品种的图像(每品种200个图像)不足以训练一个深度神经网络。卷积神经网络(CNN)是图像分类中最好的机器学习模型,但在这种情况下,没有足够的训练实例来训练它。它将无法从这个数据集上学习到足够通用的模式来对不同的犬种进行分类。最可能的是,它会过度拟合这些少量的训练示例,这样测试集的精确度就会降低。有两种可能的方法来减缓训练示例缺乏的情况:
- 将犬种图像数据集与另一个更大的图像数据集(如ImageNet),并在合并的例子上训练CNN;
- 在更大的数据集上接受预先训练的深层神经网络,切入它,附加一个额外的“分类头[classification head]”,即带有Softmax的几个额外的完全连接的层。
第一种方法有两大缺点:需要分析大量的数据,而这个大数据集的训练将花费更多的时间和资源。第二种方法似乎更可行:训练必须在原始数据集上执行,并且训练的“分类头[classification head]”只有几个完全连接的层,不需要大量的时间和资源。
训练将“分类头[classification head]”连接在一个较小数据集上的预训练的模型的方法叫做转移学习。
转移学习发挥作用是因为CNNs的工作原理。有相当多的资源描述了工作原理的细节,例如http://cs231n.stanford.edu/。简而言之,在一个大数据集上训练的深层神经网络的底层,以捕获了图像的低级原语[low-level primitives](例如轮廓和简单的形状),这样所有的图像都是通用的,并且可以被“转移”到任何图像识别问题。
神经网络模型
最终的神经网络模型如下:
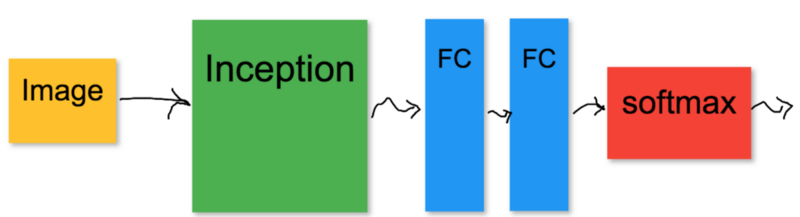
图像被送入初始[Inception]模型。初始[Inception]模型的输出通过几个完全连接的(FC)层,最后,softmax输出图像的概率属于每个类。只有FC层代表的“分类头[classification head]”必须接受训练。初始模型使用已预定义的模型参数保持冻结。
下载并准备数据
下一个步骤是下载犬种数据集和预先训练的谷歌初始[Inception]模型。从repo的根目录执行setup / setup.sh脚本将下载所有内容,解压缩并放入适当的目录中。下载和提取的数据集是一组文件夹,其中包含单独文件中的图像和注释。TensorFlow有一个数据集API,它使用TF记录数据格式可以更好地工作。它的工作原理是将所有的训练示例和它们的注释放在一个文件中,其中所有的例子都存储为protobuf序列化格式。在使用最小磁盘I / O操作和内存需求的训练过程中,TensorFlow数据集API可以有效地使用这种数据格式,并加载尽可能多的示例。有一个python脚本将原始的狗数据集转换为TF记录文件,准备用于训练:
setup / setup.sh地址:https://github.com/stormy-ua/dog-breeds-classification/blob/master/setup/setup.sh
数据集API地址:https://www.tensorflow.org/versions/r1.4/programmers_guide/datasets
python脚本地址:https://github.com/stormy-ua/dog-breeds-classification/blob/master/src/data_preparation/stanford_ds_to_tfrecords.py
python -m src.data_preparation.stanford_ds_to_tfrecords
它必须从repo的根目录执行。转换数据集需要大约1小时。每个映像都被输入到初始[Inception]模型,并将其带有图像的输出与和其他注释存储在一起。这简化了训练,因为我们不需要在培训期间为每个示例计算初始输出,而是预先计算以备使用。结果TF记录文件位于data/stanford.tfrecords中。setup.sh脚本还下载并提取谷歌的初始模型,将其表示为冻结的TensorFlow图。冻结意味着所有变量都被常量替换,并嵌入到图形本身中,这样就不需要携带检查点文件和图形,以便将模型加载到TensorFlow会话中并开始使用它。初始模型可以在frozen/inception/classify_image_graph_def.pb中获得。
训练
下一步是执行训练。首先,为模型提供一个独特的名称。其次,应该配置一些完全连接的层和这些层中的单元数。可以在src/common/consts.py模块中配置。
src/common/consts.py模块地址:https://github.com/stormy-ua/dog-breeds-classification/blob/master/src/common/consts.py
CLASSES_COUNT = 120
INCEPTION_CLASSES_COUNT = 2048
# name of the model being referenced by all other scripts
CURRENT_MODEL_NAME = 'stanford_5_64_0001'
