










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
mrm8488/bert-multi-uncased-finetuned-xquadv1


 英文
英文BERT(base-multilingual-uncased)用于多语言问答的精调模型
该模型由 Google 创建,并在 XQuAD 上使用多语言(11种不同语言)问答下游任务的数据进行了精调。
语言模型('bert-base-multilingual-uncased')的详细信息
| Languages | Heads | Layers | Hidden | Params |
|---|---|---|---|---|
| 102 | 12 | 12 | 768 | 100 M |
下游任务的详细信息(多语言问答)- 数据集
Deepmind XQuAD
语言覆盖范围:
- 阿拉伯语:ar
- 德语:de
- 希腊语:el
- 英语:en
- 西班牙语:es
- 印地语:hi
- 俄语:ru
- 泰语:th
- 土耳其语:tr
- 越南语:vi
- 中文:zh
由于数据集基于SQuAD v1.1,因此数据中没有无法回答的问题。我们选择了这个设置,以便模型可以专注于跨语言转移。
我们在下表中展示了每种语言的段落、问题和答案的平均标记数。统计数据是使用 Jieba (对于中文)和 Moses tokenizer (对于其他语言)获得的。
| en | es | de | el | ru | tr | ar | vi | th | zh | hi | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Paragraph | 142.4 | 160.7 | 139.5 | 149.6 | 133.9 | 126.5 | 128.2 | 191.2 | 158.7 | 147.6 | 232.4 |
| Question | 11.5 | 13.4 | 11.0 | 11.7 | 10.0 | 9.8 | 10.7 | 14.8 | 11.5 | 10.5 | 18.7 |
| Answer | 3.1 | 3.6 | 3.0 | 3.3 | 3.1 | 3.1 | 3.1 | 4.5 | 4.1 | 3.5 | 5.6 |
引用:
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
由于XQuAD只是一个评估数据集,我使用了数据增强技术(抓取、神经机器翻译等)来获得更多样本,并分割数据集以得到训练集和测试集。测试集是以每种语言相同数量的样本创建的。最后,我获得了:
| Dataset | # samples |
|---|---|
| XQUAD train | 50 K |
| XQUAD test | 8 K |
模型训练
模型是在Tesla P100 GPU和25GB的RAM上进行训练的。精调脚本可以在 here 找到。
模型的工作方式
使用pipelines可以快速使用:
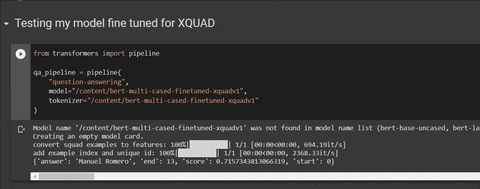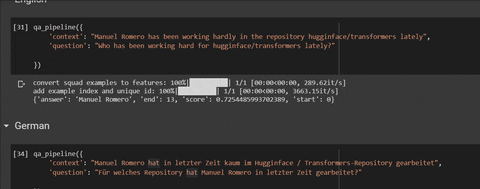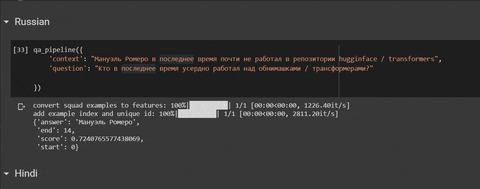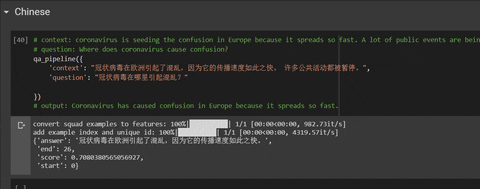
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-multi-uncased-finetuned-xquadv1",
tokenizer="mrm8488/bert-multi-uncased-finetuned-xquadv1"
)
# context: Coronavirus is seeding panic in the West because it expands so fast.
# question: Where is seeding panic Coronavirus?
qa_pipeline({
'context': "कोरोनावायरस पश्चिम में आतंक बो रहा है क्योंकि यह इतनी तेजी से फैलता है।",
'question': "कोरोनावायरस घबराहट कहां है?"
})
# output: {'answer': 'पश्चिम', 'end': 18, 'score': 0.7037217439689059, 'start': 12}
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# output: {'answer': 'Manuel Romero', 'end': 13, 'score': 0.7254485993702389, 'start': 0}
qa_pipeline({
'context': "Manuel Romero a travaillé à peine dans le référentiel hugginface / transformers ces derniers temps",
'question': "Pour quel référentiel a travaillé Manuel Romero récemment?"
})
#output: {'answer': 'hugginface / transformers', 'end': 79, 'score': 0.6482061613915384, 'start': 54}
在Colab上尝试一下:
在西班牙用 ♥ 制作