

















模型:
TheBloke/wizardLM-13B-1.0-GPTQ


 英文
英文
Chat & support: my new Discord server
Want to contribute? TheBloke's Patreon page
WizardLM 13B 1.0 GPTQ
这些文件是用于 WizardLM 13B 1.0 的GPTQ 4位模型文件。
这是将LoRA合并后使用 GPTQ-for-LLaMa 进行4位量化的结果。
其他可用的存储库
- 4-bit GPTQ models for GPU inference
- 4-bit, 5-bit and 8-bit GGML models for CPU(+GPU) inference
- Merged, unquantised fp16 model in HF format
提示模板
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: prompt goes here ASSISTANT:
如何轻松下载并在文本生成Web界面中使用此模型
像往常一样打开文本生成Web界面。
提供的文件
WizardLM-13B-1.0-GPTQ-4bit-128g.no-act-order.safetensors
这将与GPTQ-for-LLaMa的所有版本兼容。它具有最高的兼容性。
它使用groupsize 128创建,以确保更高质量的推断,没有-act-order参数以最大限度地提高兼容性。
- WizardLM-13B-1.0-GPTQ-4bit-128g.no-act-order.safetensors
- 适用于GPTQ-for-LLaMa代码的所有版本,包括Triton和CUDA分支
- 适用于AutoGPTQ
- 适用于一键安装的文本生成Web界面
- 参数:Groupsize = 128. 无行动顺序。
- 用于创建GPTQ的命令:
python llama.py /workspace/process/wizardLM-13B-1.0/HF wikitext2 --wbits 4 --true-sequential --groupsize 128 --save_safetensors /workspace/process/wizardLM-13B-1.0/gptq/WizardLM-13B-1.0-GPTQ-4bit-128g.no-act-order.safetensors
Discord
如需进一步支持和讨论这些模型和AI相关的内容,请加入我们的社群:
感谢和如何贡献
感谢 chirper.ai 团队!
我已经有很多人询问是否可以贡献。我喜欢提供模型和帮助人们,希望能有更多时间做这件事,同时也希望扩展到新的项目,如微调/训练。
如果您有能力和意愿进行贡献,我将非常感激,并将帮助我继续提供更多模型,并开始新的AI项目。
捐赠者将享有对任何和所有AI/LLM/模型问题和请求的优先支持,可以进入私人Discord房间,以及其他好处。
- Patreon: https://patreon.com/TheBlokeAI
- Ko-Fi: https://ko-fi.com/TheBlokeAI
Patreon特别致谢:Aemon Algiz,Dmitriy Samsonov,Nathan LeClaire,Trenton Dambrowitz,Mano Prime,David Flickinger,vamX,Nikolai Manek,senxiiz,Khalefa Al-Ahmad,Illia Dulskyi,Jonathan Leane,Talal Aujan,V. Lukas,Joseph William Delisle,Pyrater,Oscar Rangel,Lone Striker,Luke Pendergrass,Eugene Pentland,Sebastain Graf,Johann-Peter Hartman。
感谢所有慷慨的赞助者和捐赠者!
