

















数据集:
subjqa
任务:
 问答
问答
子任务:
extractive-qa语言:
 en
en
计算机处理:
monolingual大小:
1K<n<10K语言创建人:
found批注创建人:
expert-generated预印本库:
arxiv:2004.14283许可:
 license:unknown
license:unknown
 英文
英文subjqa数据集卡片
数据集概述
SubjQA是一个专注于主观(与客观相对)问题和回答的问答数据集。该数据集包含大约10,000个问题,涵盖来自6个不同领域的评论:图书、电影、杂货、电子产品、旅行者之家(即酒店)和餐厅。每个问题都与一篇评论配对,并且一个段落被突出显示为问题的答案(其中一些问题没有答案)。此外,注释者还为问题和答案段落分配了一个主观性标签。像“这个产品重量是多少?”这样的问题是客观问题(即低主观性),而“这个容易使用吗?”是一个主观问题(即高主观性)。
简而言之,SubjQA提供了一个研究提取式问答系统在查找不太事实的答案时表现如何以及建模主观性在何种程度上可以提高问答系统的性能的环境。
注:此数据集卡片上提供的许多信息都来自作者在其GitHub存储库中提供的README文件( link )。
要加载带有数据集的领域, 你可以运行以下命令:
from datasets import load_dataset
# other options include: electronics, grocery, movies, restaurants, tripadvisor
dataset = load_dataset("subjqa", "books")
支持的任务和排行榜
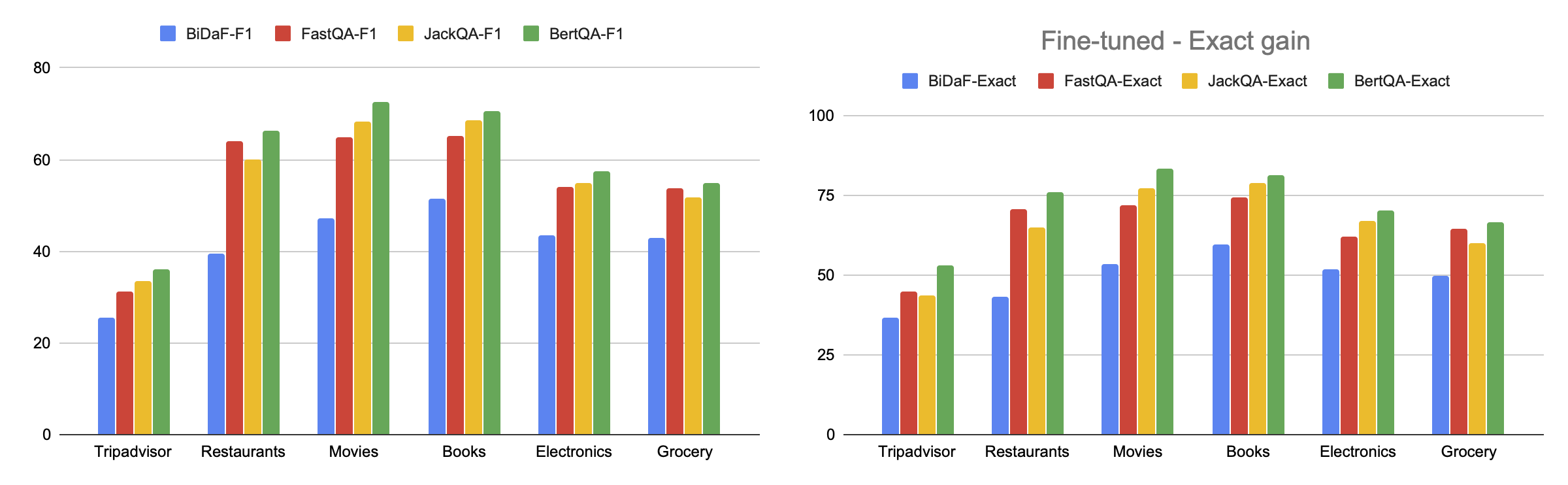
- question-answering : 数据集可用于训练提取式问答模型,其中涉及问题的答案可以在评论文本中标识为一个段落。该任务通常通过获得高精确匹配或F1分数来衡量成功。首先在SQuAD 2.0上进行BERT模型微调,然后在SubjQA数据集上进一步微调,可以达到下图所示的得分。
语言
数据集中的文本为英文,相关的BCP-47代码为en。
数据集结构
0数据实例
下面是books领域的一个例子:
{
"answers": {
"ans_subj_score": [1.0],
"answer_start": [324],
"answer_subj_level": [2],
"is_ans_subjective": [true],
"text": ["This is a wonderfully written book"],
},
"context": "While I would not recommend this book to a young reader due to a couple pretty explicate scenes I would recommend it to any adult who just loves a good book. Once I started reading it I could not put it down. I hesitated reading it because I didn't think that the subject matter would be interesting, but I was so wrong. This is a wonderfully written book.",
