

















数据集:
renumics/cifar100-enriched



 英文
英文CIFAR-100-Enriched(由Renumics增强)数据集卡
数据集概述
? Data-centric AI 实践越来越重要,适用于现实世界的用例。 在 Renumics ,我们认为应该扩展传统的基准数据集和竞赛来反映这一发展。
? 这就是为什么我们发布带有应用特定增强的基准数据集(例如嵌入、基准结果、不确定性、标签错误分数)。我们希望这能够以以下方式帮助机器学习社区:
? 这个数据集是 CIFAR-100 Dataset 的增强版本。
探索数据集
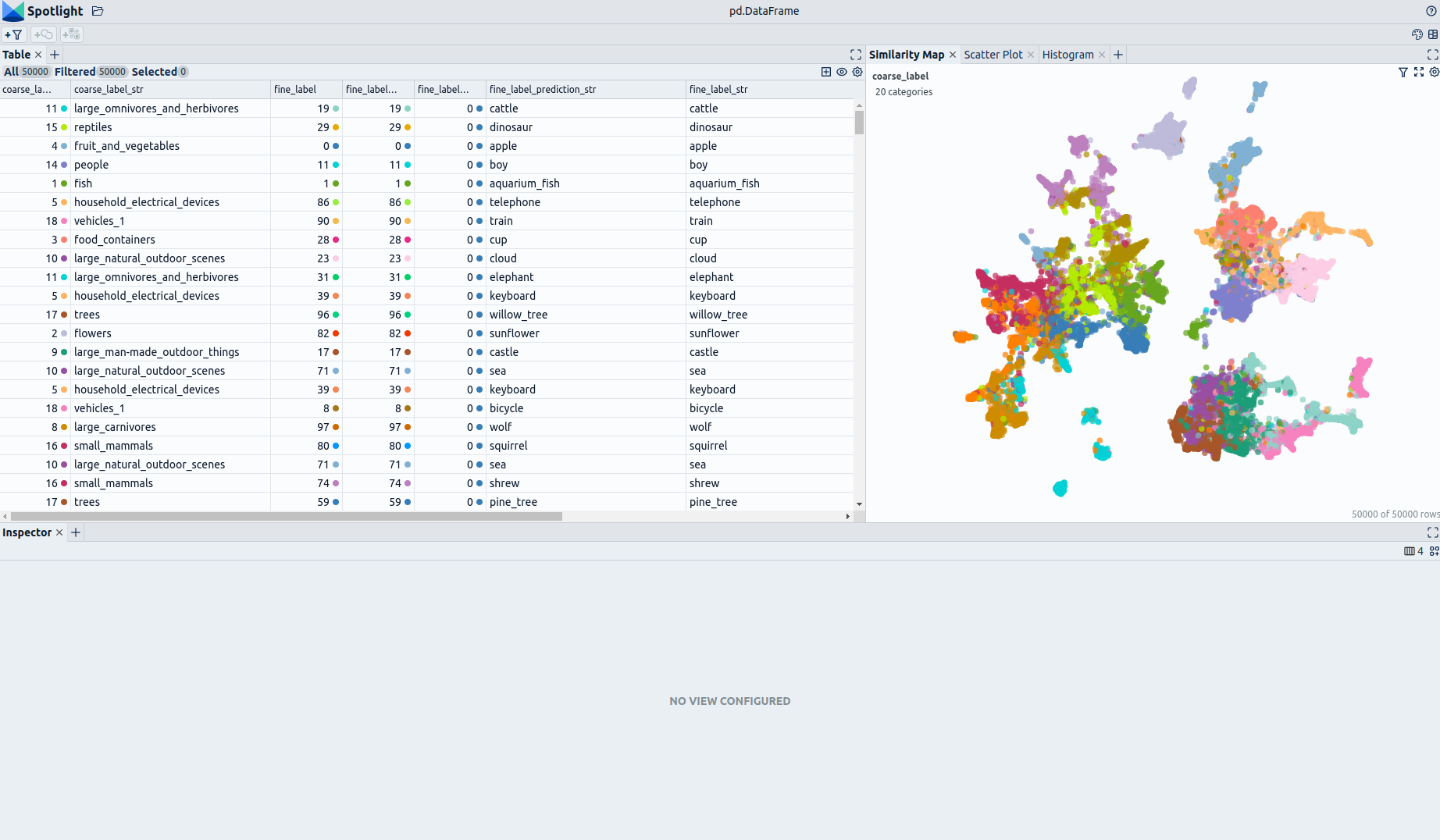
这些增强功能使您能够快速获得对数据集的洞察力。开源的数据整理工具 Renumics Spotlight 只需要几行代码就可以实现这一目标:
在笔记本中安装datasets和Spotlight:
!pip install renumics-spotlight datasets
在笔记本中从huggingface加载数据集:
import datasets
dataset = datasets.load_dataset("renumics/cifar100-enriched", split="train")
通过使用嵌入来识别相关数据片段,开始简单的探索视图:
from renumics import spotlight
df = dataset.to_pandas()
df_show = df.drop(columns=['embedding', 'probabilities'])
spotlight.show(df_show, port=8000, dtype={"image": spotlight.Image, "embedding_reduced": spotlight.Embedding})
您可以使用用户界面交互式地配置数据的视图。根据具体的任务(例如模型比较、调试、异常检测),您可能希望利用不同的增强功能和元数据。
CIFAR-100 数据集
CIFAR-100 数据集由60000个大小为32x32的彩色图像组成,包含100个类别,每个类别有600个图像。训练集中有50000个图像,测试集中有10000个图像。CIFAR-100中的100个类别分为20个超类。每个图像都有一个“fine”标签(它所属的类别)和一个“coarse”标签(它所属的超类)。这些类别完全互斥。我们通过添加使用 Vision Transformer 生成的图像嵌入来丰富数据集。以下是 CIFAR-100 中的类别列表:
| Superclass | Classes |
|---|---|
| aquatic mammals | beaver, dolphin, otter, seal, whale |
| fish | aquarium fish, flatfish, ray, shark, trout |
| flowers | orchids, poppies, roses, sunflowers, tulips |
| food containers | bottles, bowls, cans, cups, plates |
| fruit and vegetables | apples, mushrooms, oranges, pears, sweet peppers |
| household electrical devices | clock, computer keyboard, lamp, telephone, television |
| household furniture | bed, chair, couch, table, wardrobe |
| insects | bee, beetle, butterfly, caterpillar, cockroach |
| large carnivores | bear, leopard, lion, tiger, wolf |
| large man-made outdoor things | bridge, castle, house, road, skyscraper |
| large natural outdoor scenes | cloud, forest, mountain, plain, sea |
| large omnivores and herbivores | camel, cattle, chimpanzee, elephant, kangaroo |
| medium-sized mammals | fox, porcupine, possum, raccoon, skunk |
| non-insect invertebrates | crab, lobster, snail, spider, worm |
| people | baby, boy, girl, man, woman |
| reptiles | crocodile, dinosaur, lizard, snake, turtle |
| small mammals | hamster, mouse, rabbit, shrew, squirrel |
| trees | maple, oak, palm, pine, willow |
| vehicles 1 | bicycle, bus, motorcycle, pickup truck, train |
| vehicles 2 | lawn-mower, rocket, streetcar, tank, tractor |
支持的任务和排行榜
- 图像分类:这个任务的目标是将给定的图像分类到100个类别中的一个。排行榜可在 here 查看。
语言
英文类别标签。
数据集结构
数据实例
下面是训练集的一个样本:
{
