

















数据集:
pierreguillou/DocLayNet-small



 英文
英文DocLayNet small 数据集卡片
关于此卡片 (01/27/2023)
属性和许可
除了这段话“关于此卡片 (01/27/2023)”之外,此页面上的所有信息都是从 Dataset Card for DocLayNet 复制粘贴而来的。
DocLayNet是由Deep Search (IBM Research)创建并发布的数据集,在 license CDLA-Permissive-1.0 许可下。
我不对从该数据集中提取的数据以及发布在本页面上的内容声称任何权利。
DocLayNet 数据集
DocLayNet dataset (IBM) 提供了80863个独特页面、6个文档类别下的11个不同类别标签的页面布局分割框,具体为页面级的布局细分。
到目前为止,该数据集可以通过直链下载或作为数据集从Hugging Face数据集进行下载:
- 直链: doclaynet_core.zip (28 GiB), doclaynet_extra.zip (7.5 GiB)
- Hugging Face数据集库: dataset DocLayNet
论文: DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis (06/02/2022)
转换为便于HF笔记本使用的格式
这两个选项都需要下载所有的数据(大约30GBi),这需要下载时间(在Google Colab中约45分钟)和大硬盘空间。这可能会限制资源有限的人进行实验的能力。
此外,即使使用通过HF数据集库下载,也需要单独下载额外的zip文件( doclaynet_extra.zip , 7.5 GiB),以便将OCR从PDF中提取的文本与注释的边界框关联起来。这个操作也需要额外的代码,因为文本的边界框不一定与其注释的边界框相对应(通过计算注释的边界框与文本的边界框的公共面积百分比可以进行比较)。
最后,为了在HF笔记本上使用LayoutLMv3或LiLT等微调布局模型,必须以适当的格式处理DocLayNet数据。
基于这些原因,我决定处理DocLayNet数据集:
- 将其分割为不同大小的3个数据集:
- DocLayNet small (DocLayNet的约1%) < 1.000k文档图像(691个训练,64个验证,49个测试)
- DocLayNet base (DocLayNet的约10%) < 10.000k文档图像(6910个训练,648个验证,499个测试)
- DocLayNet large (DocLayNet的约100%) < 100.000k文档图像(69.103个训练,6.480个验证,4.994个测试)
- 附带的文本和PDF(base64格式),
- 以及以便于HF笔记本使用的格式。
注:布局HF笔记本将极大地帮助IBM ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents 的参与者!
关于PDF语言
引用 DocLayNet paper 的第3页:“我们在文件选择时没有考虑语言。DocLayNet中绝大多数的文档(近95%)都是用英语发布的。然而,DocLayNet还包含一些其他语言的文档,如德语(2.5%),法语(1.0%)和日语(1.0%)。尽管文档语言对于计算机视觉方法(如目标检测和分割模型)的性能影响很小,但对于利用文本特征的布局分析方法来说可能会有挑战。”
关于PDF类别分布
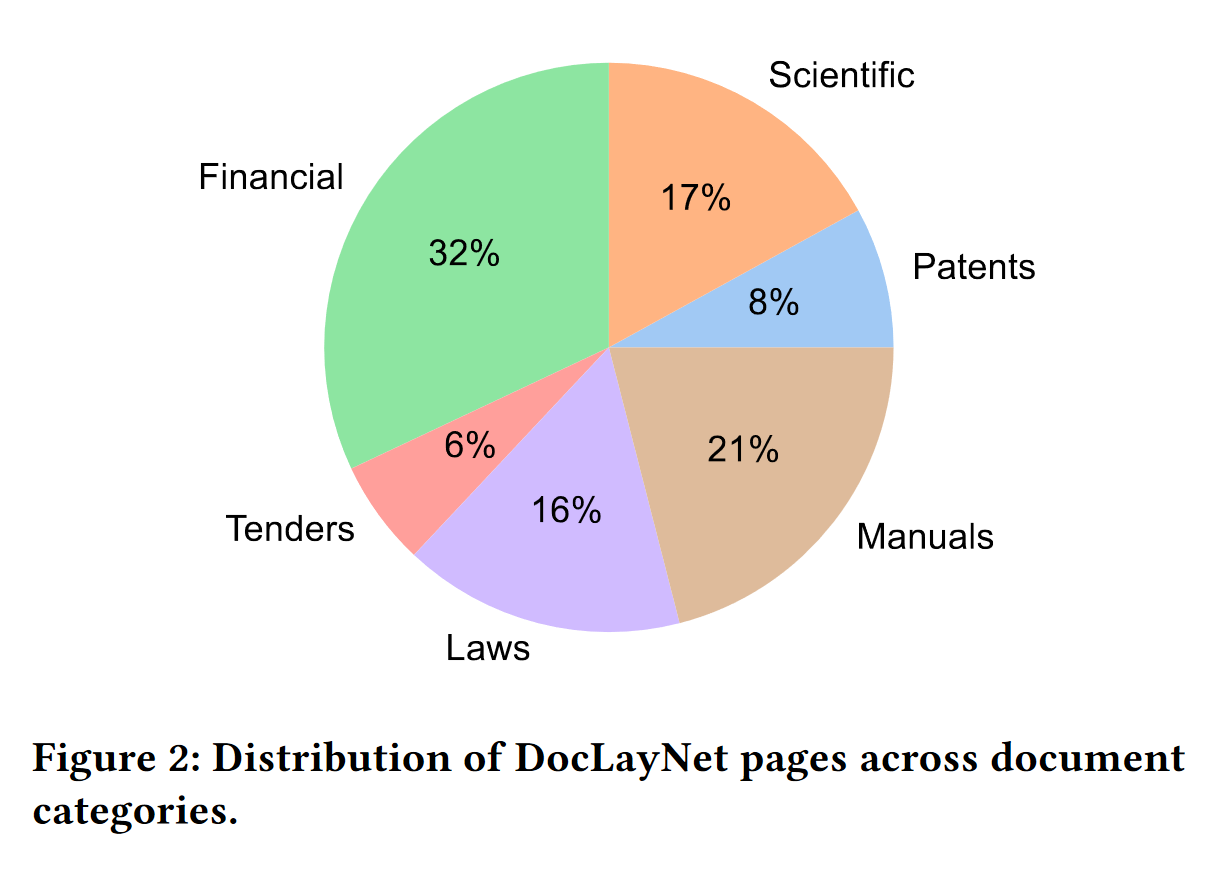
引用 DocLayNet paper 的第3页:“DocLayNet中的页面可以分为六个不同的类别,即财务报告、手册、科学文章、法律法规、专利和政府招标。每个文档类别都来自各个知识库。例如,财务报告既包含了以公司特定的艺术布局为特点的随意格式年度报告,也包含了更正式的SEC文件。最大的两个类别(财务报告和手册)包含了大量的随意布局,以便获得最大的变化性。在其他四个类别中,我们通过混合来自独立供应商(如不同政府网站或出版商)的文档来增加变化性。在图2中,我们展示了DocLayNet中包含的文档类别及其相应的大小。”
下载和概述
DocLayNet small 的大小约为DocLayNet数据集的1%(分别在训练、验证和测试文件中进行了随机选择)。
# !pip install -q datasets
from datasets import load_dataset
dataset_small = load_dataset("pierreguillou/DocLayNet-small")
# overview of dataset_small
DatasetDict({
train: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 691
})
validation: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 64
})
test: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 49
})
})
注释的边界框
DocLayNet的基础使得可以轻松显示带有段落或行注释的文档图像。
查看笔记本 processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb 以获取代码。
段落 行
行

