

















数据集:
debatelab/aaac

语言:
 en
en
计算机处理:
monolingual大小:
10K<n<100K语言创建人:
machine-generated源数据集:
original预印本库:
arxiv:2110.01509许可:
 cc-by-sa-4.0
cc-by-sa-4.0
 英文
英文人工参数分析语料库(AAAC)数据集卡
数据集摘要
DeepA2是一个用于深度参数分析的模块化框架。DeepA2数据集包含短参数文本中非正式呈现的参数的全面逻辑重建。本文档描述了两个人工参数分析的DeepA2数据集:AAAC01和AAAC02。
# clone git lfs clone https://huggingface.co/datasets/debatelab/aaac
import pandas as pd
from datasets import Dataset
# loading train split as pandas df
df = pd.read_json("aaac/aaac01_train.jsonl", lines=True, orient="records")
# creating dataset from pandas df
Dataset.from_pandas(df)
支持的任务和榜单
多维数据集可用于定义各种文本到文本任务(另请参见 Betz and Richardson 2021 ),例如:
- 前提提取
- 结论提取
- 逻辑形式化
- 逻辑重建
语言
英语。
数据集结构
数据实例
下面的直方图(给定属性的数据集记录数)描述并比较了两个数据集AAAC01(训练集,N=16000)和AAAC02(开发集,N=4000)。
| AAAC01 / train split | AAAC02 / dev split |
|---|
数据字段
以下多维示例记录(具有一个隐含前提的2步参数)说明了AAAC数据集的结构。
argument_sourceIf someone was discovered in 'Moonlight', then they won't play the lead in 'Booksmart', because being a candidate for the lead in 'Booksmart' is sufficient for not being an Oscar-Nominee for a role in 'Eighth Grade'. Yet every BAFTA-Nominee for a role in 'The Shape of Water' is a fan-favourite since 'Moonlight' or a supporting actor in 'Black Panther'. And if someone is a supporting actor in 'Black Panther', then they could never become the main actor in 'Booksmart'. Consequently, if someone is a BAFTA-Nominee for a role in 'The Shape of Water', then they are not a candidate for the lead in 'Booksmart'.reason_statements
[
{"text":"being a candidate for the lead in 'Booksmart' is sufficient for
not being an Oscar-Nominee for a role in 'Eighth Grade'","starts_at":96,
"ref_reco":2},
{"text":"every BAFTA-Nominee for a role in 'The Shape of Water' is a
fan-favourite since 'Moonlight' or a supporting actor in 'Black Panther'",
"starts_at":221,"ref_reco":4},
{"text":"if someone is a supporting actor in 'Black Panther', then they
could never become the main actor in 'Booksmart'","starts_at":359,
"ref_reco":5}
]
conclusion_statements [
{"text":"If someone was discovered in 'Moonlight', then they won't play the
lead in 'Booksmart'","starts_at":0,"ref_reco":3},
{"text":"if someone is a BAFTA-Nominee for a role in 'The Shape of Water',
then they are not a candidate for the lead in 'Booksmart'","starts_at":486,
"ref_reco":6}
]
distractors []
argdown_reconstruction(1) If someone is a fan-favourite since 'Moonlight', then they are an Oscar-Nominee for a role in 'Eighth Grade'.
(2) If someone is a candidate for the lead in 'Booksmart', then they are not an Oscar-Nominee for a role in 'Eighth Grade'.
--
with hypothetical syllogism {variant: ["negation variant", "transposition"], uses: [1,2]}
--
(3) If someone is beloved for their role in 'Moonlight', then they don't audition in
'Booksmart'.
(4) If someone is a BAFTA-Nominee for a role in 'The Shape of Water', then they are a fan-favourite since 'Moonlight' or a supporting actor in 'Black Panther'.
(5) If someone is a supporting actor in 'Black Panther', then they don't audition in
'Booksmart'.
