

















模型:
beomi/KcELECTRA-base-v2022


 英文
英文🚨 重要通知:此存储库已弃用,自KcELECTRA-base v2023发布以来🚨
使用 https://huggingface.co/beomi/KcELECTRA-base 和 v2022 版本(如果需要)。
KcELECTRA:韩国评论 ELECTRA
** 更新于 2022.10.08 **
- KcELECTRA-base-v2022(原名v2022-dev)模型名称已更改。
- 添加了该模型的详细分数。
- 相对于原始的KcELECTRA-base(v2021),大部分下游任务的性能提高了约1个百分点。
公开的韩语Transformer模型大多基于精心策划的数据集,如韩语维基百科、新闻文章、书籍等。然而,像NSMC这样的用户生成的噪声文本数据集没有经过精心筛选,其中包含了大量口语特点,如新创词语,以及正式写作中不会出现的错别字等表达形式经常出现。
KcELECTRA是为了适用于具有上述特征的数据集而开发的预训练ELECTRA模型,它通过从Naver新闻上收集评论和回复,从头开始对tokenizer和ELECTRA模型进行了训练。
通过增加数据集并扩展词汇表,相对于KcBERT,KcELECTRA的性能有了显著提升。
您可以通过Huggingface的Transformers库轻松地加载和使用KcELECTRA模型(无需下载单独的文件)。
💡 NOTE 💡 General Corpus로 학습한 KoELECTRA가 보편적인 task에서는 성능이 더 잘 나올 가능성이 높습니다. KcBERT/KcELECTRA는 User genrated, Noisy text에 대해서 보다 잘 동작하는 PLM입니다.
KcELECTRA性能
- Finetune代码可以在 https://github.com/Beomi/KcBERT-finetune 找到。
- 您可以在该存储库的每个Checkpoint文件夹中查看每个步骤的详细分数。
| Size (용량) | NSMC (acc) | Naver NER (F1) | PAWS (acc) | KorNLI (acc) | KorSTS (spearman) | Question Pair (acc) | KorQuaD (Dev) (EM/F1) | |
|---|---|---|---|---|---|---|---|---|
| KcELECTRA-base-v2022 | 475M | 91.97 | 87.35 | 76.50 | 82.12 | 83.67 | 95.12 | 69.00 / 90.40 |
| KcELECTRA-base | 475M | 91.71 | 86.90 | 74.80 | 81.65 | 82.65 | 95.78 | 70.60 / 90.11 |
| KcBERT-Base | 417M | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 |
| KcBERT-Large | 1.2G | 90.68 | 85.53 | 70.15 | 76.99 | 77.49 | 94.06 | 62.16 / 86.64 |
| KoBERT | 351M | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 |
| XLM-Roberta-Base | 1.03G | 89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 |
| HanBERT | 614M | 90.16 | 87.31 | 82.40 | 80.89 | 83.33 | 94.19 | 78.74 / 92.02 |
| KoELECTRA-Base | 423M | 90.21 | 86.87 | 81.90 | 80.85 | 83.21 | 94.20 | 61.10 / 89.59 |
| KoELECTRA-Base-v2 | 423M | 89.70 | 87.02 | 83.90 | 80.61 | 84.30 | 94.72 | 84.34 / 92.58 |
| KoELECTRA-Base-v3 | 423M | 90.63 | 88.11 | 84.45 | 82.24 | 85.53 | 95.25 | 84.83 / 93.45 |
| DistilKoBERT | 108M | 88.41 | 84.13 | 62.55 | 70.55 | 73.21 | 92.48 | 54.12 / 77.80 |
*HanBERT的大小是Bert模型和Tokenizer DB的总合。
* 运行了与config设置完全一样的结果,如果进一步进行超参数调优,可能会得到更好的性能。
如何使用
要求
- pytorch ~= 1.8.0
- transformers ~= 4.11.3
- emoji ~= 0.6.0
- soynlp ~= 0.0.493
默认使用方法
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("beomi/KcELECTRA-base")
model = AutoModel.from_pretrained("beomi/KcELECTRA-base")
💡 如果您之前使用的是与 AutoTokenizer 和 AutoModel 相关的代码,请仅将部分 .from_pretrained("beomi/kcbert-base") 更改为 .from_pretrained("beomi/KcELECTRA-base"),即可立即使用。
预训练和微调 Colab链接
预训练数据- 用于KcBERT训练的数据 + 之后直到 2021年3月初收集的评论
- 约17GB
- 基于评论-回复的文档构建
- https://github.com/Beomi/KcBERT-finetune 通过存储库进行微调和分数比较
- 使用PyTorch-Lightning 1.3.0,GPU,Colab的NSMC

训练数据和预处理
原始数据
训练数据是在2019年01月01日至2021年03月09日期间发表的新闻文章中收集的评论和回复数据。
数据大小为约17.3GB,包含超过1.8亿个句子。
KcBERT使用了2019年01月至2020年06月的文本数据进行训练,总共约有9000万个句子。
预处理
进行PLM训练的预处理过程如下:
韩语,英语,特殊字符甚至图标表情(例如🥳)!
