

















数据集:
GroNLP/divemt
任务:
 翻译
翻译

计算机处理:
translation大小:
1K<n<10K语言创建人:
found源数据集:
original预印本库:
arxiv:2205.12215许可:
 gpl-3.0
gpl-3.0
 中文
中文Dataset Card for DivEMT
For more details on DivEMT, see our EMNLP 2022 Paper and our Github repository
Gabriele Sarti • Arianna Bisazza • Ana Guerberof Arenas • Antonio Toral
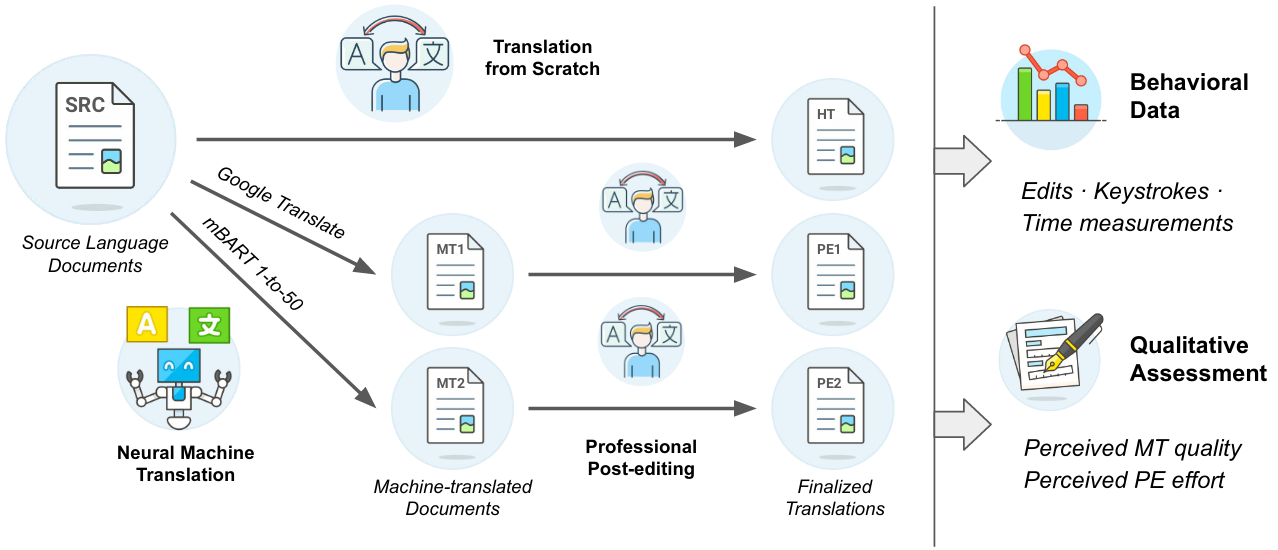
We introduce DivEMT, the first publicly available post-editing study of Neural Machine Translation (NMT) over a typologically diverse set of target languages. Using a strictly controlled setup, 18 professional translators were instructed to translate or post-edit the same set of English documents into Arabic, Dutch, Italian, Turkish, Ukrainian, and Vietnamese. During the process, their edits, keystrokes, editing times and pauses were recorded, enabling an in-depth, cross-lingual evaluation of NMT quality and post-editing effectiveness. Using this new dataset, we assess the impact of two state-of-the-art NMT systems, Google Translate and the multilingual mBART-50 model, on translation productivity. We find that post-editing is consistently faster than translation from scratch. However, the magnitude of productivity gains varies widely across systems and languages, highlighting major disparities in post-editing effectiveness for languages at different degrees of typological relatedness to English, even when controlling for system architecture and training data size. We publicly release the complete dataset including all collected behavioral data, to foster new research on the translation capabilities of NMT systems for typologically diverse languages.
Dataset Summary
This dataset contains the processed warmup and main splits of the DivEMT dataset. A sample of documents extracted from the Flores-101 corpus were either translated from scratch or post-edited from an existing automatic translation by a total of 18 professional translators across six typologically diverse languages (Arabic, Dutch, Italian, Turkish, Ukrainian, Vietnamese). During the translation, behavioral data (keystrokes, pauses, editing times) were collected using the PET platform.
We publicly release the processed dataset including all collected behavioural data, to foster new research on the ability of state-of-the-art NMT systems to generate text in typologically diverse languages.
News ?
February, 2023 : The DivEMT dataset now contains linguistic annotations ( *_annotations fields) computed with Stanza and word-level quality estimation tags ( src_wmt22_qe , mt_wmt22_qe ) obtained using the same scripts adopted for the WMT22 QE Task 2.
Languages
The language data of DivEMT is in English (BCP-47 en ), Italian (BCP-47 it ), Dutch (BCP-47 nl ), Arabic (BCP-47 ar ), Turkish (BCP-47 tr ), Ukrainian (BCP-47 uk ) and Vietnamese (BCP-47 vi )
Dataset Structure
Data Instances
The dataset contains two configurations: main and warmup . main contains the full data collected during the main task and analyzed during our experiments. warmup contains the data collected in the verification phase, before the main task begins.