--
with generalized dilemma {variant: ["negation variant"], uses: [3,4,5]}
--
(6) If someone is a BAFTA-Nominee for a role in 'The Shape of Water', then they are not a
candidate for the lead in 'Booksmart'.
premises [
{"ref_reco":1,"text":"If someone is a fan-favourite since 'Moonlight', then
they are an Oscar-Nominee for a role in 'Eighth Grade'.","explicit":false},
{"ref_reco":2,"text":"If someone is a candidate for the lead in
'Booksmart', then they are not an Oscar-Nominee for a role in 'Eighth
Grade'.","explicit":true},
{"ref_reco":4,"text":"If someone is a BAFTA-Nominee for a role in 'The
Shape of Water', then they are a fan-favourite since 'Moonlight' or a
supporting actor in 'Black Panther'.","explicit":true},
{"ref_reco":5,"text":"If someone is a supporting actor in 'Black Panther',
then they don't audition in 'Booksmart'.","explicit":true}
]
premises_formalized [
{"form":"(x): ${F2}x -> ${F5}x","ref_reco":1},
{"form":"(x): ${F4}x -> ¬${F5}x","ref_reco":2},
{"form":"(x): ${F1}x -> (${F2}x v ${F3}x)","ref_reco":4},
{"form":"(x): ${F3}x -> ¬${F4}x","ref_reco":5}
]
conclusion [{"ref_reco":6,"text":"If someone is a BAFTA-Nominee for a role in 'The Shape
of Water', then they are not a candidate for the lead in 'Booksmart'.",
"explicit":true}]
conclusion_formalized [{"form":"(x): ${F1}x -> ¬${F4}x","ref_reco":6}]
intermediary_conclusions [{"ref_reco":3,"text":"If someone is beloved for their role in 'Moonlight',
then they don't audition in 'Booksmart'.","explicit":true}]
intermediary_conclusions_formalized [{"form":"(x): ${F2}x -> ¬${F4}x","ref_reco":3}]
plcd_subs {
"F1":"BAFTA-Nominee for a role in 'The Shape of Water'",
"F2":"fan-favourite since 'Moonlight'",
"F3":"supporting actor in 'Black Panther'",
"F4":"candidate for the lead in 'Booksmart'",
"F5":"Oscar-Nominee for a role in 'Eighth Grade'"
}
数据拆分
各个拆分中的实例数:
| Split | AAAC01 | AAAC02 |
|---|---|---|
| TRAIN | 16,000 | 16,000 |
| DEV | 4,000 | 4,000 |
| TEST | 4,000 | 4,000 |
要正确加载特定拆分,请将 data_files 定义如下:
>>> data_files = {"train": "aaac01_train.jsonl", "eval": "aaac01_dev.jsonl", "test": "aaac01_test.jsonl"}
>>> dataset = load_dataset("debatelab/aaac", data_files=data_files)
数据集创建
策划理由
参数分析是指对参数性文本的解释和逻辑重建。其目标是使参数透明,以便理解、欣赏和(可能)批评它。参数分析是关键的批判性思维技能。
下面是一个简短参数的非正式呈现的第一个例子,笛卡尔的“我思故我在”:
我已经使自己相信世界上绝对没有任何东西,没有天空、没有地球、没有思想、没有身体。现在是否会有结论我并不存在?不会:如果我使自己相信了某件事,那么我当然是存在的。但是存在一个有极大力量和狡诈的欺骗者一直在欺骗我。在这种情况下,只要他欺骗我,我就无疑存在;只要我认为我是某种存在,无论他如何欺骗我,他都永远不会使我成为“不存在”。因此,在仔细考虑了一切问题之后,我必须最终得出这样一个结论:无论我或别人声称或在我的心中构思这个命题,都必然是真实的。 (AT 7:25,CSM 2:16f)
这里有一个第二个例子,来自辩论手册《支持审查制度》:
言论自由从来不是绝对的权利,而是一种愿望。当它对他人造成伤害时,它就不再是一项权利了——我们都承认,例如,立法禁止煽动种族仇恨具有价值。因此,审查制度原则上并不错误。
给定这样的文本,参数分析的目标是回答以下问题:
- 在文本中明确的陈述中,哪些陈述与参数无关?
- 哪些前提是必需的,但没有明确陈述?
要回答这些问题,参数分析学家通过对文本进行解释(重建)来(重)构建其参数,通常以前提-结论列表的形式,并通过使用逻辑简化和形式化。
对于上述“支持审查制度”,对这些问题的一个回答是:
(1) Freedom of speech is never an absolute right but an aspiration.
(2) Censorship is wrong in principle only if freedom of speech is an
absolute right.
--with modus tollens--
(3) It is not the case that censorship is wrong in principle
通常,存在着多种不同的参数性文本解释和逻辑重建。例如,关于如何解释“我思故我在”的仍存在争议,学者们对这个参数提出了不同的解释。一个更简单的“支持审查制度”的替代重建可能是:
(1) Legislating against incitement to racial hatred is valuable.
