










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
mrm8488/bert-spanish-cased-finetuned-pos


 英文
英文西班牙语BERT(BETO)+ POS
该模型是在西班牙语BERT的标准版本上进行微调的,用于POS(词性标注)下游任务。
下游任务(POS)的详细信息 - 数据集
- 使用数据增强技术的 Dataset: CONLL Corpora ES
对数据集进行预处理,并将其分为训练集和开发集(80/20)
| Dataset | # Examples |
|---|---|
| Train | 340 K |
| Dev | 50 K |
AO, AQ, CC, CS, DA, DD, DE, DI, DN, DP, DT, Faa, Fat, Fc, Fd, Fe, Fg, Fh, Fia, Fit, Fp, Fpa, Fpt, Fs, Ft, Fx, Fz, I, NC, NP, P0, PD, PI, PN, PP, PR, PT, PX, RG, RN, SP, VAI, VAM, VAN, VAP, VAS, VMG, VMI, VMM, VMN, VMP, VMS, VSG, VSI, VSM, VSN, VSP, VSS, Y and Z
评估集上的指标:
| Metric | # score |
|---|---|
| F1 | 90.06 |
| Precision | 89.46 |
| Recall | 90.67 |
模型的应用
使用pipelines快速使用:
from transformers import pipeline
nlp_pos = pipeline(
"ner",
model="mrm8488/bert-spanish-cased-finetuned-pos",
tokenizer=(
'mrm8488/bert-spanish-cased-finetuned-pos',
{"use_fast": False}
))
text = 'Mis amigos están pensando en viajar a Londres este verano'
nlp_pos(text)
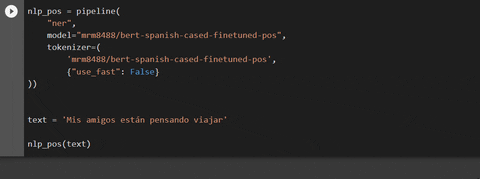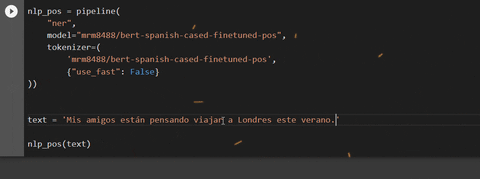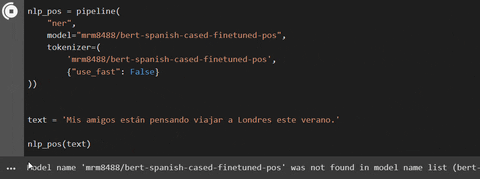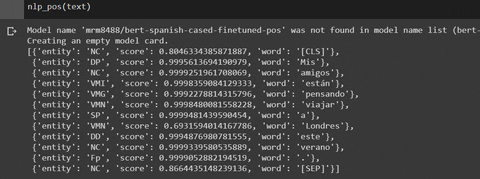
#Output:
'''
[{'entity': 'NC', 'score': 0.7792173624038696, 'word': '[CLS]'},
{'entity': 'DP', 'score': 0.9996283650398254, 'word': 'Mis'},
{'entity': 'NC', 'score': 0.9999253749847412, 'word': 'amigos'},
{'entity': 'VMI', 'score': 0.9998560547828674, 'word': 'están'},
{'entity': 'VMG', 'score': 0.9992249011993408, 'word': 'pensando'},
{'entity': 'SP', 'score': 0.9999602437019348, 'word': 'en'},
{'entity': 'VMN', 'score': 0.9998666048049927, 'word': 'viajar'},
{'entity': 'SP', 'score': 0.9999545216560364, 'word': 'a'},
{'entity': 'VMN', 'score': 0.8722310662269592, 'word': 'Londres'},
{'entity': 'DD', 'score': 0.9995203614234924, 'word': 'este'},
{'entity': 'NC', 'score': 0.9999248385429382, 'word': 'verano'},
{'entity': 'NC', 'score': 0.8802427649497986, 'word': '[SEP]'}]
'''
还提供16个POS标签的版本 here
西班牙制造,用♥制作