

















数据集:
renumics/dcase23-task2-enriched


 英文
英文关于强化的“DCASE 2023挑战任务2数据集”的数据集卡片。
数据集概述
Data-centric AI 原则对现实世界的使用案例变得越来越重要。在 Renumics ,我们认为应该扩展经典的基准数据集和竞赛,以反映这一发展。
这就是为什么我们会发布具有应用特定增强(例如嵌入、基线结果、不确定性、标签错误分数)的基准数据集。我们希望这些能以以下方式帮助ML社区:
此数据集是 dataset 上下文中提供的 anomalous sound detection task 的 DCASE2023 challenge 的丰富版本。丰富包括由预训练的 Audio Spectrogram Transformer 生成的嵌入以及官方挑战 baseline implementation 的结果。
DCASE23任务2数据集
每年一次, DCASE community 发布了一个 challenge ,其中包含几个与声学事件检测和分类相关的任务。 Task 2 of this challenge 处理用于机器状态监测的异常声音检测。原始数据集基于 MIMII DG 和 ToyADMOS2 数据集。如果使用此数据集,请引用 Harada et al. 和 Dohi et al. 的论文,如果使用基线结果,请引用 Harada et al. 的论文。
探索数据集
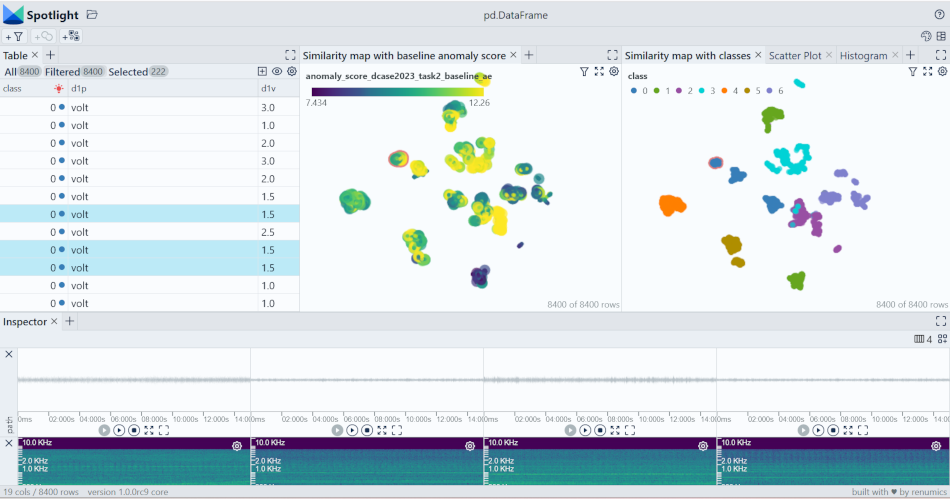
这些增强功能使您可以快速了解数据集。开源的数据处理工具Renumics Spotlight可以通过只需几行代码来实现:
通过 pip 安装数据集和Spotlight:
!pip install renumics-spotlight datasets[audio]
注意:在Linux上,libsndfile软件包的非Python依赖必须手动安装。有关更多信息,请参见 Datasets - Installation 。
在笔记本中从huggingface加载数据集:
import datasets
dataset = datasets.load_dataset("renumics/dcase23-task2-enriched", "dev", split="all", streaming=False)
从利用嵌入来识别相关数据片段的简单视图开始探索:
from renumics import spotlight
df = dataset.to_pandas()
simple_layout = datasets.load_dataset_builder("renumics/dcase23-task2-enriched", "dev").config.get_layout(config="simple")
spotlight.show(df, dtype={'path': spotlight.Audio, "embeddings_ast-finetuned-audioset-10-10-0.4593": spotlight.Embedding}, layout=simple_layout)
您可以使用UI与数据进行交互式配置视图。根据具体任务(如模型比较、调试、异常检测),您可能需要利用不同的增强功能和元数据。
在此示例中,我们专注于阀门类。我们特别关注在两个模型中具有高异常分数的正常数据点。这是一种寻找困难示例或边缘案例的方法之一:
from renumics import spotlight
extended_layout = datasets.load_dataset_builder("renumics/dcase23-task2-enriched", "dev").config.get_layout(config="extended")
spotlight.show(df, dtype={'path': spotlight.Audio, "embeddings_ast-finetuned-audioset-10-10-0.4593": spotlight.Embedding}, layout=extended_layout)

使用自定义模型结果和增强功能
在开发自定义模型时,您希望使用模型的不同类型信息(例如嵌入、异常分数等)来深入了解数据集和模型行为。
假设您的模型的嵌入为名为embeddings的2D Numpy数组,而异常分数为名为anomaly_scores的1D Numpy数组。然后您可以将此信息添加到数据集中:
df['my_model_embedding'] = embeddings df['anomaly_score'] = anomaly_scores
根据具体任务,您可能希望使用不同的增强功能。有关用于不确定性量化、可解释性和异常检测的伟大开源工具的完整概述,请查看我们在GitHub上的 curated list for open source data-centric AI tooling 。
您还可以通过单击相应的图标,将Spotlight中的视图配置保存在JSON配置文件中:

有关如何配置Spotlight UI的更多信息,请参阅 documentation 。
数据集结构
数据实例
