










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
nguyenvulebinh/wav2vec2-large-vi
许可:
 cc-by-nc-4.0
cc-by-nc-4.0
语言:
 vi
vi
 英文
英文Vietnamese Self-Supervised Learning Wav2Vec2模型
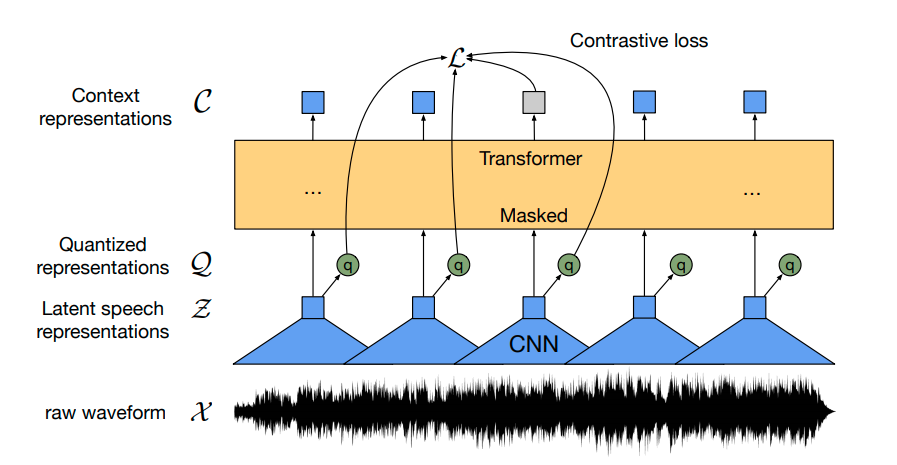
模型
我们使用wav2vec2架构进行自我监督学习
数据
我们的自我监督模型预训练于一个包含13,000小时越南YouTube音频的庞大音频数据集,其中包括:
- 清晰音频
- 噪音音频
- 对话
- 多种性别和方言
下载
我们已经将预训练模型上传至Huggingface。基础模型进行了35个epochs的训练,大型模型在TPU V3-8上进行了大约30天的20个epochs的训练。
- Based version ~ 95M参数
- Large version ~ 317M参数
使用
from transformers import Wav2Vec2ForPreTraining, Wav2Vec2Processor model_name = 'nguyenvulebinh/wav2vec2-base-vi' # model_name = 'nguyenvulebinh/wav2vec2-large-vi' model = Wav2Vec2ForPreTraining.from_pretrained(model_name) processor = Wav2Vec2Processor.from_pretrained(model_name)
由于我们的模型与英文wav2vec2版本具有相同的架构,您可以使用 this notebook 获取更多关于如何微调模型的信息。
微调版本
VLSP 2020 ASR数据集
在VLSP T1测试集上的基准WER结果:
| 1235321 | 1236321 | |
|---|---|---|
| without LM | 8.66 | 6.90 |
| with 5-grams LM | 6.53 | 5.32 |
使用方法:
#pytorch
#!pip install transformers==4.20.0
#!pip install https://github.com/kpu/kenlm/archive/master.zip
#!pip install pyctcdecode==0.4.0
from transformers.file_utils import cached_path, hf_bucket_url
from importlib.machinery import SourceFileLoader
from transformers import Wav2Vec2ProcessorWithLM
from IPython.lib.display import Audio
import torchaudio
import torch
# Load model & processor
model_name = "nguyenvulebinh/wav2vec2-base-vi-vlsp2020"
# model_name = "nguyenvulebinh/wav2vec2-large-vi-vlsp2020"
model = SourceFileLoader("model", cached_path(hf_bucket_url(model_name,filename="model_handling.py"))).load_module().Wav2Vec2ForCTC.from_pretrained(model_name)
processor = Wav2Vec2ProcessorWithLM.from_pretrained(model_name)
# Load an example audio (16k)
audio, sample_rate = torchaudio.load(cached_path(hf_bucket_url(model_name, filename="t2_0000006682.wav")))
input_data = processor.feature_extractor(audio[0], sampling_rate=16000, return_tensors='pt')
# Infer
output = model(**input_data)
# Output transcript without LM
print(processor.tokenizer.decode(output.logits.argmax(dim=-1)[0].detach().cpu().numpy()))
# Output transcript with LM
print(processor.decode(output.logits.cpu().detach().numpy()[0], beam_width=100).text)
致谢
- 我们想要感谢Google TPU Research Cloud(TRC)计划以及Soonson Kwon(Google ML生态系统计划主管)的支持。
- 特别感谢我的同事们在 VietAI 和 VAIS 给予的建议。
联系方式
nguyenvulebinh@gmail.com / binh@vietai.org
