

















数据集:
RussianNLP/wikiomnia



 英文
英文"Wikiomnia" 数据集卡片
数据集概述
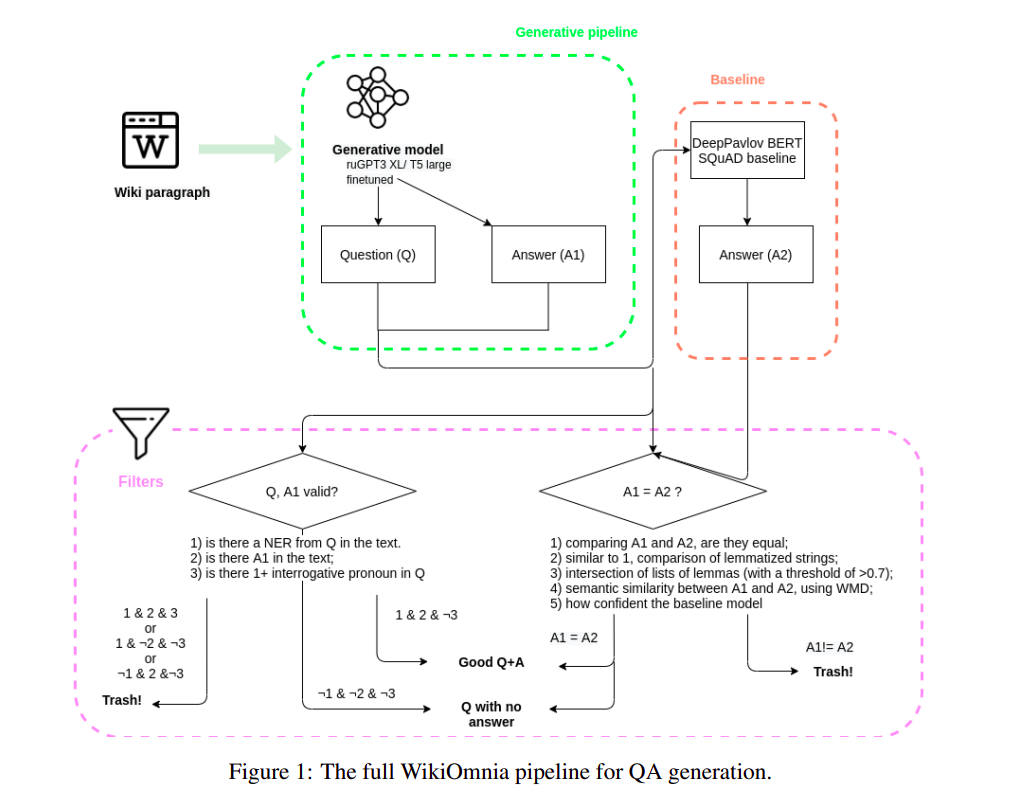
我们提供了WikiOmnia数据集,这是一个新的公开可用的QA问题和相应的俄语维基百科文章摘要部分的数据集,通过完全自动化的生成流程创建。该数据集包括俄语维基百科的所有可用文章。WikiOmnia生成流程是开源的,并且还经过了测试,用于创建其他领域(如新闻文本、小说和社交媒体)的以SQuAD格式提问回答。生成的数据集包含两个部分:整个俄语维基百科的原始数据(适用于ruGPT-3 XL的7,930,873个QA对和段落,以及适用于ruT5-large的7,991,040个QA对和段落),以及经过严格自动验证的清理数据(适用于ruGPT-3 XL的超过160,000个QA对和段落,以及适用于ruT5-large的超过 3,400,000个QA对和段落)。
WikiOmnia包括以下两部分:
WikiOmnia采用标准的SQuAD格式问题,生成的三元组形式为“文本段落 - 基于段落的问题 - 段落中的答案”,例如以下示例:
原始维基百科段落:Коити Масимо (яп. Масимо Ко:ити) — известный режиссёр аниме и основатель японской анимационной студии Bee Train. Смомента основания студии он руководит производством почти всех её картин, а также время от времени принимает участие в работе над анимацией и музыкой。
英文翻译:Koichi Mashimo是著名的动画导演和日本动画工作室Bee Train的创始人。自该工作室成立以来,他几乎导演了所有该工作室的作品,并且他有时还参与美术和音效工作。
生成的问题(ruT5):谁是日本动画工作室Bee Train的创始人?
生成的答案(ruT5):Коити Масимо
英文QA翻译:日本动画工作室Bee Train的创始人是谁?Koichi Mashimo
数据集创建
用于数据集生成的模型:
来源:2021年3月的维基百科版本
特殊标记:<[TEXT]>, <[QUESTION]>, <[ANSWER]>
生成的数据集包括两个部分:整个俄语维基百科的原始数据(适用于ruGPT-3 XL的7,930,873个QA对和段落,以及适用于ruT5-large的7,991,040个QA对和段落),以及经过严格自动验证的清理数据(适用于ruGPT-3 XL的超过160,000个QA对和段落,以及适用于ruT5-large的超过3,400,000个QA对和段落)。
其他信息
许可信息
引用信息
@inproceedings{pisarevskaya-shavrina-2022-wikiomnia,
title = "{W}iki{O}mnia: filtration and evaluation of the generated {QA} corpus on the whole {R}ussian {W}ikipedia",
author = "Pisarevskaya, Dina and
Shavrina, Tatiana",
booktitle = "Proceedings of the 2nd Workshop on Natural Language Generation, Evaluation, and Metrics (GEM)",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates (Hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.gem-1.10",
pages = "125--135",
abstract = "The General QA field has been developing the methodology referencing the Stanford Question answering dataset (SQuAD) as the significant benchmark. Compiling factual questions datasets requires manual annotations, limiting the training data{'}s potential size. We present the WikiOmnia dataset, a new publicly available set of QA pairs and corresponding Russian Wikipedia article summary sections, composed with a fully automated generation and filtration pipeline. To ensure high quality of generated QA pairs, diverse manual and automated evaluation techniques were applied. The WikiOmnia pipeline is available open-source and is also tested for creating SQuAD-formatted QA on other domains, like news texts, fiction, and social media. The resulting dataset includes two parts: raw data on the whole Russian Wikipedia (7,930,873 QA pairs with paragraphs for ruGPT-3 XL and 7,991,040 QA pairs with paragraphs for ruT5-large) and cleaned data with strict automatic verification (over 160,000 QA pairs with paragraphs for ruGPT-3 XL and over 3,400,000 QA pairs with paragraphs for ruT5-large).",
}