

















数据集:
clarin-pl/2021-punctuation-restoration


 英文
英文从读出的文本中恢复标点符号
从自动语音识别(ASR)系统的输出中恢复标点符号。
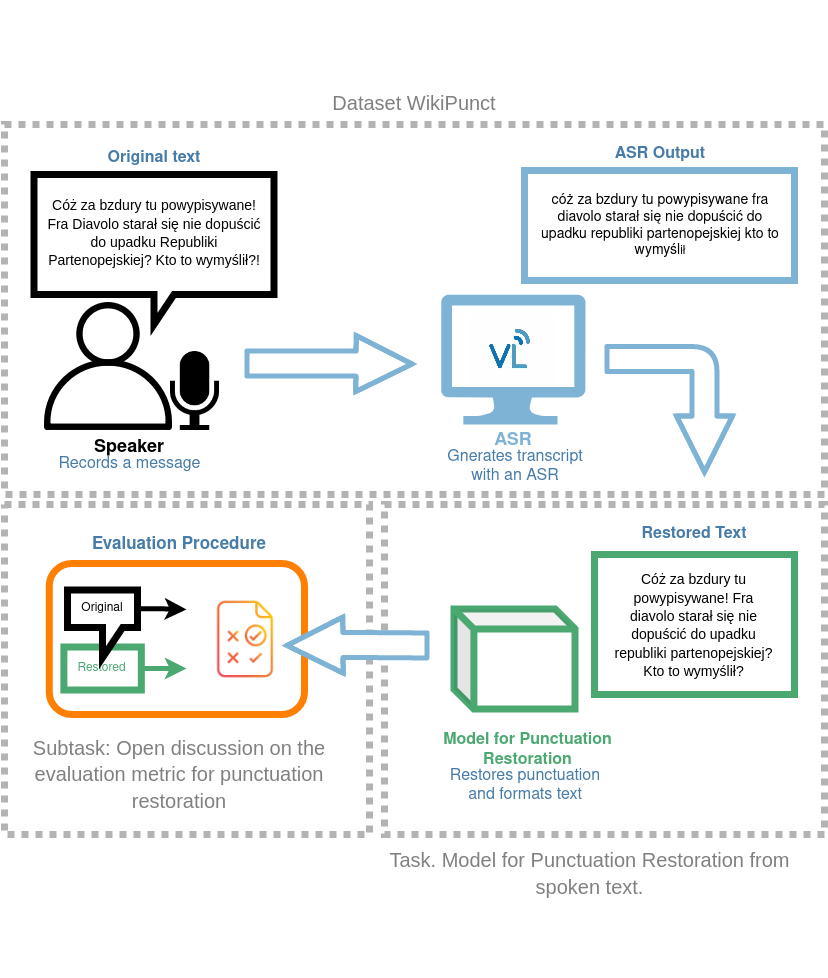
动机
由自动语音识别(ASR)系统生成的语音转录通常不包含任何标点符号或大写字母。在较长的自动识别语音中,缺乏标点符号会影响输出文本的整体清晰度[1]。标点还原(PR)和大写字母恢复(CR)作为一种独立的自然语言处理(NLP)任务的主要目的是提高ASR生成的文本的可读性,并可能改善其他类型的无标点文本的性能。除了它们的内在价值,PR和CR还可以提高其他NLP方面的性能,如命名实体识别(NER)、词性(POS)和语义解析或口语对话分割[2,3]。尽管看起来很有用,但是对于会话语言的转录进行PR的系统评估是困难的;主要是因为即使对于最初的书面文本,标点符号规则也可能是有歧义的,并且自然发生的口语语言的特点使得难以确定清晰的短语和句子边界[4,5]。在这些要求和限制的情况下,提出了一种基于可再分发的读语音语料库的PR任务。这个集合中包括1200个文本(总计超过24万个词),选自两个不同的来源:维基新闻和维基讲座。在用于评估时,应谨慎对待这些来源中的标点符号:这些是原始文本,可能包含一些用户引发的错误和偏见。这些文本由100多位不同的发言人朗读出来。该任务的目标是为这个任务收集的测试集提供恢复标点的解决方案。测试集由两个来源的时间对齐的ASR语音转录组成。鼓励参与者使用基于文本和语音的特征来识别标点符号(如多模态框架[6])。此外,训练集附带了维基新闻和维基讲座数据的参考文本语料库,可以用于训练和微调标点模型。
任务描述
该任务的目的是恢复朗读文本中的标点符号。
输入('tokens'列):一系列标记
输出('tags'列):一系列标签
评估指标:F1分数(seqeval)
示例:
输入:['selekcjoner','szosowej','kadry','elity','męzczyzn','piotr','wadecki','ogłosił','27','marca','2008','r','szeroki','skład','zawodników','którzy','będą','rywalizować','o','miejsce','w','reprezentacji','na','tour','de','pologne','lista','liczy','22','nazwiska','zawodników','zarówno','z','zagranicznych','jaki','i','polskich','ekip','spośród','22','wybrańców','selekcjonera','do','składu','dostanie','się','tylko','ośmiu','kolarzy','którzy','we','wrześniu','będą','rywalizować','z','najlepszymi','grupami','kolarskimi','na','świecie','w','kręgu','zainteresowania','wadeckiego','znajduje','się','także','pięciu','innych','zawodników','ale','oni','prawdopodobnie','wystartują','w','polskim','tourze','w','szeregach','swoich','ekip','szeroka','kadra','na','tour','de','pologne','dariusz','baranowski','łukasz','bodnar','bartosz','huzarski','błażej','janiaczyk','tomasz','kiendyś','mateusz','komar','tomasz','lisowicz','piotr','mazur','jacek','morajko','przemysław','niemiec','marek','rutkiewicz','krzysztof','szczawiński','mateusz','taciak','adam','wadecki','mariusz','witecki','piotr','zaradny','piotr','zieliński','mateusz','mróz','marek','wesoły','jarosław','rębiewski','robert','radosz','jarosław','dąbrowski']