"domain": "books",
"id": "0255768496a256c5ed7caed9d4e47e4c",
"is_ques_subjective": false,
"nn_asp": "matter",
"nn_mod": "interesting",
"q_reviews_id": "a907837bafe847039c8da374a144bff9",
"query_asp": "part",
"query_mod": "fascinating",
"ques_subj_score": 0.0,
"question": "What are the parts like?",
"question_subj_level": 2,
"review_id": "a7f1a2503eac2580a0ebbc1d24fffca1",
"title": "0002007770",
}
数据字段
每个领域和拆分包括以下列:
- title : 讨论评论中的项目/商业的id。
- question : 问题(基于查询意见书写)。
- id : 分配给问题-评论配对的唯一id。
- q_reviews_id : 分配给所有具有共享问题的问题-评论配对的唯一id。
- question_subj_level : 问题的主观级别(在1到5的范围内,其中1为最主观)。
- ques_subj_score : 使用 TextBlob 软件包计算的问题的主观性得分。
- context : 评论(提到了相邻的意见)。
- review_id : 与评论相关联的唯一id。
- answers.text : 注释者标记为答案的段落。
- answers.answer_start : 注释者突出显示的答案段落的(字符级)起始索引。
- is_ques_subjective : 从question_subj_level派生的布尔主观性标签(即,得分低于4的问题被视为主观)。
- answers.answer_subj_level : 答案段落的主观级别(在1到5的范围内,其中5为最主观)。
- answers.ans_subj_score : 使用 TextBlob 软件包计算的答案段落的主观性得分。
- answers.is_ans_subjective : 从answer_subj_level派生的布尔主观性标签(即,得分低于4的答案被视为主观)。
- domain : 评论的类别/领域(例如酒店、图书等)。
- nn_mod : 相邻意见的修饰语(出现在评论中)。
- nn_asp : 相邻意见的方面(出现在评论中)。
- query_mod : 查询意见的修饰语(手动撰写问题的基础)。
- query_asp : 查询意见的方面(手动撰写问题的基础)。
数据拆分
每个领域的问题-评论配对被划分为训练、开发和测试集。下表显示了每个领域和拆分的数据集大小。
| Domain | Train | Dev | Test | Total |
