










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
dlicari/Italian-Legal-BERT-SC



 英文
英文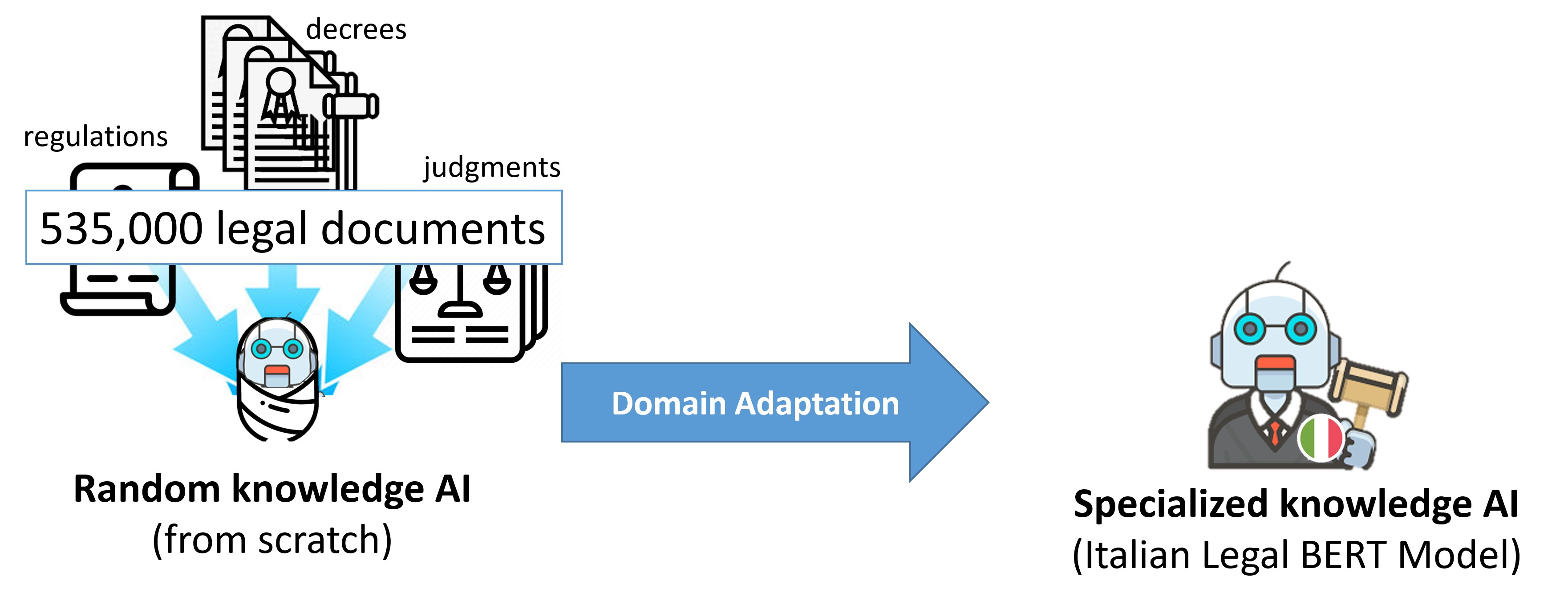
ITALIAN-LEGAL-BERT-SC
这是基于CamemBERT架构在意大利法律文件上从头开始预训练的变体(ITA-LEGAL-BERT-SC)
训练过程
它是使用更大的训练数据集进行从头训练的,包括6.6GB的民事和刑事案件。我们使用了 CamemBERT 架构,顶部使用了语言建模头部,AdamW Optimizer优化器,初始学习率为2e-5(线性学习率衰减),序列长度为512,批量大小为18,训练步骤为100万次,设备为8*NVIDIA A100 40GB,使用分布式数据并行(每个步骤执行8个批次)。它使用从头开始训练的SentencePiece分词,训练于训练集的一个子集(500万个句子),词汇大小为32000
使用方法
ITALIAN-LEGAL-BERT模型可以这样加载:
from transformers import AutoModel, AutoTokenizer model_name = "dlicari/Italian-Legal-BERT-SC" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModel.from_pretrained(model_name)
您可以使用Transformers库的fill-mask流程对ITALIAN-LEGAL-BERT进行推断。
# %pip install sentencepiece
# %pip install transformers
from transformers import pipeline
model_name = "dlicari/Italian-Legal-BERT-SC"
fill_mask = pipeline("fill-mask", model_name)
fill_mask("Il <mask> ha chiesto revocarsi l'obbligo di pagamento")
# [{'score': 0.6529251933097839,'token_str': 'ricorrente',
# {'score': 0.0380014143884182, 'token_str': 'convenuto',
# {'score': 0.0360226035118103, 'token_str': 'richiedente',
# {'score': 0.023908283561468124,'token_str': 'Condominio',
# {'score': 0.020863816142082214, 'token_str': 'lavoratore'}]