输入(DeepL翻译):男子精英公路自行车队的选择人皮奥特·瓦德奇(Piotr Wadecki)于2008年3月27日宣布了一支庞大的选手阵容,他们将争夺波兰环自行车赛的国家队席位。名单上有22个选手的名字,来自国外和波兰的车队,只有由选择人选出的22名选手中的8名将进入阵容,在九月份,他们将与世界上最好的自行车集团竞争瓦德奇的兴趣范围还包括其他五名自行车手,但他们可能会在波兰比赛中以自己车队的身份参赛波兰环的庞大阵容达里乌什·巴拉诺夫斯基(Dariusz Baranowski)卢卡什·博德纳尔(Łukasz Bodnar)巴托什·胡扎斯基(Bartosz Huzarski)布拉日·雅尼亚切克(Błażej Janiaczyk)托马什·基恩迪斯(Tomasz Kiendyś)马特乌什·科马尔(Mateusz Komar)托马什·利索维奇(Tomasz Lisowicz)皮奥特·马祖尔(Piotr Mazur)雅采克·莫拉伊科(Jacek Morajko)普日梅斯瓦夫·尼姆茨(Przemysław Niemiec)马伦克·鲁特基维奇(Marek Rutkiewicz)克日什托夫·什卡维茨基(Krzysztof Szczawiński)马特乌什·塔查克(Mateusz Taciak)亚当·瓦德奇(Adam Wadecki)马留什·威特基(Mariusz Witecki)皮奥特·扎拉德尼(Piotr Zaradny)皮奥特·兹列延斯基(Piotr Zieliński)马特乌什·姆罗济(Mateusz Mróz)马雷克·韦索维(Marek Wesoły)雅罗斯瓦夫·雷比夫斯基(Jarosław Rębiewski)罗伯特·拉多什(Robert Radosz)雅罗斯瓦夫·丹布罗夫斯基(Jarosław Dąbrowski)
输出:['O','O','O','O','O','O','O','O','O','O','O','B-. ','O','O','B-,','O','O','O','O','O','O','O','O','O','O','B-. ','O','O','O','O','O','O','O','B-,','O','O','O','B-. ','O','O','O','O','O','O','O','O','O','O','B-. ','O','O','O','O','O','O','O','O','O','B-. ','O','O','O','O','O','O','O','O','O','O','B-. ','O','O','O','O','O','O','O','O','O','B-. ','O','O','O','O','O','O','O','O','O','O','B-. ','O','O','O','O','O','B-:','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O','O']
数据集 - WikiPunct
WikiPunct 是一个由波兰维基百科页面的文本和音频数据集,由波兰讲解员朗读而成的众包数据集。该数据集分为两个部分:对话(WikiTalks)和信息(WikiNews)。超过一百人参与了音频部分的制作。音频数据的总时长接近三十六小时,包括测试集。为了平衡男女比例,采取了相应的措施。
WikiPunct 拥有3.2万多个文本和1200个音频文件,其中有1000个在训练集中,200个在测试集中。每个文本都有自动识别语音的转录和强制对齐的文本。有关数据格式和评估指标的详细信息将在下面的各个部分中介绍。
统计数据:
- 文本:
- 超过3.2万个文本;WikiNews约15,000个,WikiTalks约17,000个;
- 音频:
- 选择过程:
- 随机选择的WikiNews(80%),字数大于150个单词且小于300个单词;
- 随机选择的WikiTalks(20%),字数大于150个单词但小于300个单词,并至少包含一个问号
- 数据集分配:
- 训练数据:1000个录音
- 测试数据:274个录音
- 发言者:
- 波兰男性:51位发言者,16.7小时的语音
- 波兰女性:54位发言者,19小时的语音
- 选择过程:
数据集分割
| Subset | Cardinality (texts) |
|---|---|
| train | 800 |
| dev | 0 |
| test | 200 |
类别分布(不包括“O”)
| Class | train | validation | test |
|---|---|---|---|