(2) Legislating against incitement to racial hatred is an instance of censorship.
(3) If some instance of censorship is valuable, censorship is not wrong in
principle.
-----
(4) Censorship is not wrong in principle.
(5) Censorship is wrong in principle only if and only if freedom of speech
is an absolute right.
-----
(4) Freedom of speech is not an absolute right.
(5) Freedom of speech is an absolute right or an aspiration.
--with disjunctive syllogism--
(6) Freedom of speech is an aspiration.
这种不确定性存在的主要原因是什么?
- 不完整性。参数的许多相关部分(陈述、它们在参数中的功能、推理规则、参数目标)在其非正式呈现中没有提到。参数分析师必须推断缺失的部分。
- 附加材料。除了严格属于参数的内容之外,非正式呈现通常还包含进一步的材料:相关前提以稍微不同的方式重复,进一步的例子被添加以说明一点,陈述与对手的观点形成对比等等。参数分析师必须选择哪些呈现的材料实际上是参数的一部分。
- 错误。作者在参数的呈现中可能出错,例如混淆了先决条件和充分条件在陈述前提中混淆。根据乐善好施的原则,仁慈的参数分析师纠正这种错误,并选择如何纠正这些错误的不同方式之一。
- 语言不确定性。同一陈述可以根据逻辑形式的不同方式进行解释。
- 等价性。一个命题可以有不同的自然语言表达。
AAAC数据集提供了非正式参数文本的逻辑重建:每个记录包含一个要重建的源文本以及描述文本解释的其他字段,尽管可能存在对这个具体文本的替代解释。
合成数据的构建
参数分析从一个文本开始,重建其参数(参见动机和背景)。在构建我们的合成数据时,我们将这个方向反过来:我们首先抽样一个完整的参数,构建一个非正式呈现,并提供进一步的信息,描述逻辑重建和非正式呈现。具体而言,数据的构建包括以下步骤:
我们通过系统地转变以下12个基本方案(命题逻辑和谓词逻辑各有6个)来构建可用推理方案的集合:
- 假言推理:['Fa->Gb','Fa','Gb']
- 链式规则:['Fa->Gb','Gb->Hc','Fa->Hc']
- 附加规则:['Fa','Gb','Fa & Gb']
- 案例分析:['Fa v Gb','Fa->Hc','Gb->Hc','Hc']
- 析取三段论:['Fa v Gb','¬Fa','Gb']
- 双向消除:['FaGb','Fa->Gb']
- 实例化:['(x):Fx->Gx','Fa->Ga']
- 假设三段论:['(x):Fx->Gx','(x):Gx->Hx','(x):Fx->Hx']
- 广义双向消除:['(x):FxGx','(x):Fx->Gx']
- 广义附加规则:['(x):Fx->Gx','(x):Fx->Hx','(x):Fx->(Gx & Hx)']
- 广义困境:['(x):Fx->(Gx v Hx','(x):Gx->Ix','(x):Hx->Ix','(x):Fx->Ix']
- 广义析取三段论:['(x):Fx->(Gx v Hx','(x):Fx->¬Gx','(x):Fx->Hx']
(关于命题方案,我们允许 a = b = c 。)
进一步的符号推理方案是通过对每个基本方案应用以下转换生成的:
- 否定:将所有原子命题的出现替换为其否定(任意数量的此类原子命题)
- 转置:转置一个(广义)条件
- 等效否定肯定:应用二重否定
- 复杂谓词:将给定原子命题的所有出现替换为由两个原子命题构成的合取或析取复合命题
- 德·摩根:应用德·摩根定律
这些转换按照以下顺序应用于基本方案:
{base_schemes} > negation_variants > transposition_variants > dna > {transposition_variants} > complex_predicates > negation_variants > dna > {complex_predicates} > de_morgan > dna > {de_morgan}
除了 dna ,所有转换都是单调的,即只是简单地在先前步骤生成的方案的基础上添加更多方案。加粗步骤的结果将被添加到有效的推理方案列表中。总体上,这给了我们5542个方案。
第2步:从符号推理方案中组装复杂的(“多跳”)参数方案复杂参数方案由多个推理组成,通过添加支持先前添加的推理的前提来组装,如以下伪代码所示:
argument = []
intermediary_conclusion = []
inference = randomly choose from list of all schemes
add inference to argument
for i in range(number_of_sub_arguments - 1):
target = randomly choose a premise which is not an intermediary_conclusion
inference = randomly choose a scheme whose conclusion is identical with target
add inference to argument
