

















数据集:
codeparrot/self-instruct-starcoder


 英文
英文自我教导星编码器
摘要
自我教导星编码器是一个由人类编写的种子指令作为输入,通过提示星编码器生成新指令的数据集。其中的生成过程在论文中进行了解释。该算法诞生了著名的机器生成数据集,如 Alpaca 和 Code Alpaca ,这是通过提示OpenAI text-davinci-003引擎获得的两个数据集。
我们的方法
尽管我们的方法与自我教导和斯坦福alpaca相似,但我们对流程进行了一些相关修改以满足我们的需求。
- 我们选择的是prompt 是 StarCoder ,而不是text-davinci-003,后者是一个10倍较小的专门用于代码用例的LLM。但是,可以在Hub上使用任何decoder based LLM。
- 为了让模型生成与代码相关的任务,我们更改了种子任务。我们通过20个额外的算法指令完成了代码alpaca的种子任务。
- 我们将生成格式从"instruction": - "input": - "output": 改为了"instruction": - "output":,将每个指令及其输入连接在关键字instruction下。我们之所以这样做,是因为先前的提示格式往往使模型生成将测试用例作为输入、将其解决方案作为输出的情况,而这并不是我们想要的。
- 最后,我们增加了更改提示中的触发词的可能性。因此,我们将"instruction"替换为"Here is the correct solution to the problem ",从而生成更好的指令。
数据集生成
数据集的生成非常耗时,我们选择参数以限制我们方法的计算负担。
- 上下文中的示例数量:4
- 2个种子指令
- 2个机器生成的指令
- 要生成的指令数量:5000
- 生成中使用的停用词:["\n20", "20.", "20 ."]
- rouge分数的相似度阈值:0.7
数据集质量
星编码器虽然是一个很棒的模型,但它的能力不及text-davinci-003。在生成过程中,模型很快达到了一种创造力的上限。有很多指令彼此相似,但这不应该成为问题,因为它们的措辞不同。
后处理
后处理是流程中的重要部分,尽管它意味着要放弃一些示例,但它可以提高数据集的质量。首先,我们需要确定我们要避免的内容:
- 生成的解决方案不能回答相应的指令
- 一个指令与另一个指令太相似。
自一致性
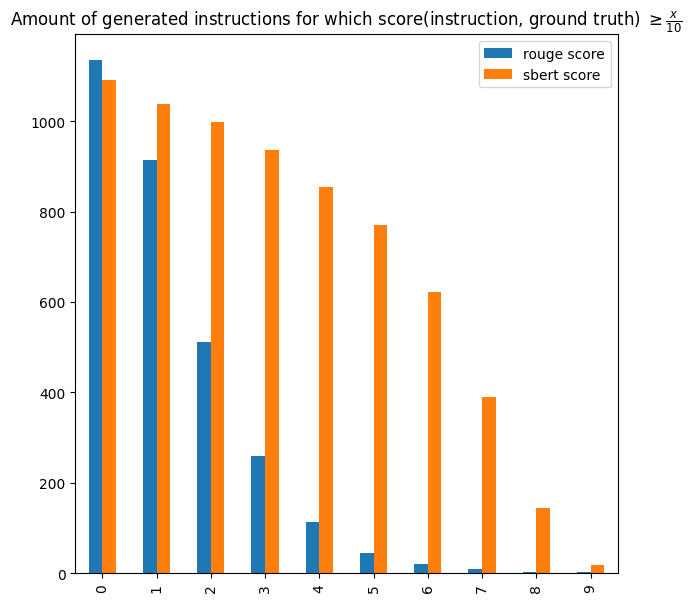
我们想象了一个我们称之为自一致性的过程。这个想法是反向提示模型,看它是否能够生成与所提示的解决方案(输出)相对应的正确指令。这是一个特别困难的few-shot任务,不幸的是,StarCoder在这方面的表现并不是非常出色。在4个few-shot参数的情况下(都是种子任务),模型能够恢复1135个指令,占原始数据集的22.6%。幸运的是,starcoder无法为某些解决方案生成指令并不意味着我们应该将其丢弃。对于具有生成指令的解决方案(输出),我们可以将其与真实结果进行比较。为此,我们可以使用 Sentence-BERT ,因为比较应该侧重于含义而不是逐字逐句的相似比率。我们有约771个指令(约68%),其与其真实结果的相似度得分>=0.5。这些可以被视为高质量的示例,它们形成了策划集。
独特性
另一种用于清理原始数据集的方法是专注于不同的指令。对于给定的指令,我们遍历它之前生成的所有指令,看是否有一个相似度得分>=0.5。如果是这样,我们将删除该指令。这个过程删除了大约94%的原始数据集,剩下的指令形成了独特集。
编译
我们还决定构建一个仅包含使用Python 3编写的、没有编译错误的代码的示例集合。
数据集结构
from datasets import load_dataset
dataset = load_dataset("codeparrot/self-instruct-starcoder")
DatasetDict({
compile: Dataset({
features: ['instruction', 'output', 'most_similar', 'avg_similarity_score'],
num_rows: 3549
})
curated: Dataset({
features: ['instruction', 'output', 'most_similar', 'avg_similarity_score'],
num_rows: 771
})
raw: Dataset({
features: ['instruction', 'output', 'most_similar', 'avg_similarity_score'],
num_rows: 5003
})
unique: Dataset({
features: ['instruction', 'output', 'most_similar', 'avg_similarity_score'],
num_rows: 308
})
}))
| Field | Type | Description |
|---|---|---|
| instruction | string | Instruction |
| output | string | Answer to the instruction |
| most_similar | string | Dictionnary containing the 10 most similar instructions generated before the current instruction along with the similarity scores |
| avg_similarity_score | float64 | Average similarity score |
其他资源
引用
@misc{title={Self-Instruct-StarCoder},
author={Zebaze, Armel Randy},
doi={https://doi.org/10.57967/hf/0790},
}