'image': '/huggingface/datasets/downloads/extracted/f57c1a3fbca36f348d4549e820debf6cc2fe24f5f6b4ec1b0d1308a80f4d7ade/0/0.png',
'full_image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=32x32 at 0x7F15737C9C50>,
'fine_label': 19,
'coarse_label': 11,
'fine_label_str': 'cattle',
'coarse_label_str': 'large_omnivores_and_herbivores',
'fine_label_prediction': 19,
'fine_label_prediction_str': 'cattle',
'fine_label_prediction_error': 0,
'split': 'train',
'embedding': [-1.2482988834381104,
0.7280710339546204, ...,
0.5312759280204773],
'probabilities': [4.505949982558377e-05,
7.286163599928841e-05, ...,
6.577593012480065e-05],
'embedding_reduced': [1.9439491033554077, -5.35720682144165]
}
数据字段
| Feature | Data Type |
|---|---|
| image | Value(dtype='string', id=None) |
| full_image | Image(decode=True, id=None) |
| fine_label | ClassLabel(names=[...], id=None) |
| coarse_label | ClassLabel(names=[...], id=None) |
| fine_label_str | Value(dtype='string', id=None) |
| coarse_label_str | Value(dtype='string', id=None) |
| fine_label_prediction | ClassLabel(names=[...], id=None) |
| fine_label_prediction_str | Value(dtype='string', id=None) |
| fine_label_prediction_error | Value(dtype='int32', id=None) |
| split | Value(dtype='string', id=None) |
| embedding | Sequence(feature=Value(dtype='float32', id=None), length=768, id=None) |
| probabilities | Sequence(feature=Value(dtype='float32', id=None), length=100, id=None) |
| embedding_reduced | Sequence(feature=Value(dtype='float32', id=None), length=2, id=None) |
数据集划分
| Dataset Split | Number of Images in Split | Samples per Class (fine) |
|---|---|---|
| Train | 50000 | 500 |
| Test | 10000 | 100 |
数据集创建
理由
CIFAR-10 和 CIFAR-100 是 80 million tiny images 数据集的标记子集。它们由Alex Krizhevsky、Vinod Nair和Geoffrey Hinton收集。
源数据
初始数据收集和标准化需要更多信息
谁是源语言的生产者?需要更多信息
注释
注释过程需要更多信息
谁是注释人员?需要更多信息
个人和敏感信息
需要更多信息
使用数据的注意事项
数据的社会影响
需要更多信息
偏见讨论
需要更多信息
其他已知限制
需要更多信息
附加信息
数据集策划者
需要更多信息
许可信息
需要更多信息
引用信息
如果您使用这个数据集,请引用以下论文:
@article{krizhevsky2009learning,
added-at = {2021-01-21T03:01:11.000+0100},
author = {Krizhevsky, Alex},
biburl = {https://www.bibsonomy.org/bibtex/2fe5248afe57647d9c85c50a98a12145c/s364315},
interhash = {cc2d42f2b7ef6a4e76e47d1a50c8cd86},
intrahash = {fe5248afe57647d9c85c50a98a12145c},
keywords = {},
pages = {32--33},
timestamp = {2021-01-21T03:01:11.000+0100},
title = {Learning Multiple Layers of Features from Tiny Images},
url = {https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf},
year = 2009
}
贡献
Alex Krizhevsky、Vinod Nair、Geoffrey Hinton 和 Renumics GmbH。