| B-. | 0.419 | - | 0.416 |
| B-, | 0.406 | - | 0.403 |
| B-- | 0.097 | - | 0.099 |
| B-: | 0.037 | - | 0.052 |
| B-? | 0.032 | - | 0.024 |
| B-! | 0.005 | - | 0.004 |
| B-; | 0.004 | - | 0.002 |
原始文本的标点符号
| symbol | mean | median | max | sum | included | |
|---|---|---|---|---|---|---|
| fullstop | . | 12.44 | 7.0 | 1129.0 | 404 378 | yes |
| comma | , | 10.97 | 5.0 | 1283.0 | 356 678 | yes |
| question_mark | ? | 0.83 | 0.0 | 130.0 | 26 879 | yes |
| exclamation_mark | ! | 0.22 | 0.0 | 55.0 | 7 164 | yes |
| hyphen | - | 2.64 | 1.0 | 363.0 | 81 190 | yes |
| colon | : | 1.49 | 0.0 | 202.0 | 44 995 | yes |
| ellipsis | ... | 0.27 | 0.0 | 60.0 | 8 882 | yes |
| semicolon | ; | 0.13 | 0.0 | 51.0 | 4 270 | no |
| quote | " | 3.64 | 0.0 | 346.0 | 116 874 | no |
| words | 169.50 | 89.0 | 17252.0 | 5 452 032 | - |
该数据集分为两个部分:对话(WikiTalks)和信息(WikiNews)。
部分1. WikiTalks
从波兰维基百科讨论页中获取的数据。讨论页也称为讨论页面,是维基百科文章的管理页面,包含有关编辑的详细信息和讨论。使用与维基百科转储归档一起共享的文章标题列表从Web中获取了讨论页。
维基百科讨论页用作对话数据。在这里,用户通过撰写评论与彼此交流。预计会出现词汇和标点符号的错误。这个数据集覆盖了口语数据的20%。
示例:
- wikitalks001948:这里写的是什么荒唐之言!Diavolo主教努力防止诺波利共和国的崩溃?谁想出这个的?这个人是法国占领的最坚决的敌人之一,由于把法国人赶走所做出的贡献,被任命为皇家军队的上校,拥有真正皇家的薪水。如果没有他,解放王国北部的行动将困难得多,因为他拥有几千个战斗力强大且熟练的暴徒。因此,波旁王国的军队不是战胜他,正如文章中所说的那样,而是与他紧密合作。编辑们被鼓励尽快对文章进行修正,因为目前它对维基百科的雄心壮志是一种侮辱。91.199.250.17
- wikitalks008902:我将旧的讨论线程移动到了存档。这些讨论已经没有进行了将近一年的时间。斯拉威克·博雷维奇
部分2. WikiNews
Wikinews 是维基媒体基金会的一个免费新闻维基和项目。该网站通过协作新闻报道。数据直接从wikinews转储档案中获取。总体文本质量较高,但可能会出现词汇和标点符号的错误。这个数据集覆盖了口语数据的80%。
示例:
- wikinews222361:航天飞机Endeavour的STS-127任务前往国际空间站因氢气泄漏而延迟。在向外部燃料箱注入燃料的过程中,部分液态氢转化为气体,并进入了通风系统。该系统用于安全地将发射平台39A上的过量氢气排放到约翰·F·肯尼迪太空中心。本次任务在今天13:17计划开始,但由于故障,航天飞机最近可能会在6月17日星期三发射,但是当天在Cape Canaveral计划进行的月球勘测轨道器的发射。因此,该任务可能会延迟到6月20日,这是本月最后的发射日期。星期日,NASA将举行一次专家会议,讨论新的发射日期和STS-127任务的进一步计划。
数据格式
输入是一个带有两列的TSV文件:
输出应与输入文件具有相同的行数,每行给出带有标点符号的文本。
强制对齐转录
我们使用原始文本的强制对齐转录来近似ASR输出。以.clntmstmp格式的文件包含原始文本的强制对齐以及由一组志愿者朗读的音频文件。这些文件可能包含由于对文本的不正确朗读(跳过片段、添加原始文本中缺失的单词)和由于文本和音频文件的对齐工具配置而导致的对齐错误。配置针对的是波兰语;在外国语言的名称中可能会出现识别不良的情况,其单词持续时间为零(开始和结束时间戳相等)。数据以以下格式给出:
(开始时间戳,结束时间戳) 单词
...