|---|---|---|---|---|
| TripAdvisor | 1165 | 230 | 512 | 1686 |
| Restaurants | 1400 | 267 | 266 | 1683 |
| Movies | 1369 | 261 | 291 | 1677 |
| Books | 1314 | 256 | 345 | 1668 |
| Electronics | 1295 | 255 | 358 | 1659 |
| Grocery | 1124 | 218 | 591 | 1725 |
根据注释者提供的主观性标签,可以发现数据集中有73%的问题和74%的答案是主观的。这提供了大量主观性问答对以及相对合理数量的事实问题,可以比较和对比问答系统在每种类型的问答对上的表现。
最后,下表总结了每个类别的问题、评论和突出显示的答案段落的平均长度。
| Domain | Review Len | Question Len | Answer Len | % answerable |
|---|---|---|---|---|
| TripAdvisor | 187.25 | 5.66 | 6.71 | 78.17 |
| Restaurants | 185.40 | 5.44 | 6.67 | 60.72 |
| Movies | 331.56 | 5.59 | 7.32 | 55.69 |
| Books | 285.47 | 5.78 | 7.78 | 52.99 |
| Electronics | 249.44 | 5.56 | 6.98 | 58.89 |
| Grocery | 164.75 | 5.44 | 7.25 | 64.69 |
数据集创建
策划理由
大多数问题回答数据集(如SQuAD和自然问题)侧重于回答关于维基百科和新闻文章等事实数据的问题。然而,在电子商务等领域,问题和答案往往是主观的,即它们取决于用户的个人经验。例如,亚马逊上的客户可能会问“声音质量怎么样?”,这比一个事实性问题“澳大利亚的首都是什么?”更难回答。这些考虑因素促使创造SubjQA作为探索主观性和问题回答之间关系的工具。
源数据
初始数据收集和归一化SubjQA数据集是基于公开可得的评论数据集构建的。具体来说,“电影”、“图书”、“电子产品”和“杂货”类别是使用 Amazon Review dataset 的评论构建的。正如其名字所示,“旅行者之家”类别是使用来自TripAdvisor的评论构建的,可以在 here 中找到。最后,“餐厅”类别是使用 Yelp Dataset ,这也是公开可得的。
SubjQA的构建过程在 paper 中详细讨论。简而言之,数据集构造包括以下步骤:
下图显示了数据收集流程的可视化。
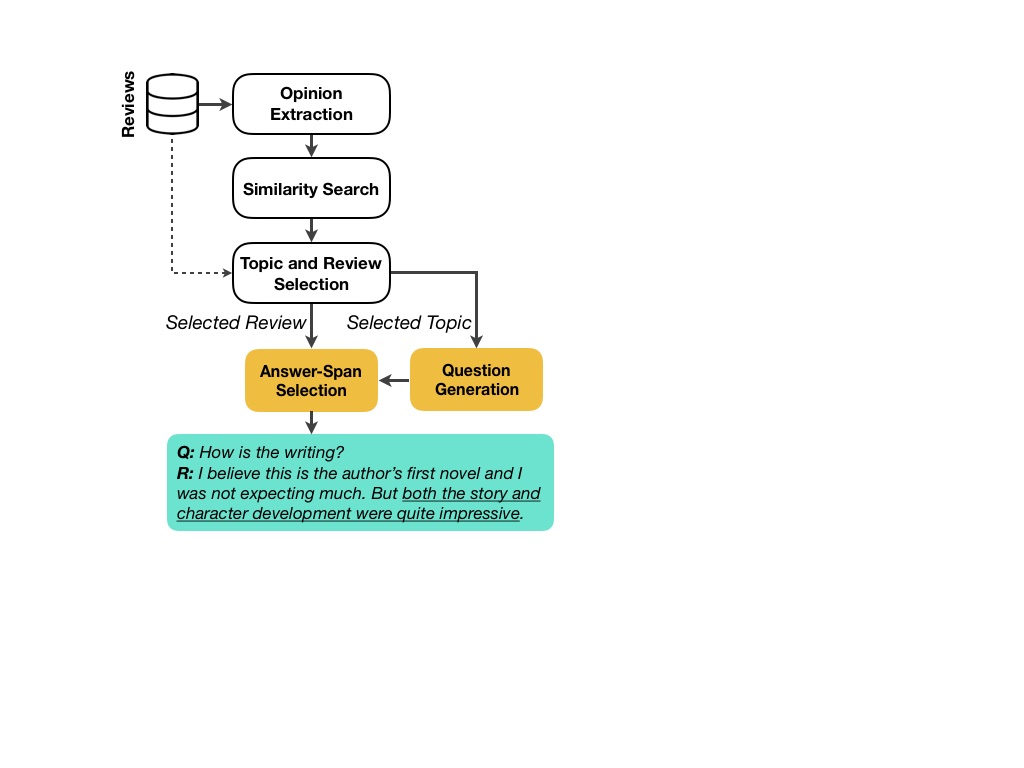 谁是源语言生产者?
谁是源语言生产者? 如上所述,SubjQA的源数据是关于电子商务网站(如亚马逊和TripAdvisor)上产品和服务的客户评论。
注释
注释过程生成问题和答案段落标签是通过 Appen 平台获得的。根据SubjQA论文:
该平台通过向工作者展示5个问题中的一个,并由专家标注,来提供质量控制。未能保持70%准确率的工作者将被平台拒之门外,并将忽略其判断...为确保优质标签,我们每个注释支付5美分给每个工作者。
