

















模型:
mrm8488/t5-base-finetuned-wikiSQL



 英文
英文T5-base在WikiSQL上的微调
Google's T5 在 WikiSQL 上为英语到SQL的翻译进行微调。
T5的详细信息
T5模型是由Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li和Peter J. Liu在 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 中提出的。以下是摘要:
迁移学习是一种先在数据丰富的任务上进行预训练,然后在下游任务上进行微调的模型技术,在自然语言处理(NLP)中被证明是一种强大的技术。迁移学习的有效性催生了各种方法、方法论和实践。在本文中,我们通过引入一个统一的框架,将每个语言问题转化为文本到文本的格式,来探索NLP的迁移学习技术领域。我们的系统研究比较了预训练目标、架构、无标记数据集、迁移方法和其他因素在数十个语言理解任务上的表现。通过将我们的探索洞察与规模和我们的新的“巨大干净爬取语料库”相结合,我们在涵盖摘要、问答、文本分类等多个基准测试中取得了最先进的结果。为了促进未来对NLP的迁移学习的研究,我们发布了我们的数据集、预训练模型和代码。

数据集的详细信息📚
数据集ID:wikisql,来源于 Huggingface/NLP
| Dataset | Split | # samples |
|---|---|---|
| wikisql | train | 56355 |
| wikisql | valid | 14436 |
如何从 nlp 加载它
train_dataset = nlp.load_dataset('wikisql', split=nlp.Split.TRAIN)
valid_dataset = nlp.load_dataset('wikisql', split=nlp.Split.VALIDATION)
在 NLP Viewer 中了解更多关于该数据集和其他数据集的信息
模型微调🏋️
训练脚本是 this Colab Notebook 的稍微修改版本,由 Suraj Patil 创建,因此所有信用归于他!
模型实例 🚀
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL")
def get_sql(query):
input_text = "translate English to SQL: %s </s>" % query
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'])
return tokenizer.decode(output[0])
query = "How many models were finetuned using BERT as base model?"
get_sql(query)
# output: 'SELECT COUNT Model fine tuned FROM table WHERE Base model = BERT'
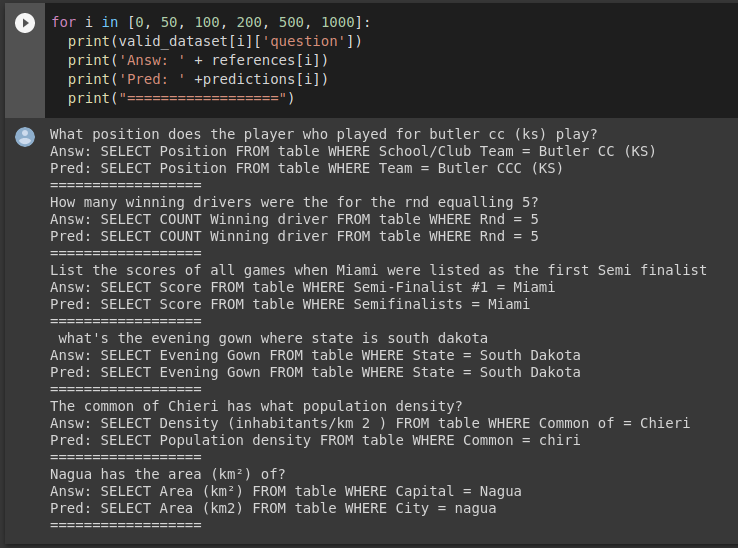
验证数据集中的其他示例:
创建者: Manuel Romero/@mrm8488 | LinkedIn
在西班牙用 ♥ 制作