add target to intermediary_conclusion
return argument
我们创建的这些复杂参数是树状结构,其中一个根参数方案。
我们通过一个例证性示例来详细讲解此算法,并构建一个具有两个子参数的符号参数方案。首先,我们随机选择一些推理方案(随机抽样由权重控制,这些权重补偿了事实上,该列表主要包含出于组合原因而产生的复杂推理),比如:
{
"id": "mp",
"base_scheme_group": "modus ponens",
"scheme_variant": ["complex_variant"],
"scheme": [
["${A}${a} -> (${B}${a} & ${C}${a})",
{"A": "${F}", "B": "${G}", "C": "${H}", "a": "${a}"}],
["${A}${a}", {"A": "${F}", "a": "${a}"}],
["${A}${a} & ${B}${a}", {"A": "${G}", "B": "${H}", "a": "${a}"}]
],
"predicate-placeholders": ["F", "G", "H"],
"entity-placeholders": ["a"]
}
接下来,选择下一个子参数的目标前提(= 中间结论),例如:已添加的根参数方案的前提1。我们对适合目标结构上匹配的方案列表进行筛选,即其具有 ${A}${a}->(${B}${a} v ${C}${a}) 形式。在这个经过过滤的适合方案列表中,我们随机选择一个,例如:
{
"id": "bicelim",
"base_scheme_group": "biconditional elimination",
"scheme_variant": [complex_variant],
"scheme": [
["${A}${a} <-> (${B}${a} & ${C}${a})",
{"A": "${F}", "B": "${G}", "C": "${H}", "a": "${a}"}],
["${A}${a} -> (${B}${a} & ${C}${a})",
{"A": "${F}", "B": "${G}", "C": "${H}", "a": "${a}"}]
],
"predicate-placeholders": ["F", "G", "H"],
"entity-placeholders": []
}
因此,我们生成了以下具有两个前提、一个中间和一个最终结论的2步符号参数方案:
(1) Fa <-> Ga & Ha -- with biconditional elimination (complex variant) from 1 -- (2) Fa -> Ga & Ha (3) Fa -- with modus ponens (complex variant) from 2,3 -- (4) Ga & Ha
参数的一般属性现在已确定,并可以存储在数据集中(其领域是随机选择的):
"steps":2, // number of inference steps
"n_premises":2,
"base_scheme_groups":[
"biconditional elimination",
"modus ponens"
],
"scheme_variants":[
"complex variant"
],
"domain_id":"consumers_personalcare",
"domain_type":"persons"
第3步:创建(精确和非正式)自然语言参数方案 在第3步中,我们将符号和形式复杂参数方案转化为自然语言参数方案,将符号公式(例如,${A}${a} v ${B}${a} )替换为适当的自然语言句子方案(例如,${a}是${A},${a}是${B} 、${a}是${A}且${a}是${B} )。将自然语言句子方案分类为精确的、非正式的或不准确的,以控制参数方案的生成。对于每个符号公式,有许多(部分是自动生成的,部分是手动生成的)自然语言句子方案,可将公式理解为更或少精确的方式呈现。根据呈现的通用方法,为每个“翻译”符号公式的自然语言提供标签,例如:
| type | form |
|---|---|
| symbolic | (x): ${A}x -> ${B}x |
| precise | If someone is a ${A}, then they are a ${B}. |
| informal | Every ${A} is a ${B}. |
| imprecise | ${A} might be a ${B}. |
标签“precise”、“informal”和“imprecise”用于控制参数方案的生成,生成参数方案的精确版本(用于创建argdown片段)和非正式版本(用于创建源文本)。此外,自然语言的“翻译”还选择根据参数的领域(见下文)和该领域是以人(“每个人”,“没有人”)还是物体(“某物”,“没有东西”)为量化对象。例如:
因此,我们可能会得到以下作为我们的示例的精确描述的符号参数方案:
(1) If, and only if, a is a F, then a is G and a is a H. -- with biconditional elimination (complex variant) from 1 -- (2) If a is a F, then a is a G and a is a H. (3) a is a F. -- with modus ponens (complex variant) from 3,2 -- (4) a is G and a is a H.
