

















数据集:
GroNLP/divemt
任务:
 翻译
翻译

计算机处理:
translation大小:
1K<n<10K语言创建人:
found源数据集:
original预印本库:
arxiv:2205.12215许可:
 gpl-3.0
gpl-3.0
 英文
英文DivEMT数据集的数据卡
有关DivEMT的更多详细信息,请参阅我们的 EMNLP 2022 Paper 和我们的 Github repository
Gabriele Sarti • Arianna Bisazza • Ana Guerberof Arenas • Antonio Toral
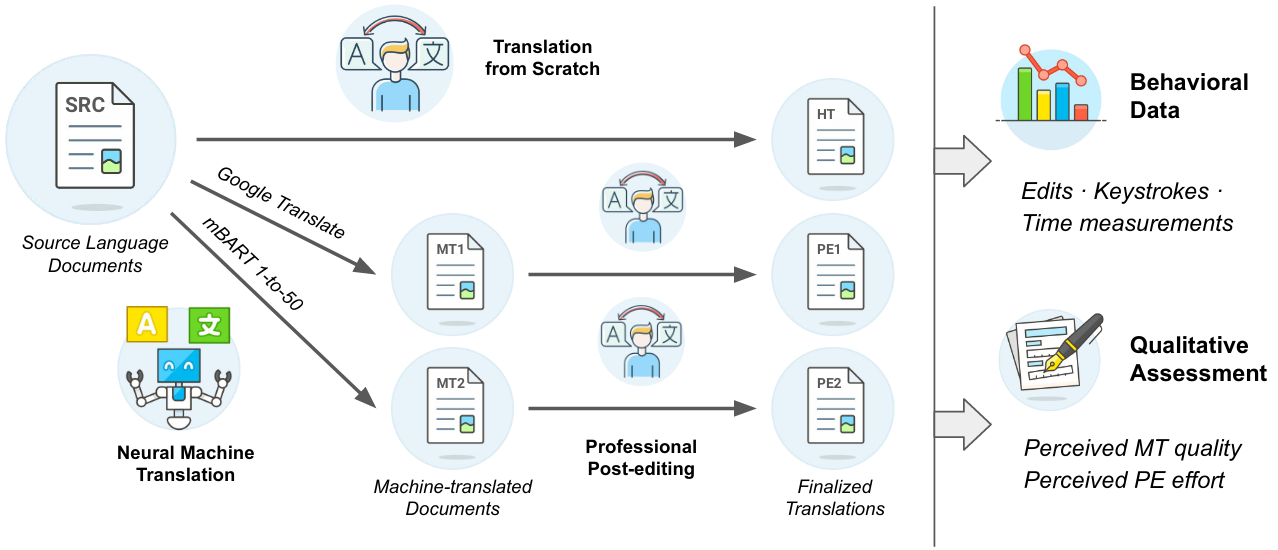
我们介绍了DivEMT,这是一个在目标语言上逐渐多样化的语言背景下首次公开可用的神经机器翻译(NMT)的后编辑研究。在一个严格控制的设置中,我们指示18名专业翻译对同一套英语文档进行阿拉伯语、荷兰语、意大利语、土耳其语、乌克兰语和越南语的翻译或后编辑。在这个过程中,记录了他们的编辑、按键、编辑时间和暂停,从而能够深入、跨语言地评估NMT质量和后编辑的有效性。使用这个新数据集,我们评估了两个最先进的NMT系统,Google翻译和多语种mBART-50模型,对翻译生产效率的影响。我们发现后编辑比从头开始翻译要快。然而,不同系统和语言的生产力增益的大小差异很大,在控制系统架构和训练数据大小的情况下,凸显了对不同与英语的语言的后编辑有效性存在重大差异的问题。我们公开发布了包含所有收集到的行为数据的完整数据集,以促进对各种语言的NMT系统翻译能力的新研究。
数据集摘要
该数据集包含DivEMT数据集的预处理以及主要拆分(warmup和main)。从Flores-101语料库中提取了一些文档,并由总共18名专业翻译人员将其从头翻译或从现有的自动翻译中进行后编辑,涵盖了六种类型多样的语言(阿拉伯语、荷兰语、意大利语、土耳其语、乌克兰语和越南语)。在翻译过程中,使用 PET 平台收集了行为数据(按键、暂停、编辑时间)。我们公开发布了包含所有收集到的行为数据的处理后的数据集,以促进关于最先进的NMT系统在多样化语言中生成文本能力的新研究。
新闻🎉
2023年2月:DivEMT数据集现在包含通过Stanza计算的语言注释(*_annotations字段)和使用与WMT22质量估计任务2相同脚本获得的单词级质量估计标签(src_wmt22_qe,mt_wmt22_qe)。
语言
DivEMT的语言数据包括英语(BCP-47 en)、意大利语(BCP-47 it)、荷兰语(BCP-47 nl)、阿拉伯语(BCP-47 ar)、土耳其语(BCP-47 tr)、乌克兰语(BCP-47 uk)和越南语(BCP-47 vi)
数据集结构
数据实例
该数据集包含两个配置:main和warmup。main包含在主任务期间收集并在我们的实验中进行分析的全部数据。warmup包含在主任务开始之前在验证阶段收集的数据。
数据字段
训练集中包含以下字段:
| Field | Description |
|---|---|
| unit_id | The full entry identifier. Format: flores101-{config}-{lang}-{doc_id}-{modality}-{sent_in_doc_num} |
| flores_id | Index of the sentence in the original 1239321 dataset |
| item_id | The sentence identifier. The first digits of the number represent the document containing the sentence, while the last digit of the number represents the sentence position inside the document. Documents can contain from 3 to 5 contiguous sentences each. |
| subject_id | The identifier for the translator performing the translation from scratch or post-editing task. Values: t1 , t2 or t3 . |
| lang_id | Language identifier for the sentence, using Flores-101 three-letter format (e.g. ara , nld ) |
| doc_id | Document identifier for the sentence |
| task_type | The modality of the translation task. Values: ht (translation from scratch), pe1 (post-editing Google Translate translations), pe2 (post-editing 12310321 translations). |
| translation_type | Either ht for from scratch or pe for post-editing |
| src_len_chr | Length of the English source text in number of characters |
| mt_len_chr | Length of the machine translation in number of characters (NaN for ht) |
| tgt_len_chr | Length of the target text in number of characters |
| src_len_wrd | Length of the English source text in number of words |
| mt_len_wrd | Length of the machine translation in number of words (NaN for ht) |
| tgt_len_wrd | Length of the target text in number of words |
| edit_time | Total editing time for the translation in seconds. |
| k_total | Total number of keystrokes for the translation. |
| k_letter | Total number of letter keystrokes for the translation. |
| k_digit | Total number of digit keystrokes for the translation. |
| k_white | Total number of whitespace keystrokes for the translation. |
| k_symbol | Total number of symbol (punctuation, etc.) keystrokes for the translation. |
| k_nav | Total number of navigation keystrokes (left-right arrows, mouse clicks) for the translation. |
| k_erase | Total number of erase keystrokes (backspace, cancel) for the translation. |