# sets up number of layers and number of units in each layer for
# the "head" dense neural network stacked on top of the Inception
# pre-trained model.
HEAD_MODEL_LAYERS = [INCEPTION_CLASSES_COUNT, 1024, CLASSES_COUNT]
默认情况下,有2个完全连接的层,分别带有1024个单元和120个单元。而输入层有2048个单元,与初始模型最后一层的单元数相同。
用src/training/train.py训练,学习率、epochs的数量和小批量的大小可以在该脚本中配置。
src/training/train.py地址:https://github.com/stormy-ua/dog-breeds-classification/blob/master/src/training/train.py
python -m src.training.train
除此之外,TensorBoard还可以开始训练监测。
TensorBoard地址:https://www.tensorflow.org/get_started/summaries_and_tensorboard
tensorboard --logdir=./summary
有三个度量指标:成本、测试集的误差和训练集的误差。默认情况下,计算训练集中的3000个示例的误差率,并计算包含3000个示例的测试集的误差率。我用以下超参数训练了模型:
- 小批量的大小=64
- 学习率=0.0001
- Epoch数量=5000
以下是我在TensorBoard中得到的关于这三个指标的数据:
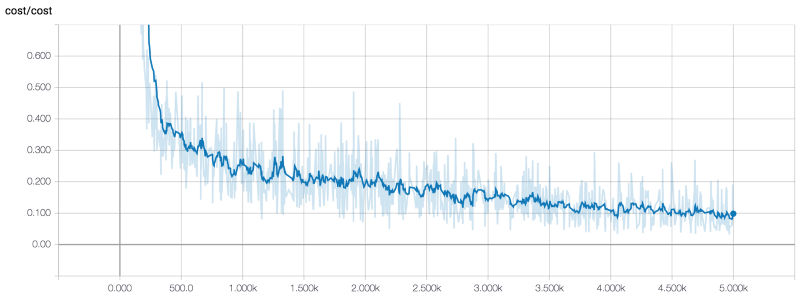
成本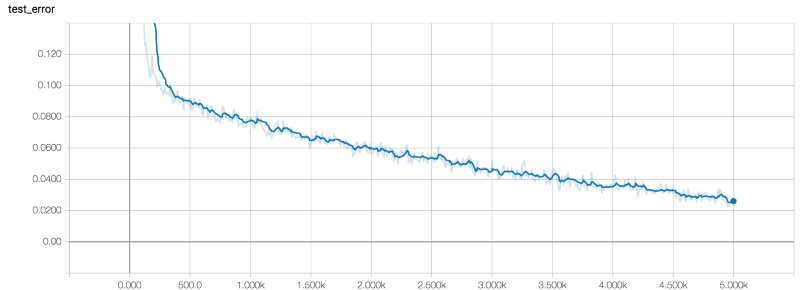
测试集的误差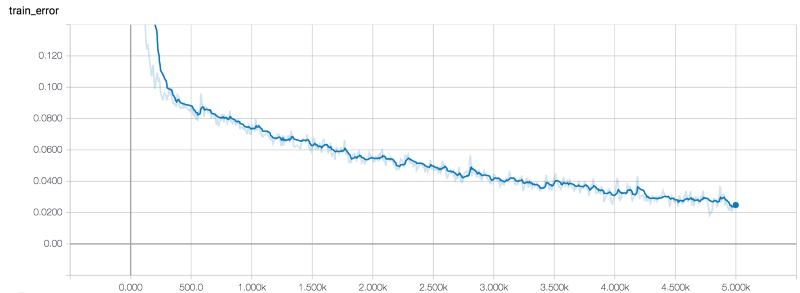
训练集样本的误差
用大约1小时执行5K个epochs。训练结束后,指标有以下值:
- 成本=0.1
- 测试误差2.7%
- 训练误差=2.5%
在测试和训练集上两个误差都很低,而且两个误差大致相同,所以训练集没有严重的过度适合的症状。
冻结模型
一旦模型被训练,它的优化参数就存储在./checkpoints dir的检查点文件中。为了有效地重新利用模型进行推理,将其作为一个具有将参数嵌入到图形本身的冻结TensorFlow图形是很好的。可以使用src/freezing/freezy.py进行此操作:
