




















 英文
英文
概述
语言模型:gelectra-large-germanquad 语言:德语 训练数据:GermanQuAD训练集(约12MB) 评估数据:GermanQuAD测试集(约5MB) 基础设施:1x V100 GPU 发布时间:2021年4月21日
详情
- 我们以gelectra-large模型为基础训练了一个德语问答模型。
- 数据集为GermanQuAD,是一个全新的德语语言数据集,我们进行了手工注释和发布 online 。
- 训练数据集是单向注释的,包含11518个问题和11518个答案,而测试数据集是三向注释的,因此有2204个问题和2204·3-76=6536个答案,因为我们删除了76个错误答案。
有关更多详细信息和数据集下载,请参阅 https://deepset.ai/germanquad 中的SQuAD格式。
超参数
batch_size = 24 n_epochs = 2 max_seq_len = 384 learning_rate = 3e-5 lr_schedule = LinearWarmup embeds_dropout_prob = 0.1
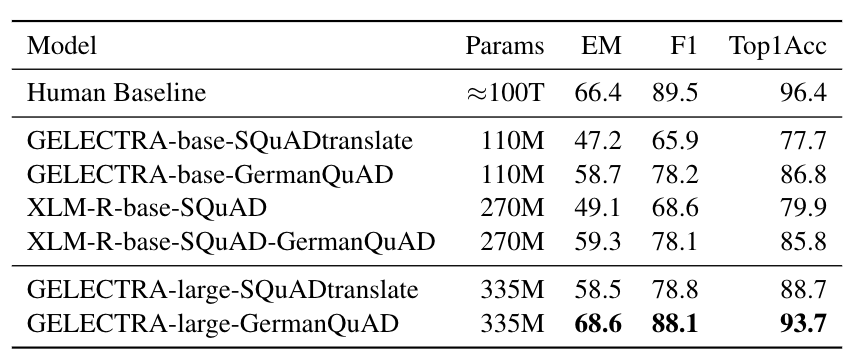
性能
我们在GermanQuAD测试集上评估了抽取式问答性能。模型类型和训练数据包含在模型名称中。对于XLM-Roberta的微调,我们使用英语SQuAD v2.0数据集。GELECTRA模型在SQuAD v1.1的德语翻译上进行了预热,然后在
GermanQuAD
上进行了微调。人工基线是通过将一个答案作为预测值,另外两个答案作为真实值来计算的。
作者
Timo Möller:timo.moeller@deepset.ai Julian Risch:julian.risch@deepset.ai Malte Pietsch:malte.pietsch@deepset.ai
关于我们
deepset 是开源NLP框架 Haystack 的公司,旨在帮助您构建可用于生产的NLP系统,可用于问答、摘要、排序等任务。
我们的其他作品:
- Distilled roberta-base-squad2 (aka "tinyroberta-squad2")
- German BERT (aka "bert-base-german-cased")
- GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")
联系我们并加入Haystack社区
要了解有关Haystack的更多信息,请访问我们的 GitHub 库和 Documentation 。
我们还有一个 Discord community open to everyone!
Twitter | LinkedIn | Discord | GitHub Discussions | Website
顺便说一句: we're hiring!