生成问题所用的说明如下图所示:

类似地,答案段落和主观性标注任务的界面如下所示:
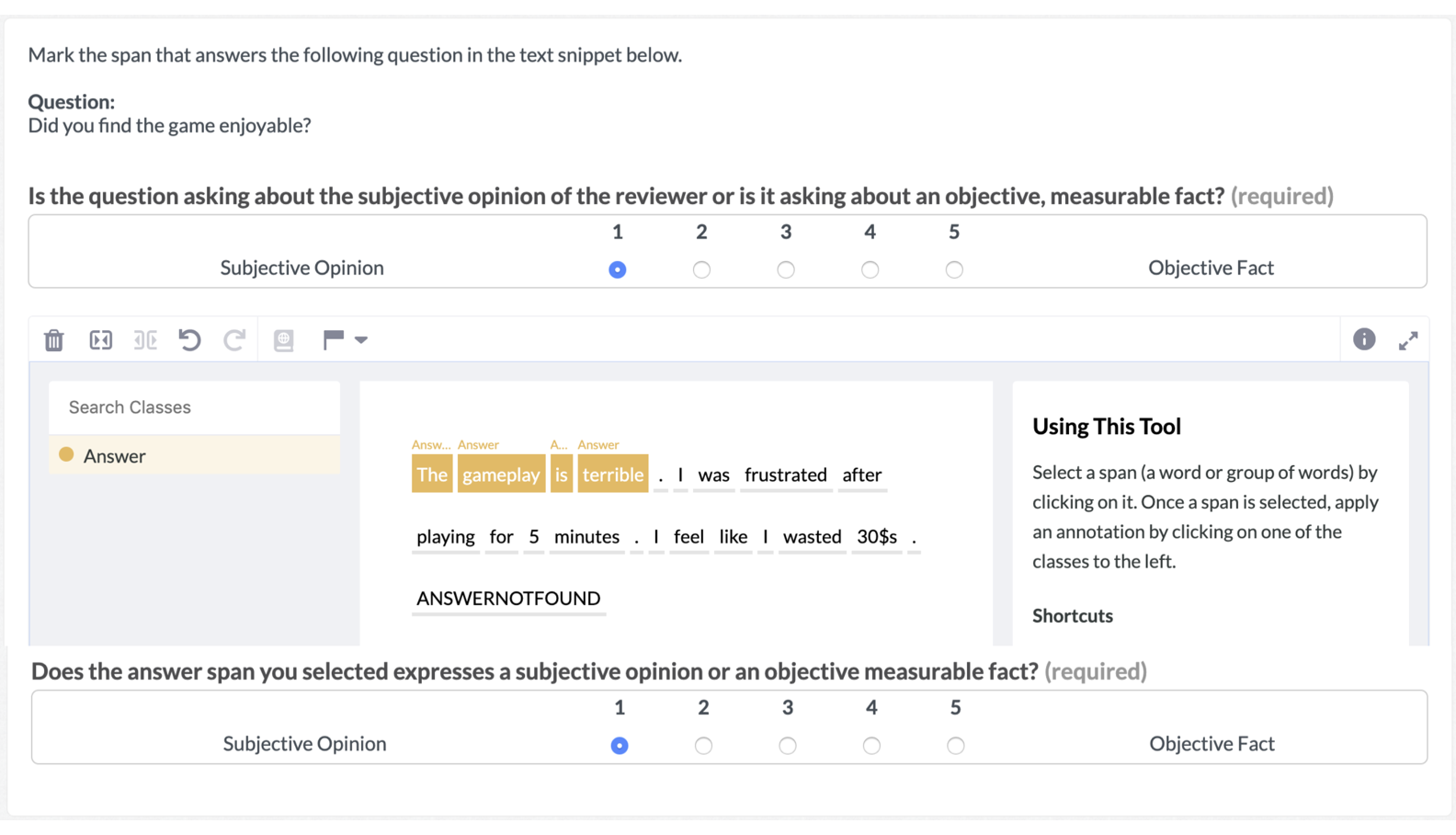
如SubjQA论文所述,工作者为每个问题和所选答案段落分别分配1-5的主观性得分。他们还可以指示某个问题不能从给定的评论中回答。
谁是注释者?Appen平台上的工作者。
个人和敏感信息
[需要更多信息]
使用数据的注意事项
数据集的社会影响
SubjQA数据集可用于开发问答系统,可以更好地回答对产品和服务的主观性问题感兴趣的电子商务客户的即时需求。
偏见讨论
[需要更多信息]
其他已知限制
[需要更多信息]
附加信息
数据集策划者
参与创建SubjQA数据集的人员是附属论文的作者:
- Johannes Bjerva1, Department of Computer Science, University of Copenhagen, Department of Computer Science, Aalborg University
- Nikita Bhutani, Megagon Labs, Mountain View
- Behzad Golshan, Megagon Labs, Mountain View
- Wang-Chiew Tan, Megagon Labs, Mountain View
- Isabelle Augenstein, Department of Computer Science, University of Copenhagen
许可信息
SubjQA数据集按原样提供,其创作者对其准确性不作任何陈述。
SubjQA数据集是基于以下数据集构建的,因此与其上构建的数据集的许可证相同地考虑其中的数据:
-
Amazon Review Dataset
来自UCSD
- 用于books、movies、grocery和electronics领域
-
The TripAdvisor Dataset
来自UIUC的数据库和信息系统实验室
- 用于TripAdvisor领域
-
The Yelp Dataset
- 用于restaurants领域
因此,SubjQA数据集中的每个领域的数据应与其所构建在之上的数据集一样受到相同的许可证的约束。
引用信息
如果您使用该数据集,请在您的工作中引用以下内容:
@inproceedings{bjerva20subjqa,
title = "SubjQA: A Dataset for Subjectivity and Review Comprehension",
author = "Bjerva, Johannes and
Bhutani, Nikita and
Golahn, Behzad and
Tan, Wang-Chiew and
Augenstein, Isabelle",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing",
month = November,
year = "2020",
publisher = "Association for Computational Linguistics",
}
贡献
感谢 @lewtun 添加这个数据集。