原始模型卡片:WizardLM 13B 1.0
WizardLM: 使用Evol-Instruct的指令跟随LLM
增强大型预训练语言模型以遵循复杂的指令

新闻
目前,我们的核心贡献者正在准备33B版本,并希望使WizardLM能够自行执行指令演化,以最低成本演化您的特定数据。
- 🔥我们发布了13B版的WizardLM,在ShareGPT的250k演化指令上进行了训练。请下载我们的Delta模型,地址如下: Demo_13B 、 Demo_13B_bak 和GPT-4评估。
- 🔥我们发布了70k演化指令版本的7B版WizardLM(来自Alpaca数据)。请查看 paper 和 Demo_7B 、 Demo_7B_bak 。
- 📣我们正在寻找高度积极的学生以创建更加智能的AI。请联系caxu@microsoft.com
对于13B模型的使用注意事项:为了获得与我们演示完全相同的结果,请严格遵循“src/infer_wizardlm13b.py”中提供的提示和调用方法来使用我们的13B模型进行推断。不同于7B模型,13B模型采用了Vicuna的提示格式,并支持多轮对话。
对于演示用途的注意事项:我们只推荐使用英文来体验我们的模型。对其他语言的支持将在未来引入。演示目前仅支持单轮对话。
GPT-4自动评估
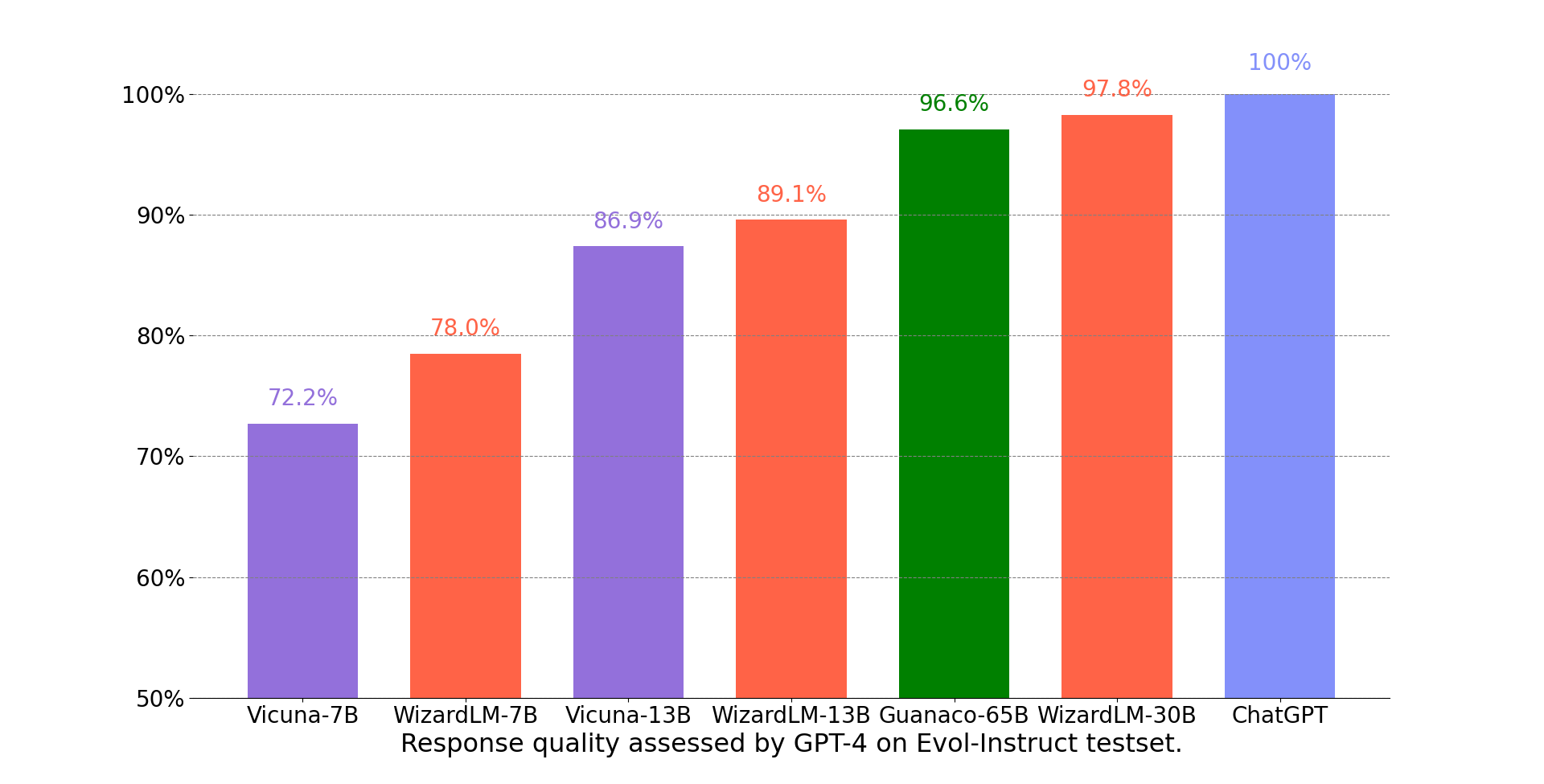
我们采用了FastChat提出的基于GPT-4的自动评估框架来评估聊天机器人模型的性能。如下图所示,WizardLM-13B的性能优于Vicuna-13b。
WizardLM-13B在不同技能上的性能。
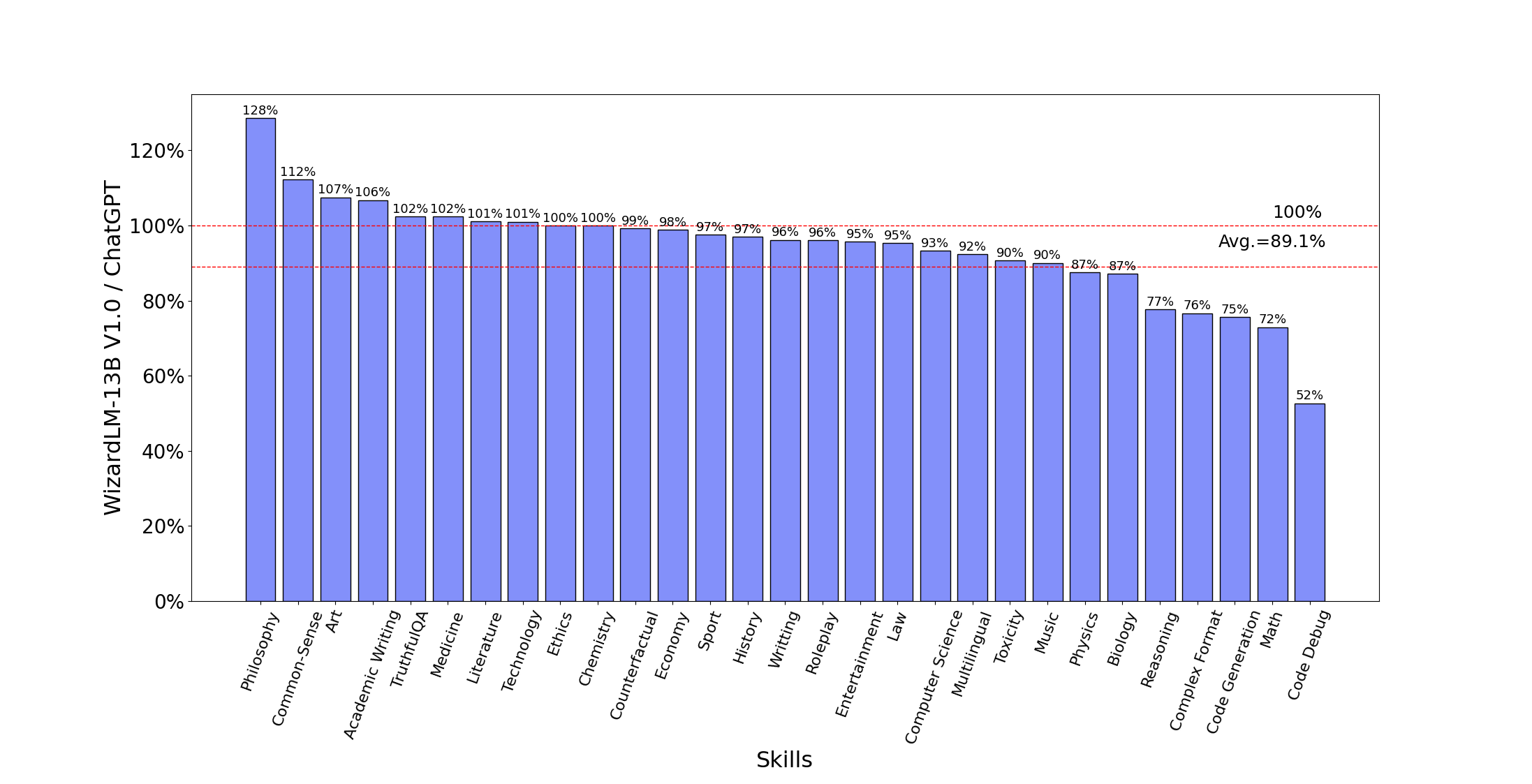
下图比较了WizardLM-13B和ChatGPT在Evol-Instruct测试集上的技能。结果表明,WizardLM-13B在平均性能上达到了ChatGPT的89.1%,在10个技能中几乎达到100%(或更多),在22个技能中达到90%以上的能力。
反馈征集
欢迎大家使用您的专业和困难的指令来评估WizardLM,并向我们展示性能差的示例以及您对此的建议。我们正在专注于改进Evol-Instruct,希望在WizardLM的下一个版本中解决现有的弱点和问题。之后,我们将公开最新的Evol-Instruct算法代码和流程,并与您共同改进它。
非官方视频介绍
感谢热心的朋友,他们的视频介绍更加生动有趣。
案例展示