src/freezing/freezy.py地址:https://github.com/stormy-ua/dog-breeds-classification/blob/master/src/freezing/freeze.py
python -m src.freezing.freeze
此脚本按以下顺序执行几项操作:
- 将初始模型和“分类头[classification head]”模型加载到相同的TensorFlow会话中,并将它们绑定在一起,形成一个单一的计算图形,以便初始模型的输出直接进入“分类头[classification head]”模型的输入。一旦绑定完成,脚本将在文件系统的图形中序列化复合模型。在这一点上,图形还没有被冻结,因为在训练过程中计算的模型参数仍然处于检查点文件中。
- 使用TensorFlow freeze_graph函数冻结在前一步中生成的图形。它从检查点文件中提取模型参数并将它们注入到图形变量中。图形变量转换为常数。生成的文件将到名为模型的./frozen目录。
freeze_graph函数地址:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/freeze_graph.py#L206
推理
一旦冻结模型准备好,就可以用于对任意图像进行分类。src/inference/classify.py脚本可以将存储在文件系统上或者可用的狗的图像归类为HTTP资源。在幕后,它加载冻结图形并将图像输入其中。以下是关于 Airedale Terrie和Shih-Tzu的推理工作的两个例子:

python -m src.inference.classify file images/airedale.jpg
breed prob
airedale 0.979627
otterhound 0.009855
irish_terrier 0.007160
chesapeake_bay_retriever 0.001507
wire-haired_fox_terrier 0.000824

python -m src.inference.classify uri https://raw.githubusercontent.com/stormy-ua/dog-breeds-classification/master/images/shih-tzu.jpg
breed prob
shih-tzu 0.669201
lhasa 0.319596
tibetan_terrier 0.005996
japanese_spaniel 0.001398
pekinese 0.000928
如果你想知道推理是如何工作的,那就需要有一个docker容器,它包含所有的代码和冻结模型。它公开Python的笔记本进行推断。实际上,它甚至在docker容器内完成了所有的工作。可以使用以下命令启动容器:
