










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
optimum/distilbert-base-uncased-finetuned-sst-2-english



 英文
英文ONNX 转换 DistilBERT 基本未大写定型 SST-2
转换 distilbert-base-uncased-finetuned-sst-2-english
这个模型是基于 SST-2 进行微调的 DistilBERT-base-uncased 微调检查点。该模型在开发集上达到了 91.3% 的准确率(与 Bert bert-base-uncased 版本相比,准确率为 92.7%)。
有关 DistilBERT 的更多细节,我们鼓励用户查看 this model card 。
微调超参数
- 学习率 = 1e-5
- 批量大小 = 32
- 预热 = 600
- 最大序列长度 = 128
- 训练轮次 = 3.0
偏见
根据一些实验,我们观察到这个模型可能产生有针对性的预测,针对的是少数群体。
例如,对于像 "这部电影是在国家拍摄的" 这样的句子,当输入中没有任何内容表明存在如此强烈的语义转变时,这个二元分类模型会为正类别给出截然不同的概率,具体取决于国家(如果是法国,则为 0.89,但如果是阿富汗,则为 0.08)。在这个 colab 中, Aurélien Géron 制作了一个有趣的地图,显示了每个国家的这些概率。
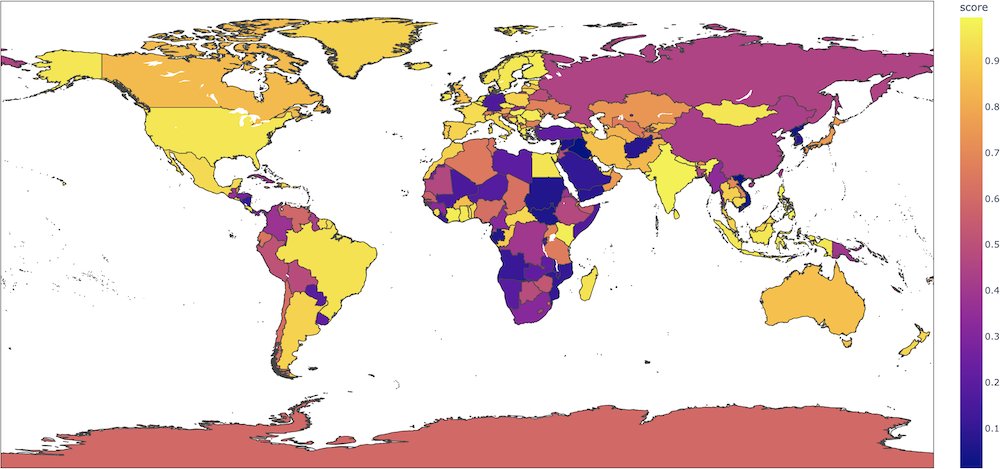
我们强烈建议用户在其用例中深入研究这些方面,以评估此模型的风险。我们建议查看以下偏见评估数据集作为起点: WinoBias , WinoGender , Stereoset 。