通过正则表达式将韩语、英语、特殊字符以及图标表情都包含在内,作为学习的对象。
另外,我们将韩语范围设定为 ㄱ-ㅎ가-힣 ,以排除其中的汉字。
缩写评论中的重复字符串
我们将重复的字符(例如ㅋㅋㅋㅋㅋ)合并为一个字符(例如ㅋㅋ)。
区分大小写的模型
对于英文部分,KcBERT是一个区分大小写的模型,保持其原有的大小写。
删除少于10个字符的文本
少于10个字符的文本通常由单个单词组成,因此我们进行了排除。
删除重复项
为了删除重复的评论,我们将完全相同的重复评论合并为一个。
删除“OOO”
在Naver的评论中,当出现不当语言时,会使用“OOO”进行自我过滤。我们将该部分删除并替换为空格。
最好在文本数据中应用以下clean函数,以提高下游任务中的性能(减少[UNK])
pip install soynlp emoji
请使用以下clean函数对文本数据进行处理。
import re
import emoji
from soynlp.normalizer import repeat_normalize
emojis = ''.join(emoji.UNICODE_EMOJI.keys())
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣{emojis}]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
import re
import emoji
from soynlp.normalizer import repeat_normalize
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
def clean(x):
x = pattern.sub(' ', x)
x = emoji.replace_emoji(x, replace='') #emoji 삭제
x = url_pattern.sub('', x)
x = x.strip()
x = repeat_normalize(x, num_repeats=2)
return x
💡 在进行微调评分时,我们没有应用上述clean函数。
清理后的数据
- 有关KcBERT之外的其他数据的整理将在稍后发布。
Tokenizer,模型训练
我们使用了Huggingface的transformers库进行tokenizer的训练。