同样,非正式描述可能是:
(1) a is a F if a is both a G and a H -- and vice versa. -- with biconditional elimination (complex variant) from 1 -- (2) a is a G and a H, provided a is a F. (3) a is a F. -- with modus ponens (complex variant) from 3,2 -- (4) a is both a G and a H.第4步:用特定领域谓词和名称替换占位符
每个参数都属于一个领域。领域提供
- 主体名称的列表(例如Peter,Sarah)
- 对象名称列表(例如New York,Lille)
- 二元断言的列表(例如[主体是] x的崇拜者)
这些领域是手动创建的。
占位符的替代品是从相应领域中抽样选择的。实体占位符(a,b等)的替代品只是从 subject names 列表中选择的。谓词占位符(F,G等)通过将 binary predicates 与 object names 组合而构造,得到了“___与某个对象存在关系”的一元断言。这种组合构造一元断言的方式极大地增加了可用替代品的数量,从而增加了生成参数的变化性。
假设我们从 consumers personal care 领域中抽样我们的参数,我们可以选择并构造以下占位符的替代品:
- F:Kiss My Face soap的常规消费者
- G:Nag Champa soap的常规消费者
- H:Shield soap的偶尔购买者
- a:Orlando
从自然语言参数方案的精确描述 (第3步) 和其占位符的替代 (第4步) ,我们通过简单的替换根据 argdown syntax 的构成方式和格式构建argdown片段。
这样得到我们上面示例的argdown_snippet:
(1) If, and only if, Orlando is a regular consumer of Kiss My Face soap,
then Orlando is a regular consumer of Nag Champa soap and Orlando is
a occasional purchaser of Shield soap.
--
with biconditional elimination (complex variant) from 1
--
(2) If Orlando is a regular consumer of Kiss My Face soap, then Orlando
is a regular consumer of Nag Champa soap and Orlando is a occasional
purchaser of Shield soap.
(3) Orlando is a regular consumer of Kiss My Face soap.
--
with modus ponens (complex variant) from 3,2
--
(4) Orlando is a regular consumer of Nag Champa soap and Orlando is a
occasional purchaser of Shield soap.
按照这种合成参量的方式,我们已经知道了其结论及其形式化的方法(explicit字段的值将在稍后确定)。
"conclusion":[
{
"ref_reco":4,
"text":"Orlando is a regular consumer of Nag Champa
soap and Orlando is a occasional purchaser of
Shield soap.",
"explicit": TBD
}
],
"conclusion_formalized":[
{
"ref_reco":4,
"form":"(${F2}${a1} & ${F3}${a1})"
}
],
"intermediary_conclusions":[
{
"ref_reco":2,