</s>
其中</s>是表示识别结束的符号。
示例:
(990,1200) Rossja
(1230,1500) zaczyna
(1590,1950) powracać
(1980,2040) do
(2070,2400) praktyk
(2430,2490) z
(2520,2760) czasów
(2820,3090) zimnej
(3180,3180) wojny.
(3960,4290) Rosjanie
(4380,4770) wznowili
(4860,5070) bowiem
(5100,5160) na
(5220,5430) stałe
(5520,5670) loty
(5760,6030) swoich
(6120,6600) bombowców
(6630,7230) strategicznych
(7350,7530) poza
(7590,7890) granice
(8010,8010) kraju.
(8880,9300) Prezydent
(9360,9810) Władimir
(9930,10200) Putin
(10650,10650) wyjaśnił,
(10830,10920) iż
(10980,11130) jest
(11160,11190) to
(11220,11520) odpowiedź
(11550,11640) na
(11670,12120) zagrożenie
(12240,12300) ze
(12330,12570) strony
(12660,12870) innych
(13140,13140) państw.
</s>
评估过程
最终评估中将评估以下标点符号:
| Punctuation mark | symbol |
|---|---|
| fullstop | . |
| comma | , |
| question mark | ? |
| exclamation mark | ! |
| hyphen | - |
| colon | : |
| ellipsis | ... |
| blank (no punctuation) |
注意这里不考虑分号(;)。
提交格式
要进行评估的输出只是添加了标点符号的文本。
指标
最终的结果将根据分别预测每个标点符号的精确度、召回率和F1得分来评估。提交结果将根据每个标点符号的全局得分的加权平均值进行比较。
每个文档的得分: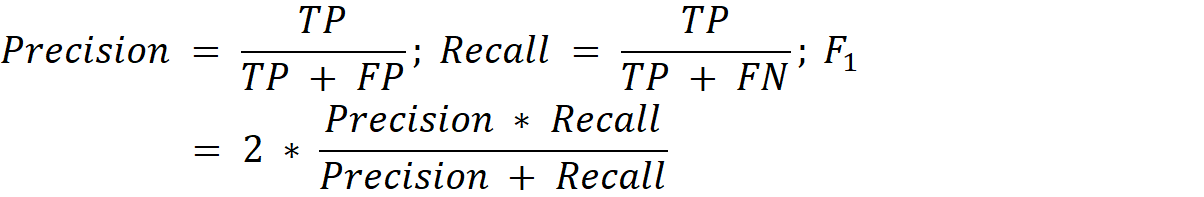 每个标点符号 p 的全局得分:
每个标点符号 p 的全局得分:

最终的评分指标计算为全局分数的加权平均值
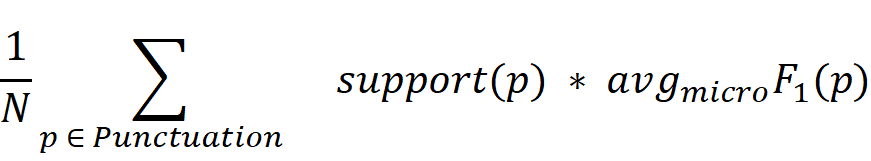
我们邀请参与者就评估指标进行讨论,考虑到以下因素:
- ASR和强制对齐错误
- 标注者之间的不一致性
- 对标点符号轻微偏移的影响
- 对不同类型错误分配不同权重
视频介绍
下载
数据已发布在以下仓库中: https://github.com/poleval/2021-punctuation-restoration
训练数据提供在train/ * .tsv中。可从Google Drive下载其他数据。下面是文件名的列表以及它们所包含的内容的描述。
- poleval_fa.train.tar.gz - 归档包含原始文本的强制对齐和音频文件
- poleval_wav.train.tar.gz - 归档包含训练音频文件
- poleval_wav.validation.tar.gz - 归档包含测试音频文件
- poleval_text.rest.tar.gz - 归档包含以JSON格式和CSV提供的其他文本(没有提供音频文件,可以用于训练目的)
挑战阶段
2021年9月进行比赛。现在挑战处于比赛后阶段。您可以提交解决方案,但它们将用不同的颜色标记。
许可证
知识共享-署名-非商业性使用-禁止演绎 4.0 国际 (CC BY-NC-ND 4.0)