Data Fields
The following fields are contained in the training set:
| Field | Description |
|---|---|
| unit_id | The full entry identifier. Format: flores101-{config}-{lang}-{doc_id}-{modality}-{sent_in_doc_num} |
| flores_id | Index of the sentence in the original Flores-101 dataset |
| item_id | The sentence identifier. The first digits of the number represent the document containing the sentence, while the last digit of the number represents the sentence position inside the document. Documents can contain from 3 to 5 contiguous sentences each. |
| subject_id | The identifier for the translator performing the translation from scratch or post-editing task. Values: t1 , t2 or t3 . |
| lang_id | Language identifier for the sentence, using Flores-101 three-letter format (e.g. ara , nld ) |
| doc_id | Document identifier for the sentence |
| task_type | The modality of the translation task. Values: ht (translation from scratch), pe1 (post-editing Google Translate translations), pe2 (post-editing mBART 1-to-50 translations). |
| translation_type | Either ht for from scratch or pe for post-editing |
| src_len_chr | Length of the English source text in number of characters |
| mt_len_chr | Length of the machine translation in number of characters (NaN for ht) |
| tgt_len_chr | Length of the target text in number of characters |
| src_len_wrd | Length of the English source text in number of words |
| mt_len_wrd | Length of the machine translation in number of words (NaN for ht) |
| tgt_len_wrd | Length of the target text in number of words |
| edit_time | Total editing time for the translation in seconds. |
| k_total | Total number of keystrokes for the translation. |
| k_letter | Total number of letter keystrokes for the translation. |
| k_digit | Total number of digit keystrokes for the translation. |
| k_white | Total number of whitespace keystrokes for the translation. |
| k_symbol | Total number of symbol (punctuation, etc.) keystrokes for the translation. |
| k_nav | Total number of navigation keystrokes (left-right arrows, mouse clicks) for the translation. |
| k_erase | Total number of erase keystrokes (backspace, cancel) for the translation. |
| k_copy | Total number of copy (Ctrl + C) actions during the translation. |
| k_cut | Total number of cut (Ctrl + X) actions during the translation. |
| k_paste | Total number of paste (Ctrl + V) actions during the translation. |
| k_do | Total number of Enter actions during the translation. |
| n_pause_geq_300 | Number of pauses of 300ms or more during the translation. |
| len_pause_geq_300 | Total duration of pauses of 300ms or more, in milliseconds. |
| n_pause_geq_1000 | Number of pauses of 1s or more during the translation. |
| len_pause_geq_1000 | Total duration of pauses of 1000ms or more, in milliseconds. |
| event_time | Total time summed across all translation events, should be comparable to edit_time in most cases. |
| num_annotations | Number of times the translator focused the textbox for performing the translation of the sentence during the translation session. E.g. 1 means the translation was performed once and never revised. |
| n_insert | Number of post-editing insertions (empty for modality ht ) computed using the tercom library. |
| n_delete | Number of post-editing deletions (empty for modality ht ) computed using the tercom library. |
| n_substitute | Number of post-editing substitutions (empty for modality ht ) computed using the tercom library. |
| n_shift | Number of post-editing shifts (empty for modality ht ) computed using the tercom library. |
| tot_shifted_words | Total amount of shifted words from all shifts present in the sentence. |
| tot_edits | Total of all edit types for the sentence. |
| hter | Human-mediated Translation Edit Rate score computed between MT and post-edited TGT (empty for modality ht ) using the tercom library. |
| cer | Character-level HTER score computed between MT and post-edited TGT (empty for modality ht ) using CharacTER . |
| bleu | Sentence-level BLEU score between MT and post-edited TGT (empty for modality ht ) computed using the SacreBLEU library with default parameters. |
| chrf | Sentence-level chrF score between MT and post-edited TGT (empty for modality ht ) computed using the SacreBLEU library with default parameters. |
| time_s | Edit time expressed in seconds. |
| time_m | Edit time expressed in minutes. |
| time_h | Edit time expressed in hours. |
| time_per_char | Edit time per source character, expressed in seconds. |
| time_per_word | Edit time per source word, expressed in seconds. |
| key_per_char | Proportion of keys per character needed to perform the translation. |
| words_per_hour | Amount of source words translated or post-edited per hour. |
| words_per_minute | Amount of source words translated or post-edited per minute. |
| per_subject_visit_order | Id denoting the order in which the translator accessed documents. 1 correspond to the first accessed document. |
| src_text | The original source sentence extracted from Wikinews, wikibooks or wikivoyage. |
| mt_text | Missing if tasktype is ht . Otherwise, contains the automatically-translated sentence before post-editing. |
| tgt_text | Final sentence produced by the translator (either via translation from scratch of sl_text or post-editing mt_text ) |
| aligned_edit | Aligned visual representation of REF ( mt_text ), HYP ( tl_text ) and edit operations (I = Insertion, D = Deletion, S = Substitution) performed on the field. Replace \\n with \n to show the three aligned rows. |
| src_tokens | List of tokens obtained tokenizing src_text with Stanza using default params. |
| src_annotations | List of lists (one per src_tokens token) containing dictionaries (one per word, >1 for mwt) with pos, ner and other info parsed by Stanza |
| mt_tokens | List of tokens obtained tokenizing mt_text with Stanza using default params. |
| mt_annotations | List of lists (one per mt_tokens token) containing dictionaries (one per word, >1 for mwt) with pos, ner and other info parsed by Stanza |
| tgt_tokens | List of tokens obtained tokenizing tgt_text with Stanza using default params. |
| tgt_annotations | List of lists (one per tgt_tokens token) containing dictionaries (one per word, >1 for mwt) with pos, ner and other info parsed by Stanza |
Data Splits
| config | train |
|---|---|
| main | 7740 (107 docs i.e. 430 sents x 18 translators) |
| warmup | 360 (5 docs i.e. 20 sents x 18 translators) |
The train split contains the totality of triplets (or pairs, when translation from scratch is performed) annotated with behavioral data produced during the translation.