我们只随机抽取了一些案例,以展示WizardLM和ChatGPT在不同难度的数据上的性能,请参阅 Case Show 了解详细信息。
Evol-Instruct概述
Evol-Instruct是一种使用LLM而不是人类,以自动批量生产各种难度水平和技能范围的开放域指令的新方法,以提高LLM的性能。
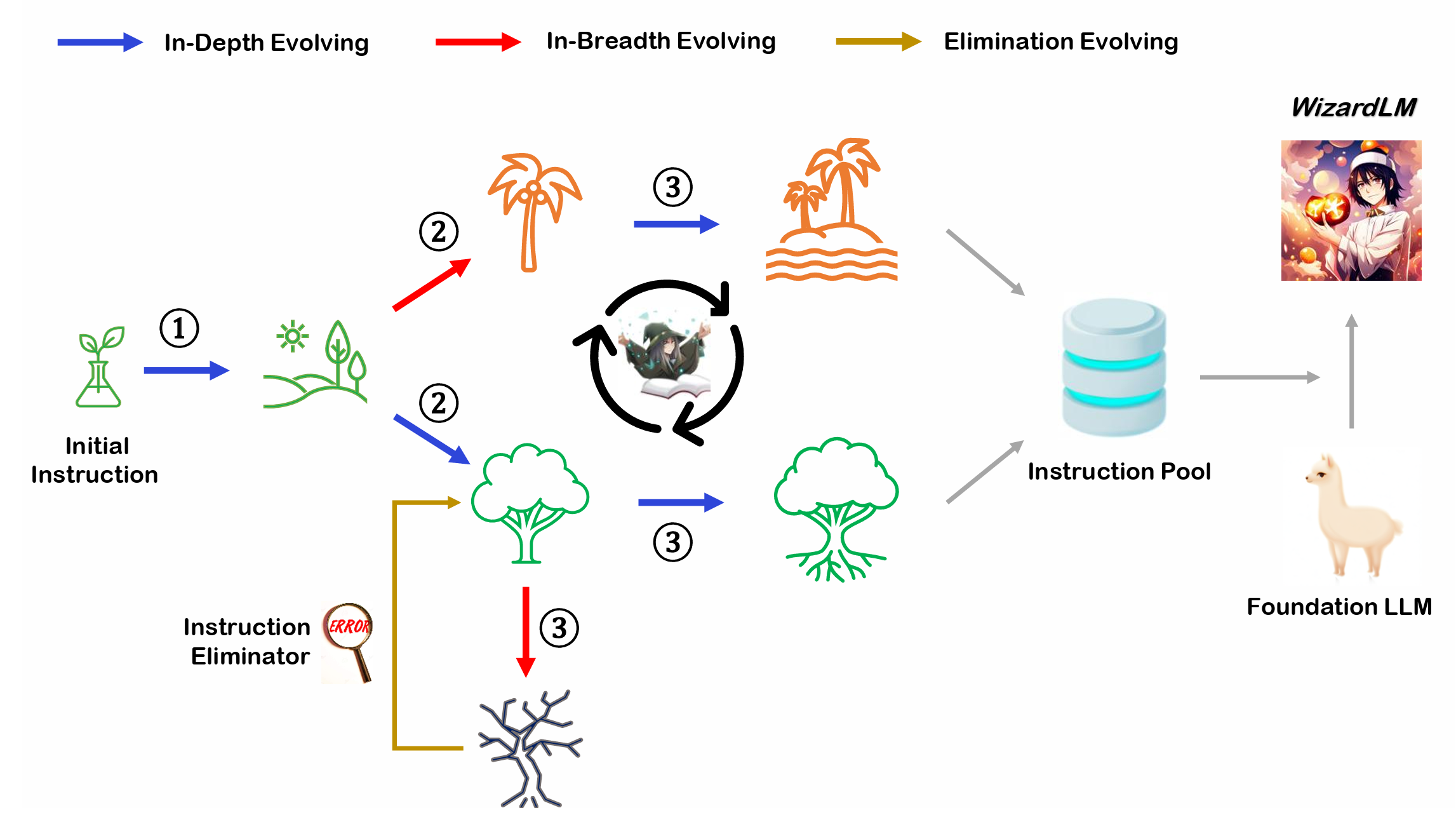
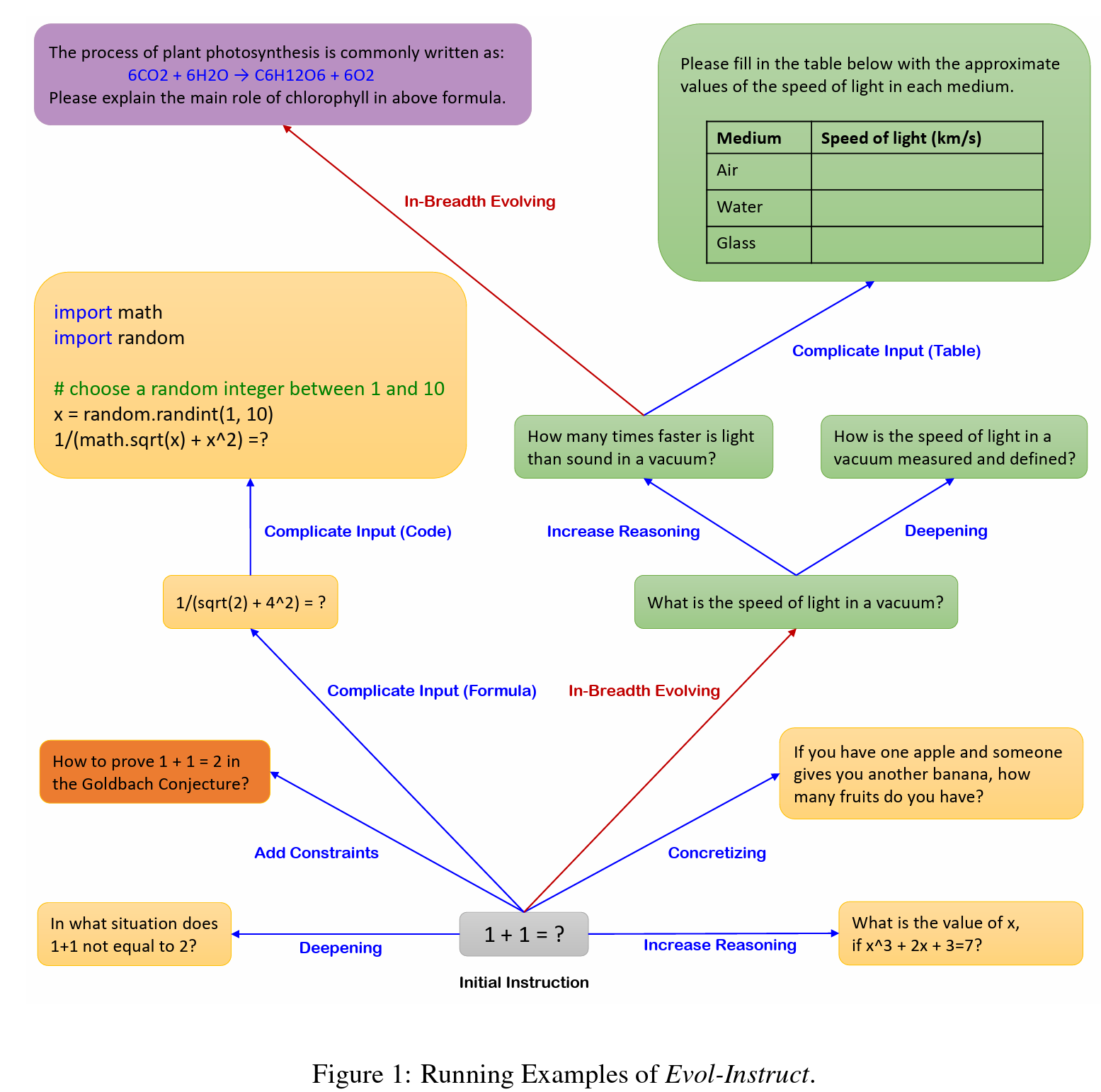
内容
在线演示
训练数据
WizardLM权重
微调
分布式微调
推断
评估
引用
声明
在线演示
我们将尽可能长时间地为您提供最新的模型。如果链接无效,请尝试其他链接。同时,请尽可能多地尝试在工作和生活中遇到的真实世界和具有挑战性的问题。我们将根据您的反馈不断改进我们的模型。
训练数据
alpaca_evol_instruct_70k.json 包含了Evol-Instruct生成的70k个指令跟随数据。我们用它来对WizardLM模型进行微调。这个JSON文件是一个字典列表,每个字典包含以下字段:
- instruction : str ,描述模型应执行的任务。每个70k个指令都是唯一的。
- output : str ,由gpt-3.5-turbo生成的对指令的响应。
