

















数据集:
pierreguillou/DocLayNet-large



 英文
英文DocLayNet large 数据集卡片
关于此卡片(01/27/2023)
属性和许可证
除了这一段说明“关于这张卡片(01/27/2023)”外,此页面上的全部信息均从 Dataset Card for DocLayNet 复制/粘贴而来。
DocLayNet是由Deep Search(IBM Research)创建的数据集,发布在 license CDLA-Permissive-1.0 下。
我对从该数据集中获取的数据并发布在此页面上不声明任何权利。
DocLayNet数据集
DocLayNet dataset (IBM)提供了80863个来自6个文档类别的独特页面的逐页布局分割的边界框的基本事实标签。
直到今天,可以通过直接链接或作为数据集从Hugging Face数据集下载:
- 直接链接: doclaynet_core.zip (28 GiB), doclaynet_extra.zip (7.5 GiB)
- Hugging Face数据集库: dataset DocLayNet
论文: DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis (06/02/2022)
转换为HF笔记本可用格式的处理
这两个选项都需要下载全部数据(约30GBi),这需要下载时间(在Google Colab中约45分钟)和大硬盘空间。这可能会限制资源不足的人进行实验。
此外,即使使用HF数据集库的下载,也需要单独下载EXTRA zip( doclaynet_extra.zip ,7.5 GiB),以将OCR从PDF中提取的文本与注释的边界框相关联。该操作还需要附加代码,因为文本的边界框不一定对应那些已注释的边界框(通过计算注释的边界框与文本的边界框之间的公共区域百分比,可以对它们进行比较)。
最后,为了在使用LayoutLMv3或LiLT等微调布局模型的Hugging Face笔记本时使用DocLayNet数据,必须以适当的格式处理数据集。
出于所有这些原因,我决定处理DocLayNet数据集:
- 为不同大小的3个数据集:
- DocLayNet small (约占DocLayNet的1%)< 1,000个文档图像(691个训练,64个验证,49个测试)
- DocLayNet base (约占DocLayNet的10%)< 10,000个文档图像(6910个训练,648个验证,499个测试)
- DocLayNet large (约占DocLayNet的100%)< 100,000个文档图像(69,103个训练,6,480个验证,4,994个测试)
- 附带的文本和PDF(base64格式)
- 并使用Hugging Face笔记本易于使用的格式。
注意:HF笔记本将极大地帮助IBM的 ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents 参与者!
关于PDF语言
引用于 DocLayNet paper 的第3页:“我们没有根据语言控制文档选择。DocLayNet中的绝大多数文档(接近于95%)以英语发布。但是,DocLayNet还包含其他语言的一些文档,例如德语(2.5%),法语(1.0%)和日语(1.0%)。虽然文档语言对计算机视觉方法(例如对象检测和分割模型)的性能几乎没有影响,但却对利用文本特征进行布局分析的方法可能构成挑战。”
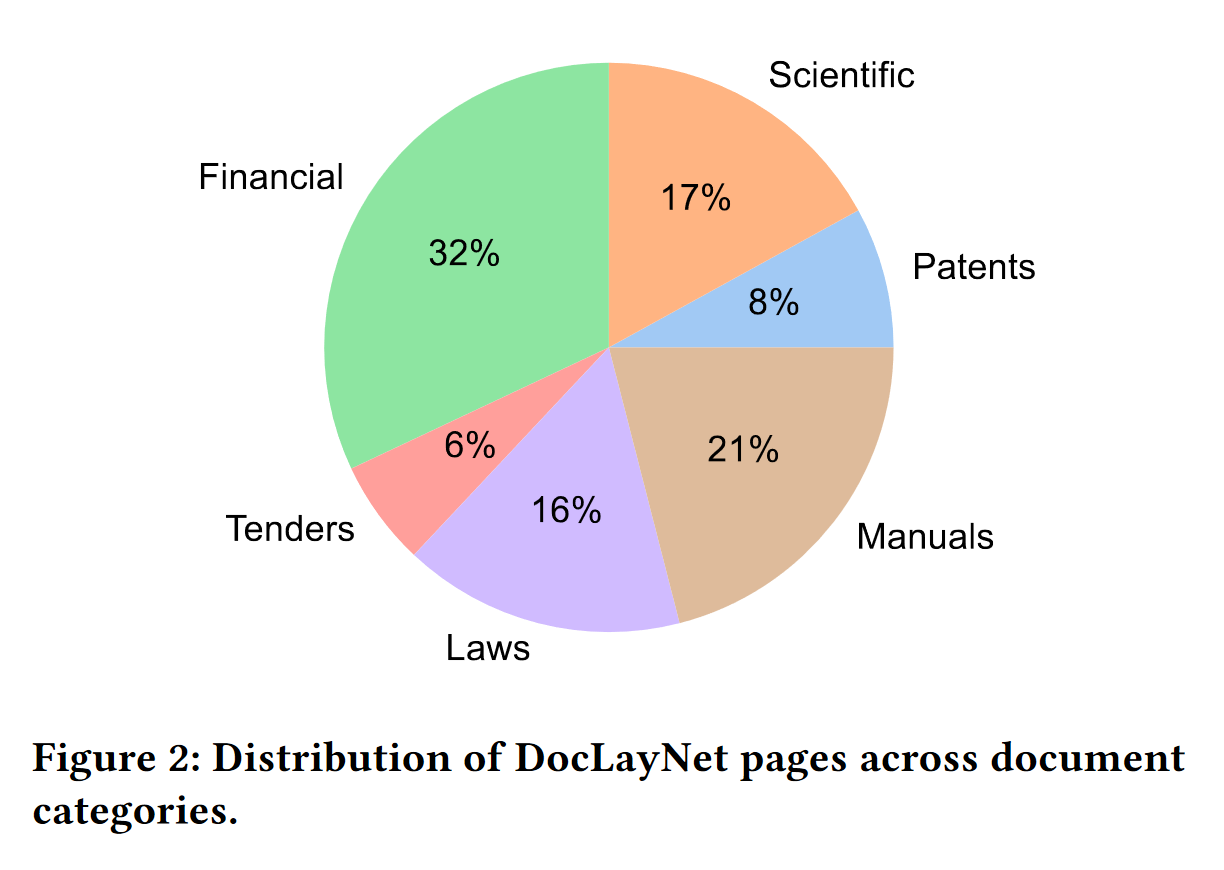
关于PDF类别分布
引用于 DocLayNet paper 的第3页:“DocLayNet中的页面可以分成六个不同的类别,即财务报告,手册,科学文章,法律法规,专利和政府招标。每个文档类别都来自不同的存储库。例如,财务报告包含自由风格格式的年度报告,其显示公司特定的艺术布局,以及更正式的SEC文件。两个最大的类别(财务报告和手册)包含大量自由风格布局,以获取最大的可变性。在其他四个类别中,我们通过混合来自独立提供者的文档(例如不同的政府网站或出版商)来增加可变性。在图2中,我们显示了包含在DocLayNet中的文档类别及其相应的大小。”
下载和概览
DocLayNet large的大小约为DocLayNet数据集的100%。
警告:以下代码可以下载DocLayNet large,但在Google Colab上由于存储缓存数据所需的空间和下载数据的CPU RAM而无法运行到最后(例如,下载过程中的/home/ubuntu/.cache/huggingface/datasets/中的缓存数据几乎需要120 GB)。甚至使用合适的实例,下载DocLayNet large数据集的时间约为1小时50分钟。这是测试您的微调代码的又一个原因,可以在 DocLayNet small 和/或 DocLayNet base 上进行测试?
# !pip install -q datasets
from datasets import load_dataset
dataset_large = load_dataset("pierreguillou/DocLayNet-large")
# overview of dataset_large
DatasetDict({
train: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 69103
})
validation: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 6480
})
test: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 4994
})
})
注释边界框
DocLayNet基础使得显示带有段落或行的已注释边界框的文档图像变得容易。
检查笔记本以获取代码 processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb 。
段落 行
行