"text":"If Orlando is a regular consumer of Kiss My
Face soap, then Orlando is a regular consumer of
Nag Champa soap and Orlando is a occasional
purchaser of Shield soap.",
"explicit": TBD
}
]
"intermediary_conclusions_formalized":[
{
"ref_reco":2,
"text":"${F1}${a1} -> (${F2}${a1} & ${F3}${a1})"
}
],
...以及相应的键(参见第4步):
"plcd_subs":{
"a1":"Orlando",
"F1":"regular consumer of Kiss My Face soap",
"F2":"regular consumer of Nag Champa soap",
"F3":"occasional purchaser of Shield soap"
}
第6步:改写 根据自然语言参数方案的非正式描述 (第3步) 和其占位符的替代 (第4步) ,通过替换构建了一个自然语言参数(参数树)。
语句(前提、结论)会经过两个步骤进行改写:
对于每个语句,都有许多规则(对名词结构进行替换为动词结构,例如“是X的支持者”替换为“支持X”)可应用,这些规则尽可能地应用。接下来,每个语句将根据参数(由T5预测的cola和足够高的STSB值)生成的自动生成的改写替换,改写的概率由参数 lm_paraphrasing 指定。
| AAAC01 | AAAC02 | |
|---|---|---|
| lm_paraphrasing | 0.2 | 0. |
故事情节决定了以哪个顺序呈现前提、中间结论和最终结论在要构造的文本段落中(argument-source)。故事情节是由改写的非正式复杂参数(参见第6步)构建的。
为了确定呈现顺序(故事情节),非正式参数树在预处理之前进行以下处理
- 隐含前提
- 隐含的中间结论
- 隐含的最终结论
这些处理在数据集记录中记录如下:参数现象,参数索引,更复杂的参数索引,等。
为了将中间结论 C 作为隐含结论,将对 C 的推理“解析”,将 C 直接推导出的所有前提从推导 C 的参数中重新分配给推导结果的(最终或中间)结论。
原始树:
P1 ... Pn
—————————
C Q1 ... Qn
—————————————
C'
具有解析推理和隐含的中间结论的树:
P1 ... Pn Q1 ... Qn
———————————————————
C'
上面的示例中的原始参数树:
(1) ——— (2) (3) ——————— (4)
这可能经过预处理(通过解析第一步推理并删除第一个前提)处理为:
(3) ——— (4)
对于这样经过预处理的参数树,可以通过指定呈现的方向和起点来构造一个故事情节,从而确定呈现顺序。方向可以是:
- 正向(前提及...及前提,因此结论)
- 反向(结论由前提以...及前提)
预处理参数树中的任何结论都可以作为起点。然后,故事情节通过递归方式构建,如图1所示。节点的整数标签表示呈现的顺序,即故事情节。(请注意,起点不一定是根据故事情节首先呈现的陈述。)
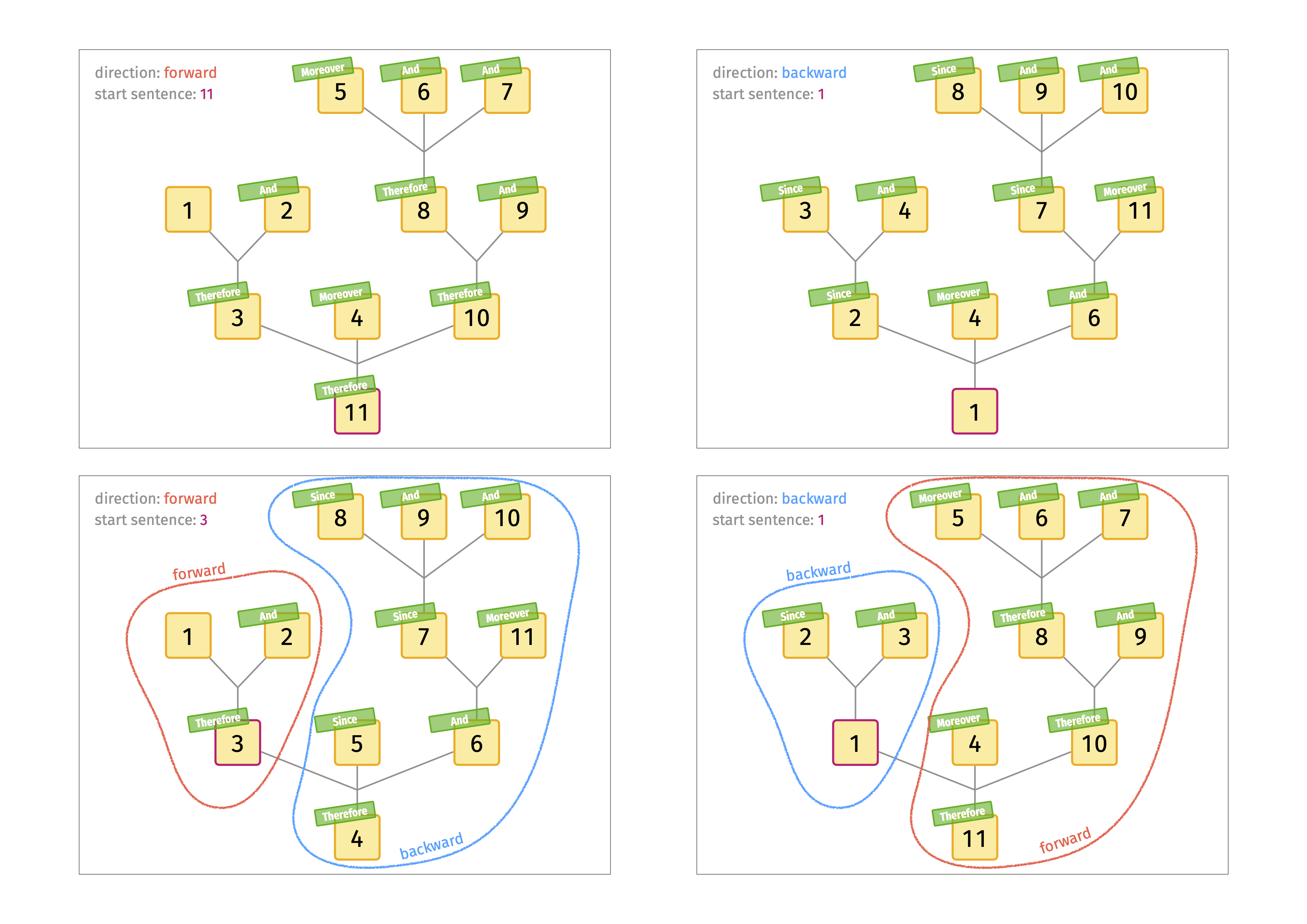
为了引入冗余,可以通过重复先前提出的陈述来对故事情节进行后处理。单个前提被重复的可能性由呈现参数控制:
"presentation_parameters":{
"redundancy_frequency":0.1,
}
此外,可以在故事情节中插入 distractors ,即从参数的领域中随机抽取的任意陈述。
第8步:组装参数源文本通过根据故事情节(第7步)的顺序为非正式参数的声明(结论或前提)连接语句来构建参数源文本(argument-source)。原则上,每个语句都以一个连词开头。有四种类型的连词:
- THEREFORE:从左到右的推断
- SINCE:从右到左的推断
- AND:将具有相似推理作用的前提连接起来
- MOREOVER:捕捉所有的连词
根据故事情节,每个语句都被分配一个特定的连词类型。
