

















数据集:
SLPL/naab



 英文
英文naab:现成的即插即用的波斯语文献语料库
[如果您想加入我们的社区,了解来自naab的新闻、模型和数据集,请点击 this 链接。]
数据集摘要
naab是最大的已清洗和可直接使用的开源波斯语文本语料库。它包含约130GB的数据、2.5亿个段落和150亿个单词。该项目名称源自波斯语词语“ناب”,意为纯净高级。我们还提供了语料库的原始版本naab-raw,以及一个易于使用的预处理器,供希望制作定制语料库的用户使用。
您可以使用以下命令使用此语料库:
from datasets import load_dataset
dataset = load_dataset("SLPL/naab")
如果需要下载此语料库的部分/分割文件,请使用以下命令(您可以在这里找到更多使用方式 here ):
from datasets import load_dataset
dataset = load_dataset("SLPL/naab", split="train[:10%]")
注意:请确保您的计算机至少有130GB的可用空间,并且下载可能需要一些时间。如果遇到磁盘或互联网不足的情况,您可以使用下面的代码片段来帮助您下载自定义部分的naab:
from datasets import load_dataset
# ==========================================================
# You should just change this part in order to download your
# parts of corpus.
indices = {
"train": [5, 1, 2],
"test": [0, 2]
}
# ==========================================================
N_FILES = {
"train": 126,
"test": 3
}
_BASE_URL = "https://huggingface.co/datasets/SLPL/naab/resolve/main/data/"
data_url = {
"train": [_BASE_URL + "train-{:05d}-of-{:05d}.txt".format(x, N_FILES["train"]) for x in range(N_FILES["train"])],
"test": [_BASE_URL + "test-{:05d}-of-{:05d}.txt".format(x, N_FILES["test"]) for x in range(N_FILES["test"])],
}
for index in indices['train']:
assert index < N_FILES['train']
for index in indices['test']:
assert index < N_FILES['test']
data_files = {
"train": [data_url['train'][i] for i in indices['train']],
"test": [data_url['test'][i] for i in indices['test']]
}
print(data_files)
dataset = load_dataset('text', data_files=data_files, use_auth_token=True)
支持的任务和排行榜
此语料库可用于训练所有可以通过掩码语言建模(MLM)或任何其他自监督目标进行训练的语言模型。
- 语言建模
- 掩码语言建模
数据集结构
数据集的每一行内容将类似于以下内容:
{
'text': "این یک تست برای نمایش یک پاراگراف در پیکره متنی ناب است.",
}
- 文本:文本段落。
数据拆分
此数据集包含两个拆分(训练集和测试集)。我们将随机排列版本的语料库划分为(95%,5%)的训练集和测试集。由于在训练过程中通常会使用训练集进行验证,因此我们避免了为验证集提供另一个拆分。
| train | test | |
|---|---|---|
| Input Sentences | 225892925 | 11083849 |
| Average Sentence Length | 61 | 25 |
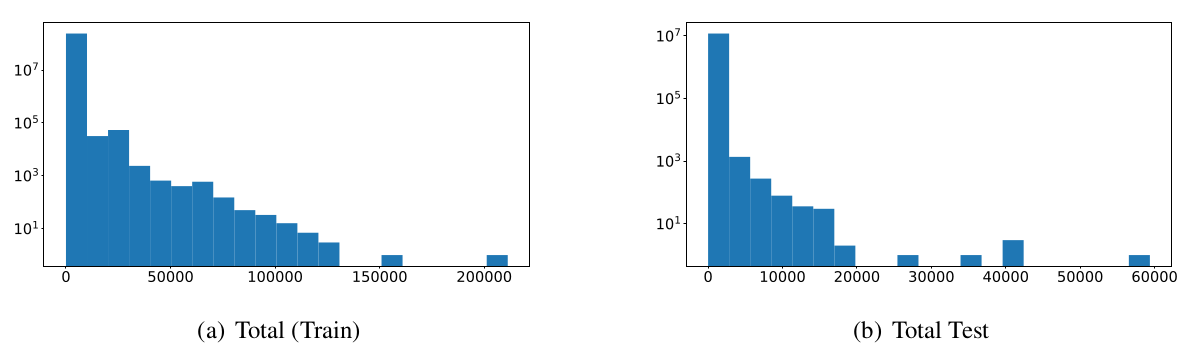
以下是该数据集两个拆分的基于日志的单词/段落直方图。
数据集创建
策划理由
