请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
facebook/wav2vec2-xls-r-1b-21-to-en



 英文
英文Wav2Vec2-XLS-R-2b-21-EN
Facebook的Wav2Vec2 XLS-R在语音翻译方面进行了微调。

这是一个 SpeechEncoderDecoderModel 模型。编码器是从 facebook/wav2vec2-xls-r-1b 的检查点进行热启动,解码器从 facebook/mbart-large-50 的检查点进行热启动。因此,编码器-解码器模型被针对21个 {lang} -> en 的翻译对进行微调。
该模型可以从以下口语语言翻译为英语(en):
{fr, de, es, ca, it, ru, zh-CN, pt, fa, et, mn, nl, tr, ar, sv-SE, lv, sl, ta, ja, id, cy} -> en
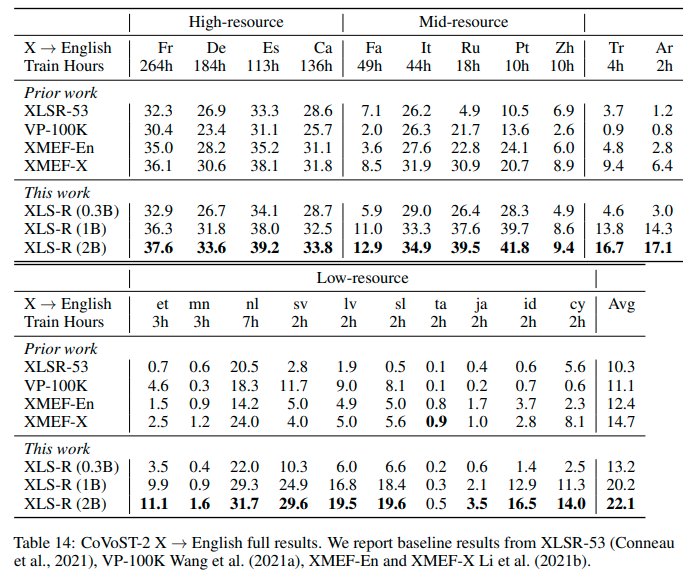
详细信息请参见 official XLS-R paper 的 5.1.2 节。
用法
演示
可以直接在此模型卡片上的语音识别小部件上测试该模型!只需录制一些可能的口语语言的音频或选择一个示例音频文件,查看检查点能够如何翻译输入。
示例
由于这是一个标准的序列到序列transformer模型,可以使用 generate 方法通过将语音特征传递给模型来生成转录。
您可以通过ASR流水线直接使用该模型。
from datasets import load_dataset
from transformers import pipeline
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-1b-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-1b-21-to-en")
translation = asr(audio_file)
或按以下步骤逐步使用:
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-1b-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-1b-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
结果 {lang} -> en
有关此模型在 Covost2 上的性能,请参见 XLS-R (1B) 的行。