对于每个实例,音频有一个表示路径的字符串,一个表示部分的整数,一个表示d1p(参数)的字符串,一个表示d1v(值)的字符串,一个表示标签的ClassLabel和一个表示类别的ClassLabel。
{'audio': {'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': 'train/fan_section_01_source_train_normal_0592_f-n_A.wav',
'sampling_rate': 16000
}
'path': 'train/fan_section_01_source_train_normal_0592_f-n_A.wav'
'section': 1
'd1p': 'f-n'
'd1v': 'A'
'd2p': 'nan'
'd2v': 'nan'
'd3p': 'nan'
'd3v': 'nan'
'domain': 0 (source)
'label': 0 (normal)
'class': 1 (fan)
'dev_train_lof_anomaly': 0
'dev_train_lof_anomaly_score': 1.241023
'add_train_lof_anomaly': 1
'add_train_lof_anomaly_score': 1.806289
'ast-finetuned-audioset-10-10-0.4593-embeddings': [0.8152204155921936,
1.5862374305725098, ...,
1.7154160737991333]
}
每个音频文件的长度为10秒。
数据字段
- 音频:一个datasets.Audio
- 路径:一个表示tar.gz存档中音频文件路径的字符串。
- 部分:表示部分的整数,参见定义
- d * p:表示d *参数名称的字符串
- d * v:表示相应的d *参数值的字符串
- 领域:一个整数,其值可以是0,表示音频样本来自源域;1,表示音频样本来自目标域。
- 类别:一个整数作为类别标签。
- 标签:一个整数,其值可以是0,表示音频样本是正常的;1,表示音频样本包含异常。
- '[X]_lof_anomaly':一个整数作为异常指示器。异常预测是使用基于"[X]"数据集的 Local Outlier Factor 算法计算的。
- '[X]_lof_anomaly_score':浮点数作为异常分数。异常分数是基于"[X]"数据集使用 Local Outlier Factor 算法计算的。
- embeddings_ast-finetuned-audioset-10-10-0.4593:表示生成的使用 Audio Spectrogram Transformer 的音频嵌入的datasets.Sequence(Value("float32"),shape =(1, 768))。
数据拆分
开发数据集有2个拆分:train和test。
| Dataset Split | Number of Instances in Split | Source Domain / Target Domain Samples |
|---|---|---|
| Train | 7000 | 6930 / 70 |
| Test | 1400 | 700 / 700 |
额外的训练数据集有1个拆分:train。
| Dataset Split | Number of Instances in Split | Source Domain / Target Domain Samples |
|---|---|---|
| Train | 7000 | 6930 / 70 |
评估数据集有1个拆分:test。
| Dataset Split | Number of Instances in Split | Source Domain / Target Domain Samples |
|---|---|---|
| Test | 1400 | ? |
数据集创建
以下信息来自原始的 dataset upload on zenodo.org
策展理由
此数据集是 DCASE 2023 Challenge Task 2 "First-Shot Unsupervised Anomalous Sound Detection for Machine Condition Monitoring" 的“开发数据集”。
数据包括七种类型的真实/玩具机器的正常/异常操作声音。每个录音都是一个包含机器运行声音和环境噪声的单声道10秒音频。在此任务中使用以下七种类型的真实/玩具机器:
- 玩具车
- 玩具火车
- 风扇
- 齿轮箱
- 轴承
- 滑轨
- 阀门
“额外的训练数据”和“评估数据”数据集包含以下类别:
- 木工锯
- 磨床
- 摇动器
- 玩具无人机
- 玩具N规模
- 玩具坦克
- 吸尘器
源数据
定义首先,我们定义本任务的关键术语:“机器类型”、“部分”、“源域”、“目标域”和“属性”。
- “机器类型”表示机器的类型,在开发数据集中为七种之一:风扇、齿轮箱、轴承、滑轨、阀门、玩具车和玩具火车。
- 部分被定义为用于计算性能指标的数据集的子集。
- 源域是大多数训练数据和一些测试数据记录的域,目标域是与一些训练数据和一些测试数据记录不同的一组域。源域和目标域在运行速度、机器负载、粘度、加热温度、环境噪声类型、信噪比等方面存在差异。
- 属性是定义机器状态或噪声类型的参数。
