










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
castorini/aggretriever-distilbert
 英文
英文Aggretriever是一个编码器,将词汇和语义文本信息聚合到一个单一向量中,用于密集检索,该向量是在使用BM25负采样对MS MARCO语料库进行微调的基础上得到的,并遵循 Aggretriever: A Simple Approach to Aggregate Textual Representation for Robust Dense Passage Retrieval 中所述的方法。
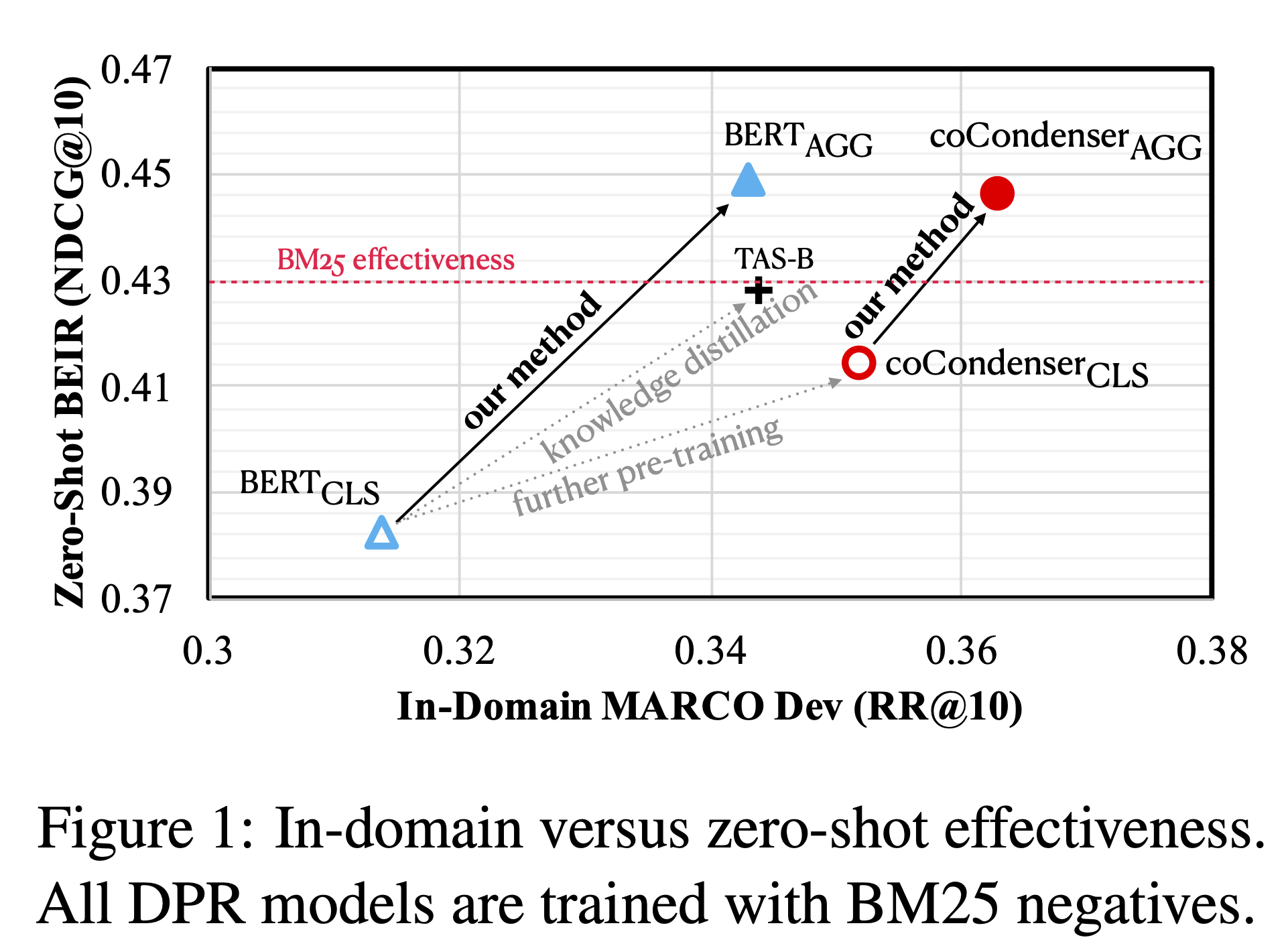
微调的相关GitHub存储库可在此处找到( here ),并且可以从pyserini中重现。还提供了以下变体:
| Model | Initialization | MARCO Dev | Encoder Path |
|---|---|---|---|
| aggretriever-distilbert | distilbert-base-uncased | 34.1 | 1233321 |
| aggretriever-cocondenser | Luyu/co-condenser-marco | 36.2 | 1234321 |
使用方法(HuggingFace Transformers)
直接在HuggingFace transformers中使用可用的模型。我们使用的是pyserini中实现的Aggretriever( here )。
from pyserini.encode._aggretriever import AggretrieverQueryEncoder
from pyserini.encode._aggretriever import AggretrieverDocumentEncoder
model_name = '/store/scratch/s269lin/experiments/aggretriever/hf_model/aggretriever-distilbert'
query_encoder = AggretrieverQueryEncoder(model_name, device='cpu')
context_encoder = AggretrieverDocumentEncoder(model_name, device='cpu')
query = "Where was Marie Curie born?"
contexts = [
"Maria Sklodowska, later known as Marie Curie, was born on November 7, 1867.",
"Born in Paris on 15 May 1859, Pierre Curie was the son of Eugène Curie, a doctor of French Catholic origin from Alsace."
]
# Compute embeddings
query_emb = query_encoder.encode(query)
ctx_emb = context_encoder.encode(contexts)
# Compute similarity scores using dot product
score1 = query_emb @ ctx_emb[0] # 47.667152
score2 = query_emb @ ctx_emb[1] # 39.054127