WizardLM权重
我们以Delta权重的形式发布[WizardLM]权重,以符合LLaMA模型许可协议。您可以将我们的Delta添加到原始的LLaMA权重中以获得WizardLM权重。操作步骤:
python src/weight_diff_wizard.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
微调
我们使用 Llama-X 的代码对WizardLM进行微调。我们使用以下超参数对LLaMA-7B和LLaMA-13B进行微调:
| Hyperparameter | LLaMA-7B | LLaMA-13B |
|---|---|---|
| Batch size | 64 | 384 |
| Learning rate | 2e-5 | 2e-5 |
| Epochs | 3 | 3 |
| Max length | 2048 | 2048 |
| Warmup step | 2 | 50 |
| LR scheduler | cosine | cosine |
要复现我们对WizardLM的微调,请按照以下步骤进行:
deepspeed train_freeform.py \
--model_name_or_path /path/to/llama-7B/hf \
--data_path /path/to/alpaca_evol_instruct_70k.json \
--output_dir /path/to/wizardlm-7B/hf/ft \
--num_train_epochs 3 \
--model_max_length 2048 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 800 \
--save_total_limit 3 \
--learning_rate 2e-5 \
--warmup_steps 2 \
--logging_steps 2 \
--lr_scheduler_type "cosine" \
--report_to "tensorboard" \
--gradient_checkpointing True \
--deepspeed configs/deepspeed_config.json \
--fp16 True
分布式微调
请参阅 分布式微调
推断
我们提供用于WizardLM的解码脚本,该脚本读取输入文件并为每个样本生成相应的响应,最后将它们整合到一个输出文件中。