由于较低资源语言(如波斯语)中缺乏大量文本数据,研究这些语言的研究人员在开始微调这些模型时一直遇到困难。这种现象导致微调模型的黄金机会仅掌握在少数公司或国家手中,从而削弱了开放科学。
波斯语最后一个最大的已清洗合并文本语料库是一个70GB的已清洗文本语料库,由8个大型数据集的编译组成,可以直接下载。我们提出的解决方案是naab。它提供了126GB的训练语料库和2.3GB的测试语料库。训练语料库包括超过224万个序列和近150亿个单词;测试语料库包括近1100万个序列和近3亿个单词。
来源数据
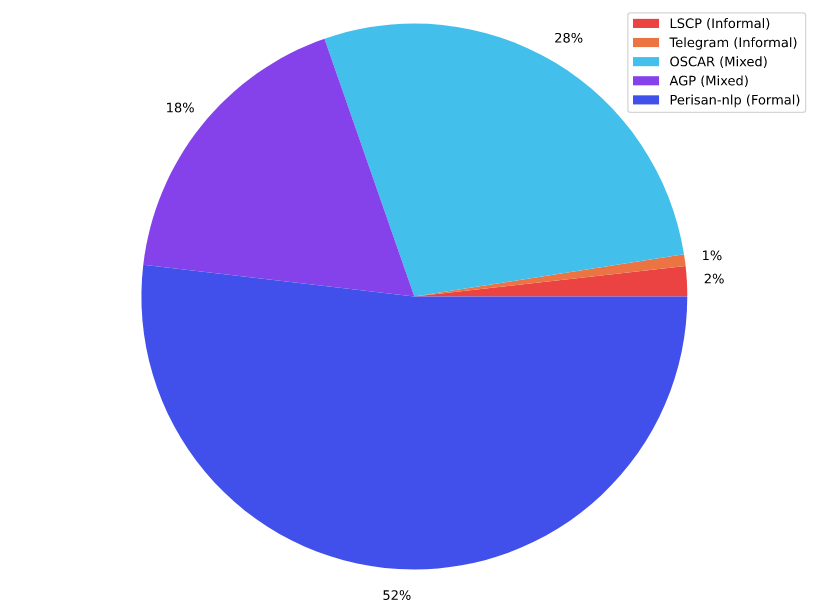
我们使用的文本语料库如下图所示。它包含5个文献现役, 关联在接下来的章节中。
 波斯NLP
波斯NLP This 语料库包括以下按体积排序的八个语料库:
- Common Crawl :65GB( link )
- MirasText :12G
- W2C – Web to Corpus :1GB( link )
- 波斯维基百科(2020年3月数据):787MB( link )
- Leipzig Corpora :424M( link )
- VOA corpus :66MB( link )
- Persian poems corpus :61MB( link )
- TEP: Tehran English-Persian parallel corpus :33MB( link )
此语料库原先是ASR Gooyesh Pardaz的私人语料库,现已通过此项目对所有用户开放。该语料库包含超过1.4亿个段落,总计23GB(清洗后)。该语料库是从不同网站和/或社交媒体上爬取的正式和非正式段落的混合体。
OSCAR-faOSCAR 或称为Open Super-large Crawled ALMAnaCH coRpus,是通过使用go classy架构对Common Crawl语料库进行语言分类和过滤而获得的庞大多语言语料库。数据按语言分发,包括原始和去重的形式。我们使用了该语料库中的未洗牌去重波斯语版本,清洗后剩余约36GB。
Telegram电报是一种基于云的即时消息服务,在伊朗广泛使用。根据这个假设,我们准备了一个包含波斯语电报频道的列表,涵盖各种主题,包括体育、日常新闻、笑话、电影和娱乐等。从这些频道提取的文本数据主要包含非正式数据。
LSCPThe Large Scale Colloquial Persian Language Understanding dataset 包含来自2700万非正式波斯语句子的1.2亿个句子及其派生树、词性标签、情感极性和英语、德语、捷克语、意大利语和印地语的翻译。然而,我们仅使用了其中的波斯语部分,并在清洗后剩下2.3GB。由于该数据集是非正式的,它可能有助于我们的语料库具有更多的非正式句子,尽管其比例与正式段落不可比拟。
初始数据收集和标准化数据收集过程分为两个部分。在第一部分中,我们搜索现有的语料库。在下载这些语料库之后,我们开始从一些社交网络中爬取数据。然后,借助 ASR Gooyesh Pardaz ,我们获得了足够的文本数据来开始naab的旅程。
我们使用了基于一些基于流的Linux内核命令的预处理器,以减少这个过程的时间和内存消耗。代码提供在 here 上。
个人和敏感信息
由于这个语料库简要地是一些以前语料库的汇编,我们对其中包含的个人信息不承担任何责任。如果发现任何违规行为,请告知我们,我们会尽力从语料库中删除它们。
我们竭尽全力在保持关键信息的匿名性的同时,保持必要信息。我们对语料库的某些部分进行了混洗,以便通过可能的对话传递的信息不会对人们造成伤害。
附加信息
数据集策划者
- Sadra Sabouri(Sharif理工大学)
- Elnaz Rahmati(Sharif理工大学)
许可信息
MIT?
引用信息
@article{sabouri2022naab,
title={naab: A ready-to-use plug-and-play corpus for Farsi},
author={Sabouri, Sadra and Rahmati, Elnaz and Gooran, Soroush and Sameti, Hossein},
journal={arXiv preprint arXiv:2208.13486},
year={2022}
}
DOI: https://doi.org/10.48550/arXiv.2208.13486
贡献
感谢 @sadrasabouri 和 @elnazrahmati 添加了此数据集。
关键词
- 波斯语
- 波斯语
- 原始文本
- پیکره فارسی
- پیکره متنی
- آموزش مدل زبانی