| k_copy | Total number of copy (Ctrl + C) actions during the translation. |
| k_cut | Total number of cut (Ctrl + X) actions during the translation. |
| k_paste | Total number of paste (Ctrl + V) actions during the translation. |
| k_do | Total number of Enter actions during the translation. |
| n_pause_geq_300 | Number of pauses of 300ms or more during the translation. |
| len_pause_geq_300 | Total duration of pauses of 300ms or more, in milliseconds. |
| n_pause_geq_1000 | Number of pauses of 1s or more during the translation. |
| len_pause_geq_1000 | Total duration of pauses of 1000ms or more, in milliseconds. |
| event_time | Total time summed across all translation events, should be comparable to edit_time in most cases. |
| num_annotations | Number of times the translator focused the textbox for performing the translation of the sentence during the translation session. E.g. 1 means the translation was performed once and never revised. |
| n_insert | Number of post-editing insertions (empty for modality ht ) computed using the 12311321 library. |
| n_delete | Number of post-editing deletions (empty for modality ht ) computed using the 12311321 library. |
| n_substitute | Number of post-editing substitutions (empty for modality ht ) computed using the 12311321 library. |
| n_shift | Number of post-editing shifts (empty for modality ht ) computed using the 12311321 library. |
| tot_shifted_words | Total amount of shifted words from all shifts present in the sentence. |
| tot_edits | Total of all edit types for the sentence. |
| hter | Human-mediated Translation Edit Rate score computed between MT and post-edited TGT (empty for modality ht ) using the 12311321 library. |
| cer | Character-level HTER score computed between MT and post-edited TGT (empty for modality ht ) using 12316321 . |
| bleu | Sentence-level BLEU score between MT and post-edited TGT (empty for modality ht ) computed using the 12317321 library with default parameters. |
| chrf | Sentence-level chrF score between MT and post-edited TGT (empty for modality ht ) computed using the 12317321 library with default parameters. |
| time_s | Edit time expressed in seconds. |
| time_m | Edit time expressed in minutes. |
| time_h | Edit time expressed in hours. |
| time_per_char | Edit time per source character, expressed in seconds. |
| time_per_word | Edit time per source word, expressed in seconds. |
| key_per_char | Proportion of keys per character needed to perform the translation. |
| words_per_hour | Amount of source words translated or post-edited per hour. |
| words_per_minute | Amount of source words translated or post-edited per minute. |
| per_subject_visit_order | Id denoting the order in which the translator accessed documents. 1 correspond to the first accessed document. |
| src_text | The original source sentence extracted from Wikinews, wikibooks or wikivoyage. |
| mt_text | Missing if tasktype is ht . Otherwise, contains the automatically-translated sentence before post-editing. |
| tgt_text | Final sentence produced by the translator (either via translation from scratch of sl_text or post-editing mt_text ) |
| aligned_edit | Aligned visual representation of REF ( mt_text ), HYP ( tl_text ) and edit operations (I = Insertion, D = Deletion, S = Substitution) performed on the field. Replace \\n with \n to show the three aligned rows. |