docker容器地址:https://hub.docker.com/r/kirillpanarin/dog_breed_classification/
docker run -p 8888:8888 -p 6006:6006 kirillpanarin/dog_breed_classification
一旦容器开始,导航到浏览器http://localhost:8888/notebooks/Inference.ipynb,你就可以使用自己的图像分类器了。
误差分析
更仔细地研究一个机器学习模型未能正确分类的例子是一个好想法。脚本src/analysis/training_perf_analysis.py生成预测的CSV文件(它用于metrics/training_confusion.csv),并为所有训练示例提供实际的品种。
src/analysis/training_perf_analysis.py脚本地址:https://github.com/stormy-ua/dog-breeds-classification/blob/master/src/analysis/training_perf_analysis.py
通过加载training_confusion的数据,csv可以绘制混淆矩阵:
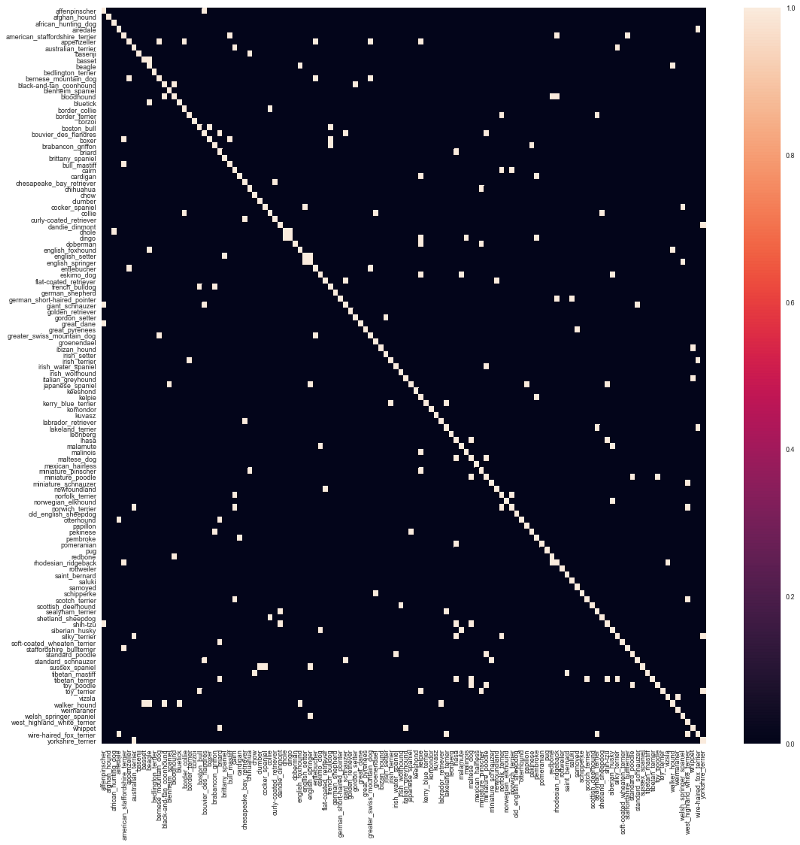
由于狗的品种太多,很难在这里进行详细的分析。让我们试着分析前30个误分类的品种(Confusion.ipynb中提供了一个例子):
Confusion.ipynb地址:https://github.com/stormy-ua/dog-breeds-classification/blob/master/Confusion.ipynb
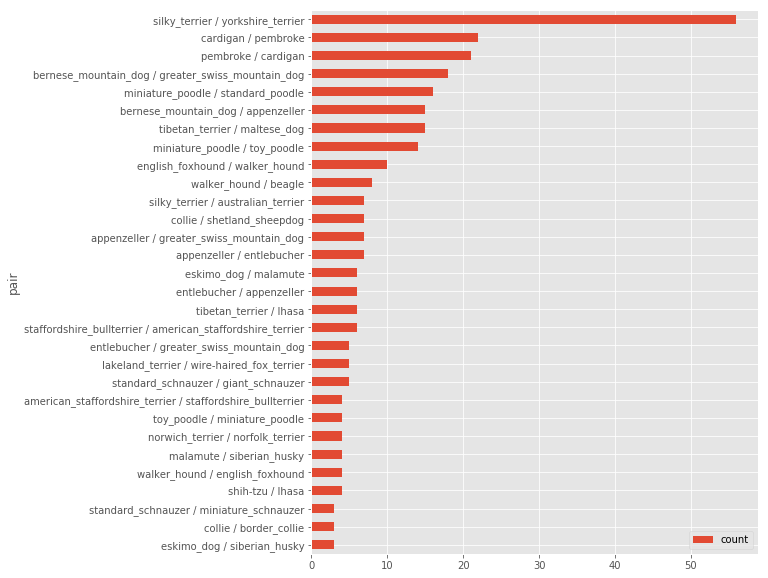
正如所看到的,“丝质小猎犬”和“约克郡犬”误分类的概率上是最高的,如果我们研究一下这两种狗的样子,就会觉得很有道理。

约克郡犬

丝质小猎犬
看起来丝质小猎犬和约克郡犬经常被人混淆。更多细节在本篇文章中。
文章地址:https://www.cuteness.com/article/difference-between-yorkie-silky-terrier
你是一个爱狗的人吗?
如果你认为自己是一个爱狗的人,你可以继续问问你的模型下图中的狗是什么品种:)在我的情况下,我得到了以下答案:
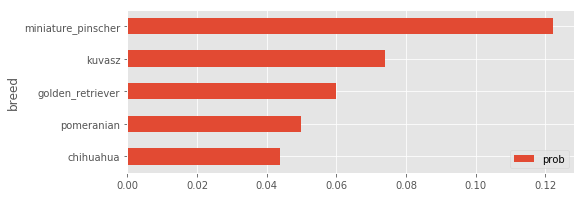

迷你品犬
结论
正如我们所看到的那样,即使没有足够的训练图像和/或计算资源,如果你可以使用预训练的深层神经网络和现代机器学习库(如TensorFlow),也可以训练一个强大的图像分类器。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消