对于每种连词类型,我们提供了多个可能出现作为连接语句的自然语言术语,例如“因此,必然地,”,“所以”,“那么,”,“由此可见”,“由此,”,“因此,”,“因此,”,“因此,” ,“因此,”,“我们可以得出的结论是”,“从这可以得出的结论是”,“我们可以总结的是”,THEREFORE的案例。参数 presentation 参数确定省略连词、直接连接语句的概率。
"presentation_parameters":{
"drop_conj_frequency":0.1,
"...":"..."
}
使用上述参数,我们得到以下的参数源文本:
Orlando是Nag Champa肥皂的常规消费者,并且Orlando是Shield肥皂的偶尔购买者,因为Orlando是Kiss My Face肥皂的常规消费者。
第9步:链接非正式呈现和形式重建我们可以根据非正式呈现(argument-source)中的所有声明,根据逻辑重建对其进行分类,并将其链接到argdown_snippet 中相应的声明。我们区分理由声明(又名REASONS,对应重建中的前提)和结论声明(又名CONJECTURES,对应结论和中间结论):
"reason_statements":[ // aka reasons
{
"text":"Orlando is a regular consumer of Kiss My Face soap",
"starts_at":109,
"ref_reco":3
}
],
"conclusion_statements":[ // aka conjectures
{
"text":"Orlando is a regular consumer of Nag Champa soap and
Orlando is a occasional purchaser of Shield soap",
"starts_at":0,
"ref_reco":4
}
]
此外,现在我们可以根据非正式呈现将形式重建(argdown_snippet)中的所有前提分类为是否隐含或显式:
"premises":[
{
"ref_reco":1,
"text":"If, and only if, Orlando is a regular consumer of Kiss
My Face soap, then Orlando is a regular consumer of Nag
Champa soap and Orlando is a occasional purchaser of
Shield soap.",
"explicit":False
},
{
"ref_reco":3,
"text":"Orlando is a regular consumer of Kiss My Face soap. ",
"explicit":True
}
],
"premises_formalized":[
{
"ref_reco":1,
"form":"${F1}${a1} <-> (${F2}${a1} & ${F3}${a1})"
},
{
"ref_reco":3,
"form":"${F1}${a1}"
}
]
初始数据收集和规范化
N.A.
语言来源生产者是谁?N.A.
注释
注释过程N.A.
注释者是谁?N.A.
个人和敏感信息
N.A.
使用数据的注意事项
数据集的社会影响
无
偏见讨论
无
其他已知限制
请参阅 Betz and Richardson 2021 。
附加信息
数据集的策划者
Gregor Betz,Kyle Richardson
许可信息
Creative Commons cc-by-sa-4.0
引用信息
@misc{betz2021deepa2,
title={DeepA2: A Modular Framework for Deep Argument Analysis with Pretrained Neural Text2Text Language Models},
author={Gregor Betz and Kyle Richardson},
year={2021},
eprint={2110.01509},
archivePrefix={arXiv},
primaryClass={cs.CL}
}