| src_tokens | List of tokens obtained tokenizing src_text with Stanza using default params. |
| src_annotations | List of lists (one per src_tokens token) containing dictionaries (one per word, >1 for mwt) with pos, ner and other info parsed by Stanza |
| mt_tokens | List of tokens obtained tokenizing mt_text with Stanza using default params. |
| mt_annotations | List of lists (one per mt_tokens token) containing dictionaries (one per word, >1 for mwt) with pos, ner and other info parsed by Stanza |
| tgt_tokens | List of tokens obtained tokenizing tgt_text with Stanza using default params. |
| tgt_annotations | List of lists (one per tgt_tokens token) containing dictionaries (one per word, >1 for mwt) with pos, ner and other info parsed by Stanza |
数据拆分
训练拆分包含在翻译过程中产生的带有行为数据的三元组(或从头开始翻译时的对)。
以下是从土耳其语的训练拆分中提取的由专业翻译t1对由Google翻译生成的机器翻译(task_type pe1)进行后编辑的示例。字段aligned_edit显示为三行,以便更好地理解其内容。
{
'unit_id': 'flores101-main-tur-46-pe1-3',
'flores_id': 871,
'item_id': 'flores101-main-463',
'subject_id': 'tur_t1',
'task_type': 'pe1',
'translation_type': 'pe',
'src_len_chr': 109,
'mt_len_chr': 129.0,
'tgt_len_chr': 120,
'src_len_wrd': 17,
'mt_len_wrd': 15.0,
'tgt_len_wrd': 13,
'edit_time': 11.762999534606934,
'k_total': 31,
'k_letter': 9,
'k_digit': 0,
'k_white': 0,
'k_symbol': 0,
'k_nav': 20,
'k_erase': 2,
'k_copy': 0,
'k_cut': 0,
'k_paste': 0,
'k_do': 0,
'n_pause_geq_300': 2,
'len_pause_geq_300': 4986,
'n_pause_geq_1000': 1,
'len_pause_geq_1000': 4490,
'event_time': 11763,
'num_annotations': 2,
'last_modification_time': 1643569484,
'n_insert': 0.0,
'n_delete': 2.0,
'n_substitute': 1.0,
'n_shift': 0.0,
'tot_shifted_words': 0.0,
'tot_edits': 3.0,
'hter': 20.0,
'cer': 0.10,
'bleu': 0.0,
'chrf': 2.569999933242798,
'lang_id': 'tur',
'doc_id': 46,
'time_s': 11.762999534606934,
'time_m': 0.1960500031709671,
'time_h': 0.0032675000838935375,
'time_per_char': 0.1079174280166626,
'time_per_word': 0.6919412016868591,
'key_per_char': 0.2844036817550659,
'words_per_hour': 5202.75439453125,
'words_per_minute': 86.71257019042969,
'per_subject_visit_order': 201,
'src_text': 'As one example, American citizens in the Middle East might face different situations from Europeans or Arabs.',
'mt_text': "Bir örnek olarak, Orta Doğu'daki Amerikan vatandaşları, Avrupalılardan veya Araplardan farklı durumlarla karşı karşıya kalabilir.",
'tgt_text': "Örneğin, Orta Doğu'daki Amerikan vatandaşları, Avrupalılardan veya Araplardan farklı durumlarla karşı karşıya kalabilir.",
'aligned_edit': "REF: bir örnek olarak, orta doğu'daki amerikan vatandaşları, avrupalılardan veya araplardan farklı durumlarla karşı karşıya kalabilir.\\n
HYP: *** ***** örneğin, orta doğu'daki amerikan vatandaşları, avrupalılardan veya araplardan farklı durumlarla karşı karşıya kalabilir.\\n
EVAL: D D S"
}
文本按原样提供,没有进一步的预处理或分词。
数据集创建
使用 DivEMT Github repository 中的脚本将数据集从PET XML文件解析为CSV格式。
这些脚本是通过 Antonio Toral 的脚本进行调整的,该脚本可在以下链接中找到: https://github.com/antot/postediting_novel_frontiers 。
其他信息
数据集策划者
有关与此🤗数据集版本相关的问题,请通过g.sarti@rug.nl与我联系。
引用信息
@inproceedings{sarti-etal-2022-divemt,
title = "{D}iv{EMT}: Neural Machine Translation Post-Editing Effort Across Typologically Diverse Languages",
author = "Sarti, Gabriele and
Bisazza, Arianna and
Guerberof-Arenas, Ana and
Toral, Antonio",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.532",
pages = "7795--7816",
}