其中,我们使用BertWordPieceTokenizer进行训练,并将词汇表大小设置为30000。
tokenizer的训练是在整个数据集上进行的,并且为了让模型更好地适应常见的下游任务,我们还添加了KoELECTRA中使用但不重叠的词汇部分(实际上,两个模型之间的共同词汇约有5000个)。
我们使用TPU v3-8进行了约10天的训练,并且目前在Huggingface上公开的模型上传了训练了 848k 步的权重文件。
(我们做了每100k步的Checkpoint进行性能评估。有关详细信息,请参考KcBERT-finetune存储库。)
您可以观察到模型的训练损失,在最初的100-200k步骤中,损失显着减少,然后在训练结束时持续减少。
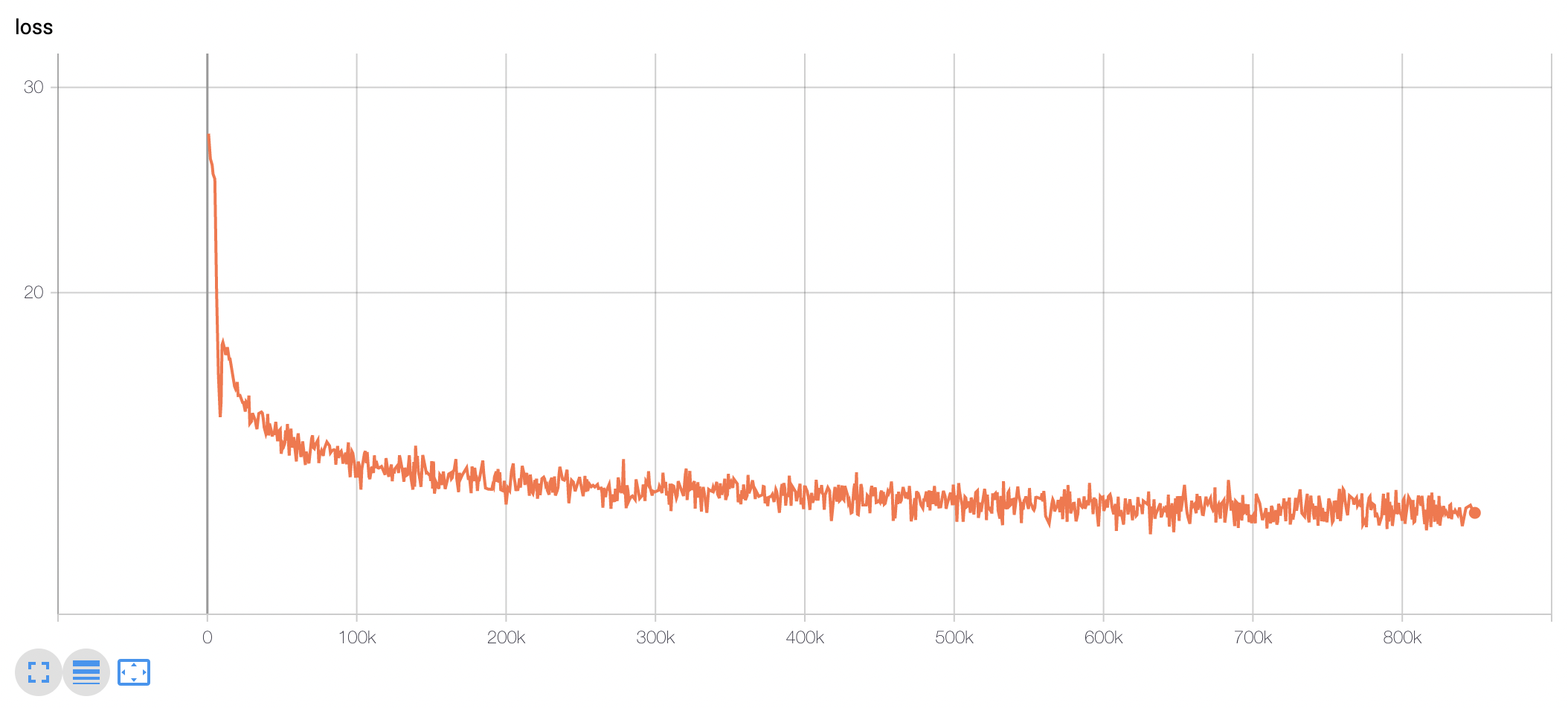
KcELECTRA预训练步骤下游任务性能比较
💡 以下表格仅针对部分Checkpoints进行了测试。
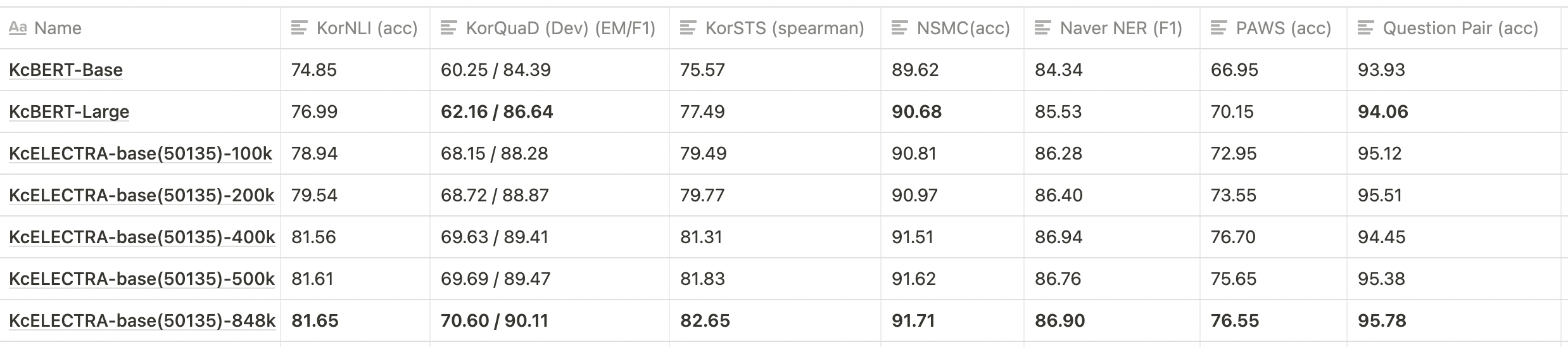
- 如上所示,KcELECTRA-base相对于KcBERT-base和KcBERT-large在所有数据集上都表现出更高的性能。
- 在预训练阶段,随着训练步骤的增加,KcELECTRA的性能逐渐提高。
引文/Citation
在引用KcELECTRA时,请使用以下格式进行引用。
@misc{lee2021kcelectra,
author = {Junbum Lee},
title = {KcELECTRA: Korean comments ELECTRA},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Beomi/KcELECTRA}}
}
除了引用论文之外,请注明MIT许可证。 ☺️
致谢
在KcELECTRA模型训练的GCP/TPU环境中,我们获得了编号为 TFRC 的项目的支持。
感谢 Monologg 先生在模型训练过程中给予的许多建议 :)
参考资料
Github存储库
- KcBERT by Beomi
- BERT by Google
- KoBERT by SKT
- KoELECTRA by Monologg
- Transformers by Huggingface
- Tokenizers by Hugginface
- ELECTRA train code by KLUE