HF笔记本
- notebooks LayoutLM (Niels Rogge)
- notebooks LayoutLMv2 (Niels Rogge)
- notebooks LayoutLMv3 (Niels Rogge)
- notebooks LiLT (Niels Rogge)
- Document AI: Fine-tuning LiLT for document-understanding using Hugging Face Transformers ( post of Phil Schmid)
数据集概述
DocLayNet提供了80863个独特页面、6个文档类别下的11个不同类别标签的页面级布局分割框的金标准数据,与相关的工作,如PubLayNet或DocBank相比,它提供了一些独特的特点:
支持的任务和排行榜
我们正在基于DocLayNet数据集在ICDAR 2023上举办一项竞赛。更多信息请参见 https://ds4sd.github.io/icdar23-doclaynet/ 。
数据集结构
数据字段
DocLayNet提供了四种类型的数据资产:
COCO图像记录的定义如下示例
...
{
"id": 1,
"width": 1025,
"height": 1025,
"file_name": "132a855ee8b23533d8ae69af0049c038171a06ddfcac892c3c6d7e6b4091c642.png",
// Custom fields:
"doc_category": "financial_reports" // high-level document category
"collection": "ann_reports_00_04_fancy", // sub-collection name
"doc_name": "NASDAQ_FFIN_2002.pdf", // original document filename
"page_no": 9, // page number in original document
"precedence": 0, // Annotation order, non-zero in case of redundant double- or triple-annotation
},
...
doc_category字段使用下列常量之一:
financial_reports, scientific_articles, laws_and_regulations, government_tenders, manuals, patents
数据拆分
该数据集提供了三个拆分
- 训练集
- 验证集
- 测试集
数据集创建
注释
注释过程训练注释专家使用的标签指南可在 DocLayNet_Labeling_Guide_Public.pdf 找到。
标注者是谁?注释是众包完成的。
附加信息
数据集策划者
该数据集由IBM Research的 Deep Search team 策划。您可以通过电子邮件deepsearch-core@zurich.ibm.com与我们联系。
策划者:
- Christoph Auer, @cau-git
- Michele Dolfi, @dolfim-ibm
- Ahmed Nassar, @nassarofficial
- Peter Staar, @PeterStaar-IBM
许可信息
许可证: CDLA-Permissive-1.0
引用信息
@article{doclaynet2022,
title = {DocLayNet: A Large Human-Annotated Dataset for Document-Layout Segmentation},
doi = {10.1145/3534678.353904},
url = {https://doi.org/10.1145/3534678.3539043},
author = {Pfitzmann, Birgit and Auer, Christoph and Dolfi, Michele and Nassar, Ahmed S and Staar, Peter W J},
year = {2022},
isbn = {9781450393850},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
booktitle = {Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages = {3743–3751},
numpages = {9},
location = {Washington DC, USA},
series = {KDD '22}
}
贡献
感谢 @dolfim-ibm 、 @cau-git 添加了此数据集。