The following is an example of the subject t1 post-editing a machine translation produced by Google Translate (task_type pe1 ) taken from the train split for Turkish. The field aligned_edit is showed over three lines to provide a visual understanding of its contents.
{
'unit_id': 'flores101-main-tur-46-pe1-3',
'flores_id': 871,
'item_id': 'flores101-main-463',
'subject_id': 'tur_t1',
'task_type': 'pe1',
'translation_type': 'pe',
'src_len_chr': 109,
'mt_len_chr': 129.0,
'tgt_len_chr': 120,
'src_len_wrd': 17,
'mt_len_wrd': 15.0,
'tgt_len_wrd': 13,
'edit_time': 11.762999534606934,
'k_total': 31,
'k_letter': 9,
'k_digit': 0,
'k_white': 0,
'k_symbol': 0,
'k_nav': 20,
'k_erase': 2,
'k_copy': 0,
'k_cut': 0,
'k_paste': 0,
'k_do': 0,
'n_pause_geq_300': 2,
'len_pause_geq_300': 4986,
'n_pause_geq_1000': 1,
'len_pause_geq_1000': 4490,
'event_time': 11763,
'num_annotations': 2,
'last_modification_time': 1643569484,
'n_insert': 0.0,
'n_delete': 2.0,
'n_substitute': 1.0,
'n_shift': 0.0,
'tot_shifted_words': 0.0,
'tot_edits': 3.0,
'hter': 20.0,
'cer': 0.10,
'bleu': 0.0,
'chrf': 2.569999933242798,
'lang_id': 'tur',
'doc_id': 46,
'time_s': 11.762999534606934,
'time_m': 0.1960500031709671,
'time_h': 0.0032675000838935375,
'time_per_char': 0.1079174280166626,
'time_per_word': 0.6919412016868591,
'key_per_char': 0.2844036817550659,
'words_per_hour': 5202.75439453125,
'words_per_minute': 86.71257019042969,
'per_subject_visit_order': 201,
'src_text': 'As one example, American citizens in the Middle East might face different situations from Europeans or Arabs.',
'mt_text': "Bir örnek olarak, Orta Doğu'daki Amerikan vatandaşları, Avrupalılardan veya Araplardan farklı durumlarla karşı karşıya kalabilir.",
'tgt_text': "Örneğin, Orta Doğu'daki Amerikan vatandaşları, Avrupalılardan veya Araplardan farklı durumlarla karşı karşıya kalabilir.",
'aligned_edit': "REF: bir örnek olarak, orta doğu'daki amerikan vatandaşları, avrupalılardan veya araplardan farklı durumlarla karşı karşıya kalabilir.\\n
HYP: *** ***** örneğin, orta doğu'daki amerikan vatandaşları, avrupalılardan veya araplardan farklı durumlarla karşı karşıya kalabilir.\\n
EVAL: D D S"
}
The text is provided as-is, without further preprocessing or tokenization.
Dataset Creation
The dataset was parsed from PET XML files into CSV format using the scripts available in the DivEMT Github repository .
Those are adapted from the ones by Antonio Toral found at the following link: https://github.com/antot/postediting_novel_frontiers .
Additional Information
Dataset Curators
For problems related to this ? Datasets version, please contact me at g.sarti@rug.nl .
Citation Information
@inproceedings{sarti-etal-2022-divemt,
title = "{D}iv{EMT}: Neural Machine Translation Post-Editing Effort Across Typologically Diverse Languages",
author = "Sarti, Gabriele and
Bisazza, Arianna and
Guerberof-Arenas, Ana and
Toral, Antonio",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.532",
pages = "7795--7816",
}