HF笔记本
- notebooks LayoutLM (Niels Rogge)
- notebooks LayoutLMv2 (Niels Rogge)
- notebooks LayoutLMv3 (Niels Rogge)
- notebooks LiLT (Niels Rogge)
- Document AI: Fine-tuning LiLT for document-understanding using Hugging Face Transformers ( post 的Phil Schmid)
数据集摘要
DocLayNet为80863个独特页面上的11个不同类别的页面布局分割提供了逐页标记的边界框。与PubLayNet或DocBank等相关工作相比,它提供了几个独特的特点:
支持的任务和排行榜
我们正在基于DocLayNet数据集在ICDAR 2023上举办一项竞赛。有关更多信息,请参见 https://ds4sd.github.io/icdar23-doclaynet/ 。
数据集结构
数据字段
DocLayNet提供四种类型的数据资产:
COCO图像记录如下所示
...
{
"id": 1,
"width": 1025,
"height": 1025,
"file_name": "132a855ee8b23533d8ae69af0049c038171a06ddfcac892c3c6d7e6b4091c642.png",
// Custom fields:
"doc_category": "financial_reports" // high-level document category
"collection": "ann_reports_00_04_fancy", // sub-collection name
"doc_name": "NASDAQ_FFIN_2002.pdf", // original document filename
"page_no": 9, // page number in original document
"precedence": 0, // Annotation order, non-zero in case of redundant double- or triple-annotation
},
...
doc_category字段使用以下常量之一:
financial_reports, scientific_articles, laws_and_regulations, government_tenders, manuals, patents
数据拆分
数据集提供了三个拆分
- 训练集
- 验证集
- 测试集
数据集创建
注释
注释过程注释专家培训的标注指南可在 DocLayNet_Labeling_Guide_Public.pdf 处获取。
注释者是谁?注解是众包的。
其他信息
数据集策展人
该数据集由IBM Research的 Deep Search team 策展。您可以通过 deepsearch-core@zurich.ibm.com 与我们联系。
策展人:
- Christoph Auer, @cau-git
- Michele Dolfi, @dolfim-ibm
- Ahmed Nassar, @nassarofficial
- Peter Staar, @PeterStaar-IBM
许可信息
许可证: CDLA-Permissive-1.0
引文信息
@article{doclaynet2022,
title = {DocLayNet: A Large Human-Annotated Dataset for Document-Layout Segmentation},
doi = {10.1145/3534678.353904},
url = {https://doi.org/10.1145/3534678.3539043},
author = {Pfitzmann, Birgit and Auer, Christoph and Dolfi, Michele and Nassar, Ahmed S and Staar, Peter W J},
year = {2022},
isbn = {9781450393850},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
booktitle = {Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages = {3743–3751},
numpages = {9},
location = {Washington DC, USA},
series = {KDD '22}
}
贡献
感谢 @dolfim-ibm 和 @cau-git 添加此数据集。