

















模型:
Yale-LILY/lever-spider-codex
任务:
 文生文
文生文
许可:
 apache-2.0
apache-2.0
 英文
英文LEVER (for Codex on Spider)
这是 "LEVER: Learning to Verify Language-to-Code Generation with Execution" 论文中的一个模型。
作者: Ansong Ni ,Srini Iyer,Dragomir Radev,Ves Stoyanov,Wen-tau Yih,Sida I. Wang*,Xi Victoria Lin*
注意:此特定模型适用于 Spider 数据集上的Codex,有关在其他数据集上预训练的模型,请参见:
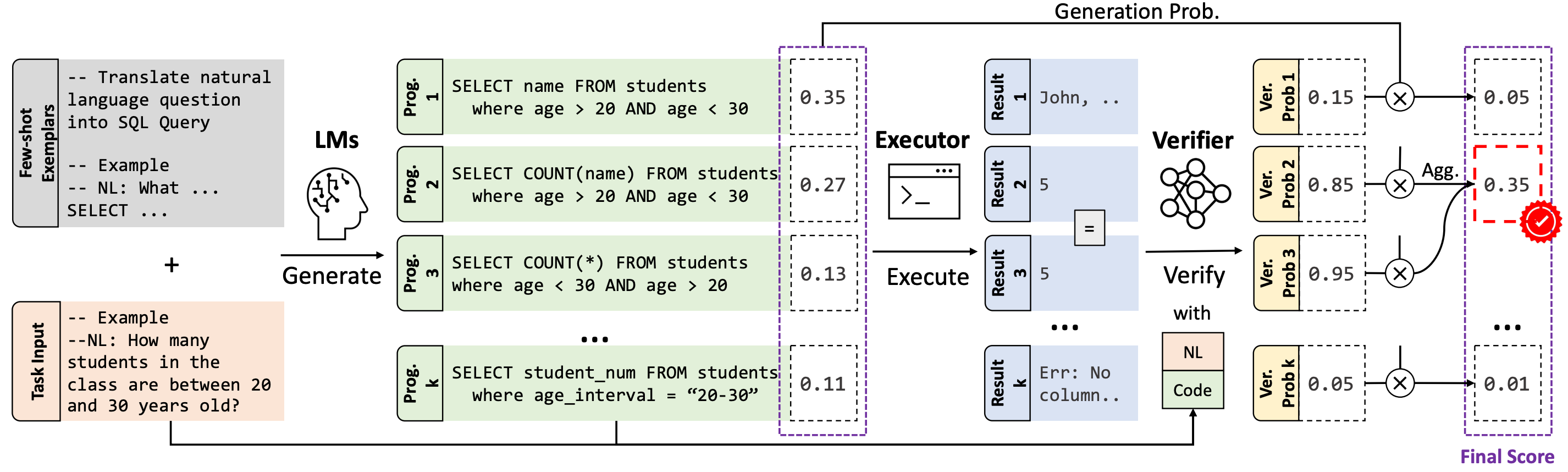
模型详情
模型描述
预训练代码语言模型(Code LLMs)的出现在语言到代码生成方面取得了重大进展。这一领域的最新方法将CodeLM解码与使用测试用例或基于执行结果的启发式方法进行样本修剪和重新排名相结合。然而,对于许多现实世界的语言到代码应用程序,获得测试用例是具有挑战性的,并且启发式方法不能很好地捕捉到执行结果的语义特征,例如数据类型和值范围,这经常表示程序的正确性。在这项工作中,我们提出了LEVER,一种简单的方法,通过学习使用执行结果来验证生成的程序来改进语言到代码生成。具体而言,我们训练验证器根据自然语言输入、程序本身和其执行结果来确定从CodeLM中采样得到的程序是否正确。采样得到的程序的重新排名是通过将验证分数与CodeLM的生成概率结合,并对具有相同执行结果的程序进行边际化。在表格QA、数学QA和基本Python编程领域的四个数据集上,LEVER始终优于基础CodeLM(使用code-davinci-002时提高了4.6%至10.9%),并在所有数据集上实现了新的最优结果。
开发者:耶鲁大学和Meta AI
共享者[可选]:安宋·尼
模型类型:文本分类
语言(自然语言处理):需要更多信息
许可证:Apache-2.0
父模型:T5-base
-
更多信息资源:
用途
直接使用
该模型不适用于直接使用。LEVER用于验证和重新排名由代码LLMs(例如Codex)生成的程序。我们建议查看我们的 Github Repo 以了解更多详细信息。
下游应用
LEVER被用于验证和重新排名从不同任务的代码LLMs中采样的程序。具体而言,对于lever-spider-codex,它是在 Spider 数据集上的code-davinci-002的输出上进行训练的。它可以用于对Codex生成的SQL程序进行重新排序。此外,它还可以应用于其他模型在Spider数据集上的输出,如 Original Paper 中所研究的那样。
超出范围的使用
该模型不应用于故意创建对人有敌意或使人感到孤立的环境。
偏见、风险和局限性
已经进行了大量研究探讨语言模型的偏见和公平性问题(例如, Sheng et al. (2021) 和 Bender et al. (2021) )。该模型生成的预测结果可能包含针对受保护类别、身份特征以及敏感的社会和职业群体的令人不安和有害的刻板印象。
建议
用户(直接和下游)应了解模型的风险、偏见和局限性。需要更多信息以提供进一步的建议。
训练详情
训练数据
该模型是使用code-davinci-002模型在 Spider 数据集上的输出进行训练的。
训练过程
从Spider数据集的训练示例中从Codex模型中提取出20个程序样本,然后执行这些程序以获得执行信息。对于每个示例及其程序样本,自然语言描述和执行信息也是用于训练基于T5的模型预测验证标签“是”或“否”的输入的一部分。
预处理
请按照 Github Repo 中的说明进行复现结果。
速度、大小、时间
需要更多信息
评估
测试数据、因素和指标
测试数据
Spider 数据集的开发集。
因素
需要更多信息
指标
执行准确率(pass@1)
结果
Spider文本到SQL生成
| Exec. Acc. | |
|---|---|
| Codex | 75.3 |
| Codex+LEVER | 81.9 |
模型检查
需要更多信息
环境影响
可以使用 Machine Learning Impact calculator 在 Lacoste et al. (2019) 中提出的方法估算碳排放量。
- 硬件类型:需要更多信息
- 使用时间:需要更多信息
- 云提供商:需要更多信息
- 计算区域:需要更多信息
- 排放的碳:需要更多信息
技术规格[可选]
模型架构和目标
lever-spider-codex基于T5-base。
计算基础设施
需要更多信息
硬件
需要更多信息
软件
需要更多信息。
引用
BibTeX:
@inproceedings{ni2023lever,
title={Lever: Learning to verify language-to-code generation with execution},
author={Ni, Ansong and Iyer, Srini and Radev, Dragomir and Stoyanov, Ves and Yih, Wen-tau and Wang, Sida I and Lin, Xi Victoria},
booktitle={Proceedings of the 40th International Conference on Machine Learning (ICML'23)},
year={2023}
}
术语表[可选]
需要更多信息
更多信息[可选]
需要更多信息
模型卡片作者和联系方式
Ansong Ni,联系方式在 personal website 上
如何开始使用该模型
该模型不适用于直接使用,请按照 Github Repo 中的说明进行操作。