此数据集由七种机器类型组成。对于每种机器类型,提供一个部分,该部分是完整的训练和测试数据集。对于每个部分,此数据集提供(i)990个源域中的正常声音片段用于训练,(ii)10个目标域中的正常声音片段用于训练,以及(iii)每个测试正常和异常声音各100个片段。提供每个样本的源/目标域。此外,还在训练和测试数据中的文件名和属性csv文件中提供了每个样本的属性。
录制过程记录了机器和其相关设备的正常和异常操作声音。异常声音是通过故意损坏目标机器来收集的。为简化任务,我们仅使用多通道录音的第一个通道;所有录音被视为固定麦克风的单声道录音。我们将目标机器声音与环境噪声混合,而只提供有噪声的记录作为训练/测试数据。环境噪声样本是在几个真实工厂环境中录制的。我们将在提交截止日期之前发布有关录制过程细节的论文。
支持的任务和排行榜
异常声音检测(ASD)是识别来自目标机器的声音是正常还是异常的任务。通过观察声音进行机械故障的自动检测是第四次工业革命的重要技术,其中包括基于人工智能的工厂自动化。通过观察声音及时检测机器异常对于监测机器状态很有用。
这个任务是从DCASE 2020任务2到DCASE 2022任务2的后续任务。今年的任务是开发一个符合以下四个要求的ASD系统。
1. 仅使用正常声音进行模型训练(无监督学习场景)
由于异常很少发生且种类繁多,很难收集到详尽的异常声音模式。因此,系统必须检测未提供在训练数据中的未知类型异常声音。这与以前的任务要求相同。
2. 不受域偏移影响的异常检测(领域泛化任务)
在实际情况下,机器的运行状态或环境噪声可能发生变化,从而引起域偏移。领域泛化技术对于处理频繁发生或难以察觉的域偏移很有用。在此任务中,系统需要使用领域泛化技术来处理这些域偏移。这一要求与DCASE 2022任务2相同。
3. 为完全新的机器类型训练模型
对于完全新的机器类型,无法调整训练模型的超参数。因此,系统应具有在不需要额外超参数调整的情况下训练模型的能力。
4. 仅使用一个机器类型的一个机器训练模型
虽然可以使用同一机器类型的多个机器的声音来提高检测性能,但通常情况下只有一个机器的声音数据可用于机器类型。在这种情况下,系统应能够仅使用一个机器类型的一个机器进行模型训练。
使用数据的注意事项
数据集的社会影响
[需要更多信息]
偏见讨论
[需要更多信息]
其他已知限制
[需要更多信息]
其他信息
基线系统
基线系统可在Github库 dcase2023_task2_baseline_ae 上找到。基线系统为入门级方法提供了合理的性能,适用于任务2的数据集。这是一个很好的起点,特别是对于想要熟悉异常声音检测任务的入门级研究人员来说。
数据集策展人
[需要更多信息]
许可信息 - 使用条件
这是“DCASE 2023挑战任务2开发数据集”的特征/嵌入增强版本。 original dataset 由日立株式会社和NTT株式会社共同创建,并在Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International(CC BY-NC-SA 4.0)许可下提供。
引文信息(原始)
如果使用此数据集,请引用以下所有论文。我们将在DCASE 2023任务2上发布一篇论文,请务必引用该论文。
- Kota Dohi、Tomoya Nishida、Harsh Purohit、Ryo Tanabe、Takashi Endo、Masaaki Yamamoto、Yuki Nikaido和Yohei Kawaguchi。MIMII DG:用于故障工业机器调查和检查的声音数据集,用于领域泛化任务。在arXiv e-prints:2205.13879,2022年。[ URL ]
- Noboru Harada、Daisuke Niizumi、Daiki Takeuchi、Yasunori Ohishi、Masahiro Yasuda和Shoichiro Saito。ToyADMOS2:用于域偏移条件下的异常声音检测的另一个微型机器操作声音数据集。在第六届声学场景和事件检测和分类2021年研讨会(DCASE2021)论文集中(第1-5页)。巴塞罗那,西班牙,2021年11月。[ URL ]
- Noboru Harada、Daisuke Niizumi、Daiki Takeuchi、Yasunori Ohishi和Masahiro Yasuda。机器状态监测的一次探测异常检测:领域泛化基线。在arXiv e-prints:2303.00455,2023年。[ URL ]
@dataset{kota_dohi_2023_7882613,
author = {Kota Dohi and
Keisuke Imoto and
Noboru Harada and
Daisuke Niizumi and
Yuma Koizumi and
Tomoya Nishida and
Harsh Purohit and
Takashi Endo and
Yohei Kawaguchi},
title = {DCASE 2023 Challenge Task 2 Development Dataset},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {3.0},
doi = {10.5281/zenodo.7882613},
url = {https://doi.org/10.5281/zenodo.7882613}
}