您可以在src\inference_wizardlm.py中指定base_model、input_data_path和output_data_path来设置解码模型、输入文件路径和输出文件路径。解码命令如下:
python src\inference_wizardlm.py
评估
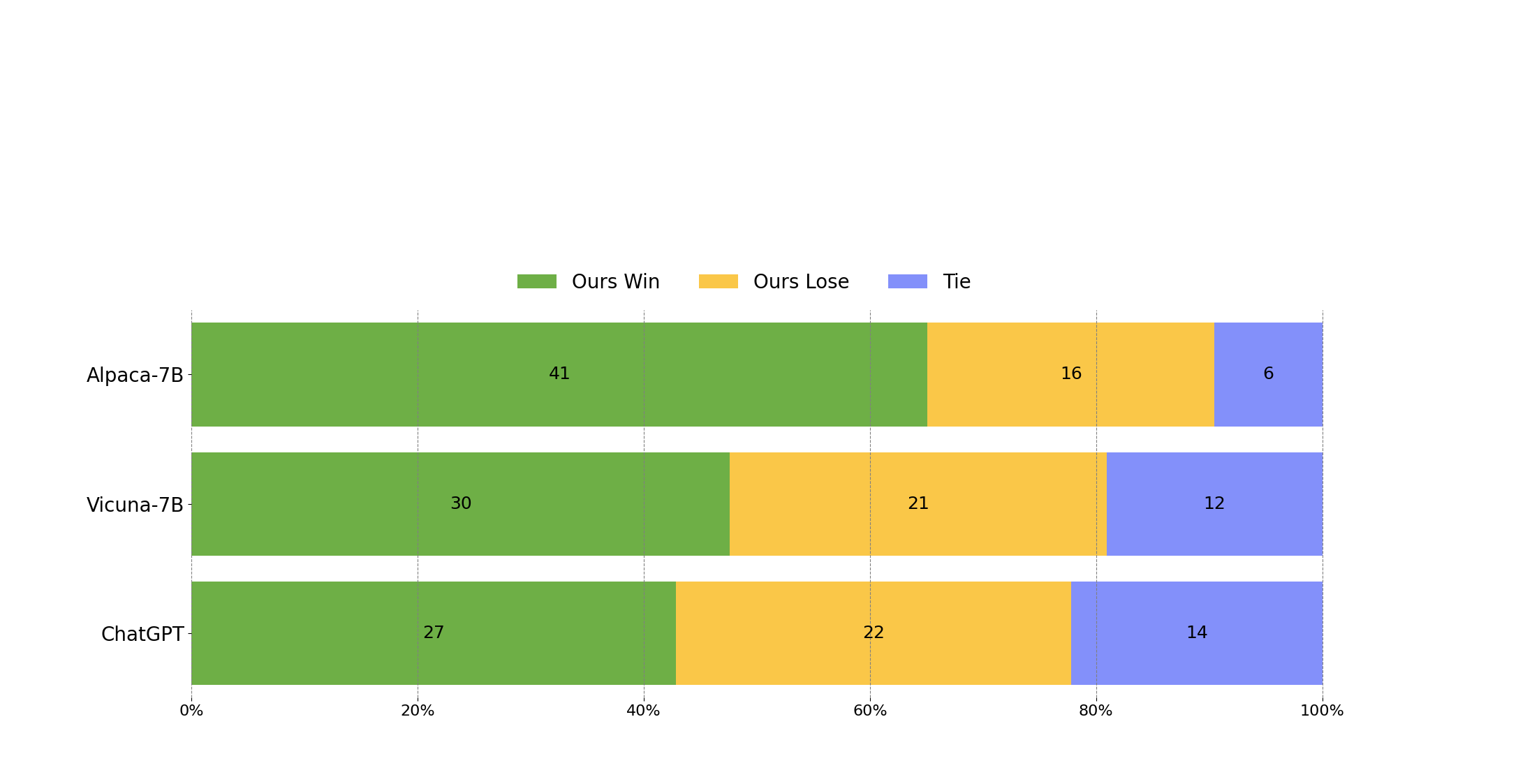
为了评估Wizard,我们在我们的人类指令评估集合WizardLM_testset.jsonl上进行人工评估。这个评估集合是由作者收集的,涵盖了各种用户导向的复杂指令,包括困难的编码生成和调试、数学、推理、复杂格式、学术写作、广泛的学科等。我们对Wizard和基准模型进行了对比评估。具体来说,我们招募了10名受过良好教育的标注者,对模型的相关性、知识水平、推理能力、计算能力和准确性进行了盲目的成对比较评级。
WizardLM的表现明显优于Alpaca和Vicuna-7b。
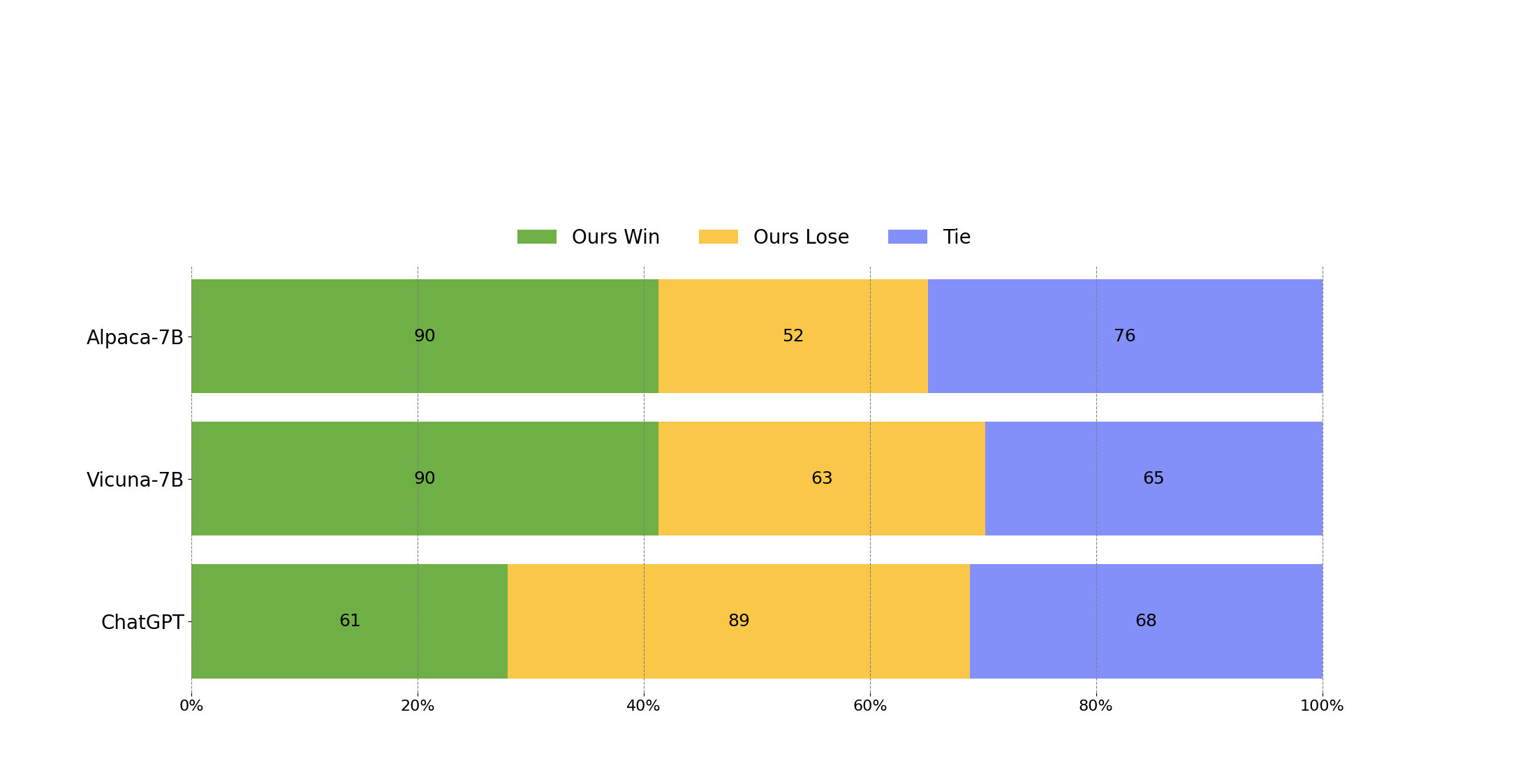
在我们的测试集的高难度部分(难度级别>= 8),WizardLM甚至超过了ChatGPT,在胜率上比Chatgpt高7.9%(42.9%对35.0%)。这表明我们的方法可以显著提高大型语言模型处理复杂指令的能力。
引用
如果您在此库中使用数据或代码,请引用该repo。
@misc{xu2023wizardlm,
title={WizardLM: Empowering Large Language Models to Follow Complex Instructions},
author={Can Xu and Qingfeng Sun and Kai Zheng and Xiubo Geng and Pu Zhao and Jiazhan Feng and Chongyang Tao and Daxin Jiang},
year={2023},
eprint={2304.12244},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
声明
与该项目相关的资源,包括代码、数据和模型权重,仅限于学术研究目的,不能用于商业目的。任何版本的WizardLM生成的内容都受到无法控制的变量(如随机性)的影响,因此,不能保证输出的准确性。此项目对模型输出的内容不承担任何法律责任,对使用相关资源和输出结果造成的任何损失不承担责任。