












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
facebook/dragon-roberta-query-encoder

 英文
英文DRAGON-RoBERTa是从 RoBERTa 初始化的BERT基础型密集检索器,并使用从MS MARCO语料库扩充的数据进行了进一步训练,遵循了 How to Train Your DRAGON: Diverse Augmentation Towards Generalizable Dense Retrieval 中描述的方法。
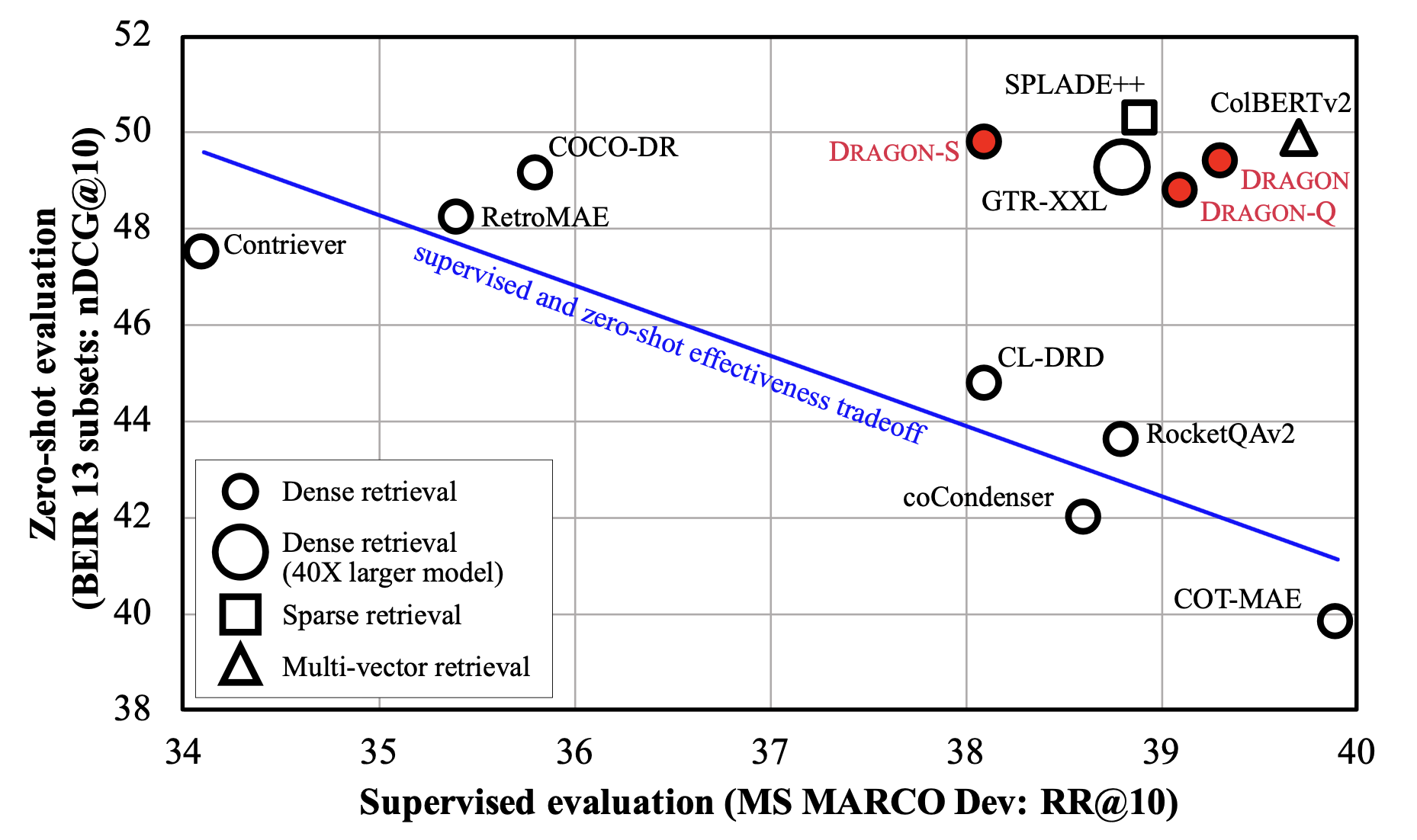
相关的GitHub存储库可以在这里找到 https://github.com/facebookresearch/dpr-scale/tree/main/dragon 。我们使用了非对称双编码器,其中有两个明确定义参数的编码器。还提供了以下模型:
| Model | Initialization | MARCO Dev | BEIR | Query Encoder Path | Context Encoder Path |
|---|---|---|---|---|---|
| DRAGON+ | Shitao/RetroMAE | 39.0 | 47.4 | 1234321 | 1235321 |
| DRAGON-RoBERTa | RoBERTa-base | 39.4 | 47.2 | 1236321 | 1237321 |
使用方法(HuggingFace Transformers)
直接在HuggingFace transformers中使用可用的模型。
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('facebook/dragon-roberta-query-encoder')
query_encoder = AutoModel.from_pretrained('facebook/dragon-roberta-query-encoder')
context_encoder = AutoModel.from_pretrained('facebook/dragon-roberta-context-encoder')
# We use msmarco query and passages as an example
query = "Where was Marie Curie born?"
contexts = [
"Maria Sklodowska, later known as Marie Curie, was born on November 7, 1867.",
"Born in Paris on 15 May 1859, Pierre Curie was the son of Eugène Curie, a doctor of French Catholic origin from Alsace."
]
# Apply tokenizer
query_input = tokenizer(query, return_tensors='pt')
ctx_input = tokenizer(contexts, padding=True, truncation=True, return_tensors='pt')
# Compute embeddings: take the last-layer hidden state of the [CLS] token
query_emb = query_encoder(**query_input).last_hidden_state[:, 0, :]
ctx_emb = context_encoder(**ctx_input).last_hidden_state[:, 0, :]
# Compute similarity scores using dot product
score1 = query_emb @ ctx_emb[0] # 385.1422
score2 = query_emb @ ctx_emb[1] # 383.6051