

















模型:
dreamlike-art/dreamlike-anime-1.0



 中文
中文Dreamlike Anime 1.0 is a high quality anime model, made by dreamlike.art .
If you want to use dreamlike models on your website/app/etc., check the license at the bottom first!
Add anime to your prompt to make your gens look more anime. Add photo to your prompt to make your gens look more photorealistic and have better anatomy. This model was trained on 768x768px images, so use 768x768px, 704x832px, 832x704px, etc. Higher resolution or non-square aspect ratios may produce artifacts.
Add this to the start of your prompts for best results:
photo anime, masterpiece, high quality, absurdres
Use negative prompts for best results, for example:
simple background, duplicate, retro style, low quality, lowest quality, 1980s, 1990s, 2000s, 2005 2006 2007 2008 2009 2010 2011 2012 2013, bad anatomy, bad proportions, extra digits, lowres, username, artist name, error, duplicate, watermark, signature, text, extra digit, fewer digits, worst quality, jpeg artifacts, blurry
1girl , girl , etc. give a bit different results, feel free to experiment and see which one you like more!
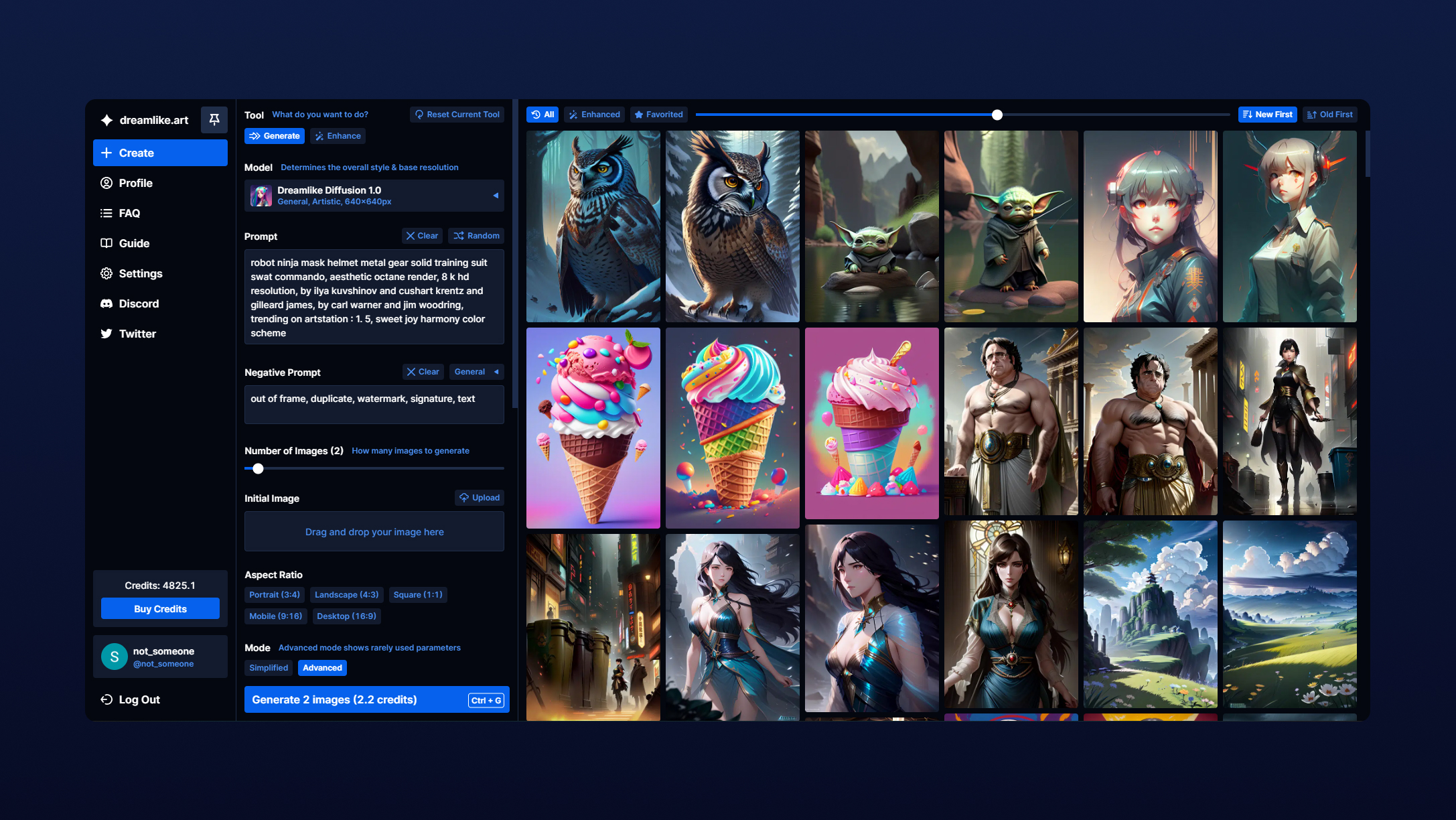
Examples



dreamlike.art
Use this model as well as Dreamlike Diffusion 1.0 and Dreamlike Photoreal 2.0 for free on dreamlike.art !
CKPT
Download dreamlike-anime-1.0.ckpt (2.13GB)
Safetensors
Download dreamlike-anime-1.0.safetensors (2.13GB)
? Diffusers
This model can be used just like any other Stable Diffusion model. For more information, please have a look at the Stable Diffusion Pipeline .
from diffusers import StableDiffusionPipeline
import torch
model_id = "dreamlike-art/dreamlike-anime-1.0"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "anime, masterpiece, high quality, 1girl, solo, long hair, looking at viewer, blush, smile, bangs, blue eyes, skirt, medium breasts, iridescent, gradient, colorful, besides a cottage, in the country"
negative_prompt = 'simple background, duplicate, retro style, low quality, lowest quality, 1980s, 1990s, 2000s, 2005 2006 2007 2008 2009 2010 2011 2012 2013, bad anatomy, bad proportions, extra digits, lowres, username, artist name, error, duplicate, watermark, signature, text, extra digit, fewer digits, worst quality, jpeg artifacts, blurry'
image = pipe(prompt, negative_prompt=negative_prompt).images[0]
image.save("./result.jpg")

License
This model is licesed under a modified CreativeML OpenRAIL-M license.
- You are not allowed to host, finetune, or do inference with the model or its derivatives on websites/apps/etc. If you want to, please email us at contact@dreamlike.art
- You are free to host the model card and files (Without any actual inference or finetuning) on both commercial and non-commercial websites/apps/etc. Please state the full model name (Dreamlike Anime 1.0) and include the license as well as a link to the model card ( https://huggingface.co/dreamlike-art/dreamlike-anime-1.0 )
- You are free to use the outputs (images) of the model for commercial purposes in teams of 10 or less
- You can't use the model to deliberately produce nor share illegal or harmful outputs or content
- The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
- You may re-distribute the weights. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the modified CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here: https://huggingface.co/dreamlike-art/dreamlike-anime-1.0/blob/main/LICENSE.md