

















模型:
kakaobrain/align-base


 英文
英文ALIGN(基础模型)
在《用嘈杂文本监督放大视觉和视觉语言表示学习》一文中,Chao Jia、Yinfei Yang、Ye Xia、Yi-Ting Chen、Zarana Parekh、Hieu Pham、Quoc V. Le、Yunhsuan Sung、Zhen Li、Tom Duerig提出了 ALIGN 模型。ALIGN采用双编码器架构,其视觉编码器为 EfficientNet ,文本编码器为 BERT ,并通过比对学习来对齐视觉和文本表示。与先前的工作不同,ALIGN利用了大规模嘈杂数据集,并展示了即使使用简单的方法,也可以利用语料库的规模来获得SOTA表示。
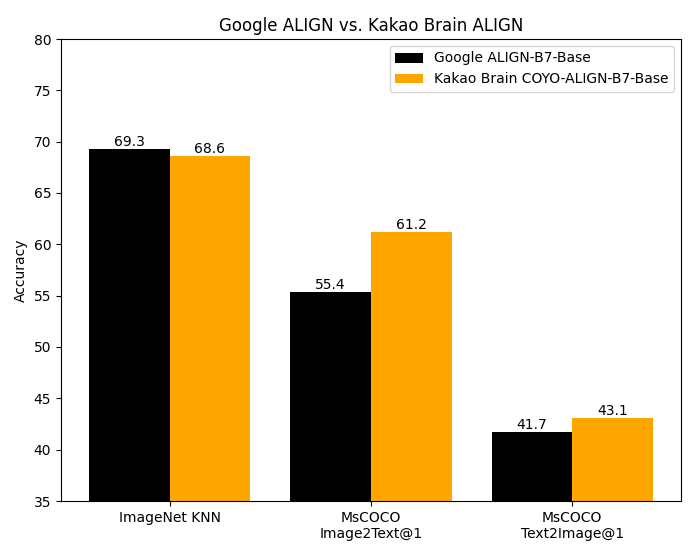
ALIGN代码没有公开发布,基础模型是从Kakao Brain团队的原始实现转换而来的。这个实现与原始的Google模型具有相同的架构和超参数,但是在开源的 COYO 数据集上进行了训练。Google的 ALIGN 模型是在18亿个图像-文本对的巨大数据集上训练的,无法复制,因为该数据集不是公开的。尽管Kakao Brain的ALIGN是在规模较小的COYO-700M数据集上训练的,但其性能与Google ALIGN的报告指标相当甚至超过了。
COYO-700M数据集
COYO 是一个包含7亿个图像-文本对的数据集,类似于Google的ALIGN 1.8B图像-文本数据集,后者是从网页中收集的“嘈杂”可替代文本和图像对,但是开源的。COYO-700M和ALIGN 1.8B都是“嘈杂”的,因为只应用了最小的过滤。COYO与其他开源图像-文本数据集LAION相似,但存在以下差异。虽然LAION 2B是一个包含20亿个英文对的更大数据集,而COYO只有7亿个对,但COYO的对配有更多的元数据,可以为用户提供更灵活、更细粒度的使用控制。下表显示了这些差异:COYO为所有对配备了审美评分、更稳健的水印评分和人脸计数数据。
| COYO | LAION 2B | ALIGN 1.8B |
|---|---|---|
| Image-text similarity score calculated with CLIP ViT-B/32 and ViT-L/14 models, they are provided as metadata but nothing is filtered out so as to avoid possible elimination bias | Image-text similarity score provided with CLIP (ViT-B/32) - only examples above threshold 0.28 | Minimal, Frequency based filtering |
| NSFW filtering on images and text | NSFW filtering on images | 1239321 |
| Face recognition (face count) data provided as meta-data | No face recognition data | NA |
| 700 million pairs all English | 2 billion English | 1.8 billion |
| From CC 2020 Oct - 2021 Aug | From CC 2014-2020 | NA |
| Aesthetic Score | Aesthetic Score Partial | NA |
| More robust Watermark score | Watermark Score | NA |
| Hugging Face Hub | Hugging Face Hub | Not made public |
| English | English | English? |
COYO作为数据集发布在hub上。
与Transformers一起使用
零样本图像分类
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
candidate_labels = ["an image of a cat", "an image of a dog"]
inputs = processor(text=candidate_labels, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
多模态嵌入检索
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "an image of a cat"
inputs = processor(text=text, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# multi-modal text embedding
text_embeds = outputs.text_embeds
# multi-modal image embedding
image_embeds = outputs.image_embeds
或者,分别检索图像或文本嵌入。
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
# image embeddings
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
image_embeds = model.get_image_features(
pixel_values=inputs['pixel_values'],
)
# text embeddings
text = "an image of a cat"
inputs = processor(text=text, return_tensors="pt")
text_embeds = model.get_text_features(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
token_type_ids=inputs['token_type_ids'],
)
模型使用
预期使用
该模型是研究社区的研究成果。我们希望该模型能使研究人员更好地理解和探索零样本、任意图像分类。我们还希望它能用于跨学科研究,以评估这种模型可能带来的潜在影响——ALIGN论文中对可能的下游影响进行了讨论以提供此类分析的示例。
主要预期用途这些模型的主要使用者是AI研究人员。
我们主要设想这个模型将被研究人员用于更好地理解计算机视觉模型的鲁棒性、泛化能力和其他能力、偏见和约束。