










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
ehsanaghaei/SecureBERT
任务:
 填充掩码
填充掩码
数字对象标识符:
10.57967/hf/0042
 英文
英文SecureBERT: 一个针对网络安全的领域特定语言模型
SecureBERT是一个基于RoBERTa的领域特定语言模型,它使用大量的网络安全数据进行训练,并进行微调和调整以理解和表示网络安全的文本数据。
SecureBERT 是一个针对网络安全文本数据的领域特定语言模型,它在从在线资源中爬取的大量领域内文本上进行了训练。请查看 YouTube 的演示。
请在 GitHub Repo 查看详细信息。
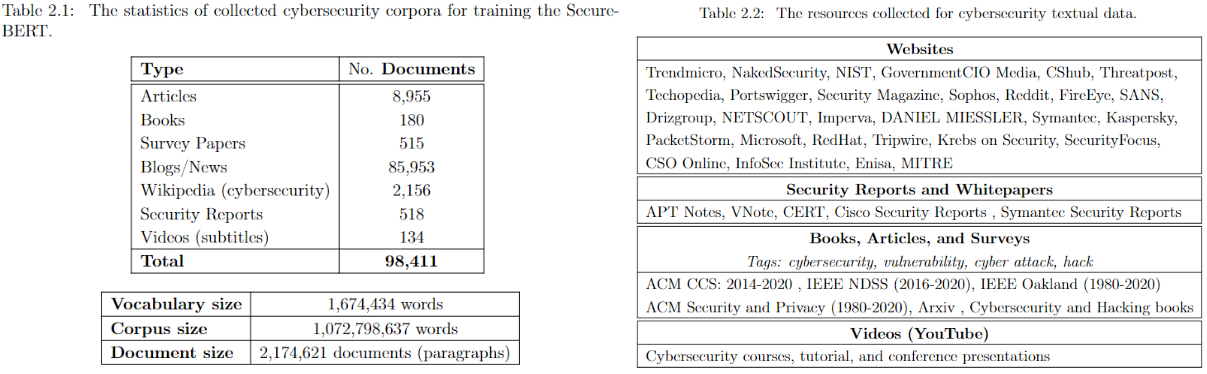
SecureBERT可以用作任何下游任务的基础模型,包括文本分类、命名实体识别、序列到序列、问答等。
- SecureBERT在预测文本中的掩码词时,表现出比现有模型如RoBERTa(基础和大型)、SciBERT和SecBERT更高的性能。
- SecureBERT在保持一般英语语言理解(表示)方面也表现出了良好的性能。
如何使用SecureBERT
SecureBERT已经上传到 Huggingface 框架。您可以使用下面的代码
from transformers import RobertaTokenizer, RobertaModel
import torch
tokenizer = RobertaTokenizer.from_pretrained("ehsanaghaei/SecureBERT")
model = RobertaModel.from_pretrained("ehsanaghaei/SecureBERT")
inputs = tokenizer("This is SecureBERT!", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
## Fill Mask
SecureBERT has been trained on MLM. Use the code below to predict the masked word within the given sentences:
```python
#!pip install transformers
#!pip install torch
#!pip install tokenizers
import torch
import transformers
from transformers import RobertaTokenizer, RobertaTokenizerFast
tokenizer = RobertaTokenizerFast.from_pretrained("ehsanaghaei/SecureBERT")
model = transformers.RobertaForMaskedLM.from_pretrained("ehsanaghaei/SecureBERT")
def predict_mask(sent, tokenizer, model, topk =10, print_results = True):
token_ids = tokenizer.encode(sent, return_tensors='pt')
masked_position = (token_ids.squeeze() == tokenizer.mask_token_id).nonzero()
masked_pos = [mask.item() for mask in masked_position]
words = []
with torch.no_grad():
output = model(token_ids)
last_hidden_state = output[0].squeeze()
list_of_list = []
for index, mask_index in enumerate(masked_pos):
mask_hidden_state = last_hidden_state[mask_index]
idx = torch.topk(mask_hidden_state, k=topk, dim=0)[1]
words = [tokenizer.decode(i.item()).strip() for i in idx]
words = [w.replace(' ','') for w in words]
list_of_list.append(words)
if print_results:
print("Mask ", "Predictions : ", words)
best_guess = ""
for j in list_of_list:
best_guess = best_guess + "," + j[0]
return words
while True:
sent = input("Text here: \t")
print("SecureBERT: ")
predict_mask(sent, tokenizer, model)
print("===========================\n")
参考文献
@inproceedings{aghaei2023securebert, title={SecureBERT: A Domain-Specific Language Model for Cybersecurity}, author={Aghaei, Ehsan and Niu, Xi and Shadid, Waseem and Al-Shaer, Ehab}, booktitle={Security and Privacy in Communication Networks: 18th EAI International Conference, SecureComm 2022, Virtual Event, October 2022, Proceedings}, pages={39--56}, year={2023}, organization={Springer} }