

















模型:
ai-forever/mGPT



 英文
英文多语言GPT模型
我们介绍了一个基于GPT的自回归模型系列,它具有13亿个参数,使用维基百科和庞大的清洁爬行语料库在61种语言中进行训练,涵盖了25个语言家族。
我们使用GPT-2源代码和稀疏注意机制来复现GPT-3的架构, Deepspeed 和 Megatron 的框架使我们能够有效地并行化训练和推理步骤。由此产生的模型在性能上与最近发布的 XGLM 模型相当,同时覆盖了更多的语言,为资源有限的语言增强了自然语言处理的可能性。
代码
mGPT XL模型的源代码可在 Github 上获得。
论文
mGPT: Few-Shot Learners Go Multilingual
@misc{https://doi.org/10.48550/arxiv.2204.07580,
doi = {10.48550/ARXIV.2204.07580},
url = {https://arxiv.org/abs/2204.07580},
author = {Shliazhko, Oleh and Fenogenova, Alena and Tikhonova, Maria and Mikhailov, Vladislav and Kozlova, Anastasia and Shavrina, Tatiana},
keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences, I.2; I.2.7, 68-06, 68-04, 68T50, 68T01},
title = {mGPT: Few-Shot Learners Go Multilingual},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
语言
模型支持61种语言:
ISO代码:ar he vi id jv ms tl lv lt eu ml ta te hy bn mr hi ur af da en de sv fr it pt ro es el os tg fa ja ka ko th bxr xal mn sw yo be bg ru uk pl my uz ba kk ky tt az cv tr tk tyv sax et fi hu
语言:
阿拉伯语,希伯来语,越南语,印度尼西亚语,爪哇语,马来语,塔加拉语,拉脱维亚语,立陶宛语,巴斯克语,马拉雅拉姆语,泰米尔语,泰卢固语,亚美尼亚语,孟加拉语,马拉地语,印地语,乌尔都语,南非荷兰语,丹麦语,英语,德语,瑞典语,法语,意大利语,葡萄牙语,罗马尼亚语,西班牙语,希腊语,奥塞梯语,塔吉克语,波斯语,日语,格鲁吉亚语,韩语,泰语,布里亚特语,卡尔梅克语,蒙古语,斯瓦希里语,约鲁巴语,白俄罗斯语,保加利亚语,俄语,乌克兰语,波兰语,缅甸语,乌兹别克语,巴什基尔语,哈萨克语,吉尔吉斯语,塔塔尔语,阿塞拜疆语,楚瓦什语,土耳其语,土库曼语,图瓦语,雅库特语,爱沙尼亚语,芬兰语,匈牙利语
训练数据统计
- 大小:4880亿个UTF字符
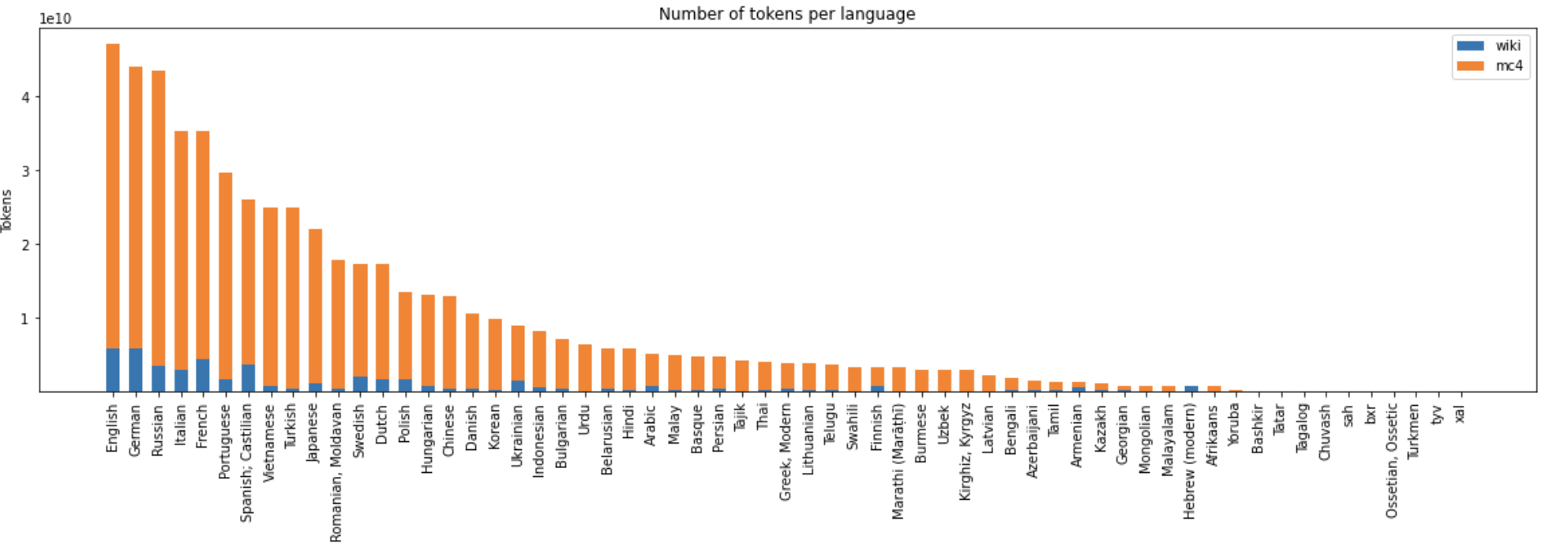 "通用训练语料库统计数据"
"通用训练语料库统计数据" 详情
该模型使用Megatron和Deepspeed库,由 SberDevices 团队在包含61种语言的600 GB文本数据集上,以序列长度512进行训练。模型总共进行了4400亿个BPE标记的训练。
总的训练时间约为14天,使用了256块Nvidia V100 GPU。