










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512



 英文
英文文档理解模型(在段落级别上对DocLayNet基础上的LayoutXLM进行微调)
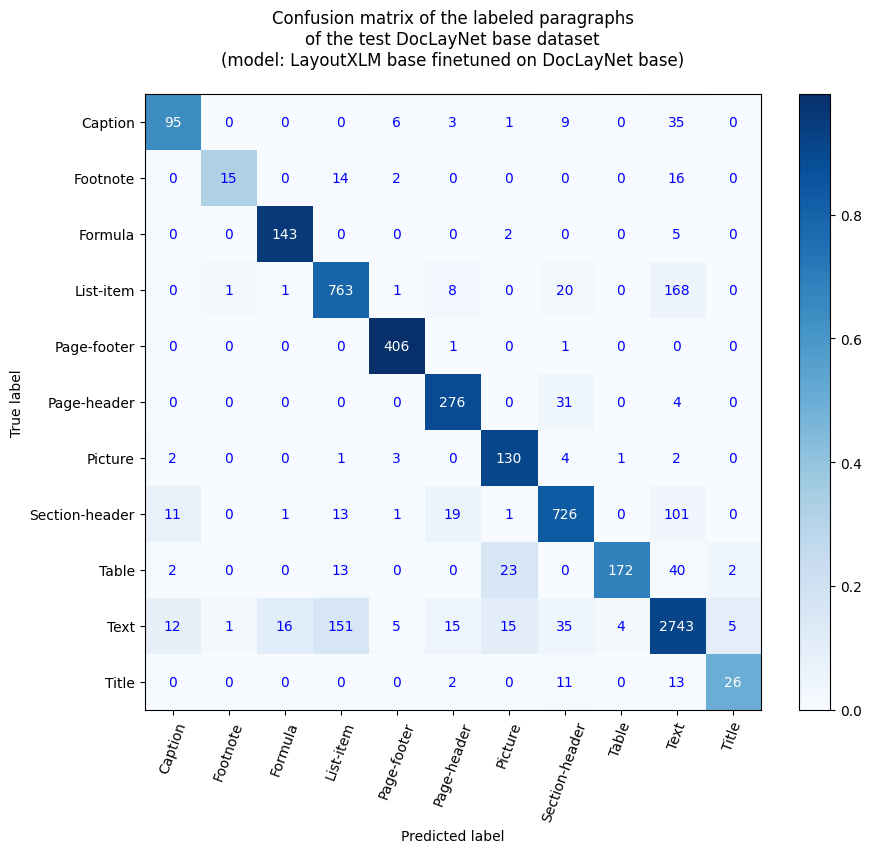
此模型是根据数据集 DocLayNet base 对 microsoft/layoutxlm-base 进行微调的版本。它在评估集上达到以下结果:
- 损失:0.1796
- 精确度:0.8062
- 召回率:0.7441
- F1 值:0.7739
- Token 准确度:0.9693
- 段落准确度:0.8655
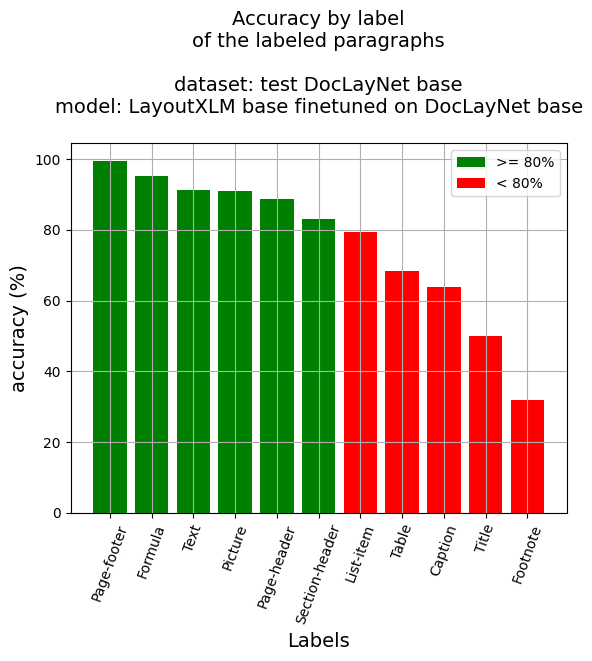
段落级别的准确度
- 段落准确度:86.55%
- 按标签的准确度
- 标题:63.76%
- 脚注:31.91%
- 公式:95.33%
- 列表项:79.31%
- 页脚:99.51%
- 页眉:88.75%
- 图片:90.91%
- 章节标题:83.16%
- 表格:68.25%
- 文本:91.37%
- 标题:50.0%
参考文献
博客文章
- Layout XLM base
- (03/31/2023) Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level with LayoutXLM base
- (03/25/2023) Document AI | APP to compare the Document Understanding LiLT and LayoutXLM (base) models at line level
- (03/05/2023) Document AI | Inference APP and fine-tuning notebook for Document Understanding at line level with LayoutXLM base
- LiLT base- (02/16/2023) Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level - (02/14/2023) Document AI | Inference APP for Document Understanding at line level - (02/10/2023) Document AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet dataset - (01/31/2023) Document AI | DocLayNet image viewer APP - (01/27/2023) Document AI | Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)
笔记本(段落级别)
- Layout XLM base
- Document AI | Inference at paragraph level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at paragraph level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)
- Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)
- LiLT base
- Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)
笔记本(行级别)
- Layout XLM base
- Document AI | Inference APP at line level with 2 Document Understanding models (LiLT and LayoutXLM base fine-tuned on DocLayNet base dataset)
- Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)
- Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- LiLT base
- Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- DocLayNet image viewer APP
- 处理 DocLayNet 数据集以供 Hugging Face hub 的布局模型使用(微调、推理)
APP
您可以在 Hugging Face Spaces 中使用此 APP 测试此模型: Inference APP for Document Understanding at paragraph level (v2) 。
DocLayNet 数据集
IBM 提供了使用边界框对 6 个不同文档类别的 80863 个唯一页面进行页面级布局分割的基本事实数据,提供了 11 个不同类别的基本事实标签。
迄今为止,该数据集可以通过直接链接或从 Hugging Face 数据集下载:
- 直接链接: doclaynet_core.zip (28 GiB), doclaynet_extra.zip (7.5 GiB)
- Hugging Face 数据集库: dataset DocLayNet
论文: DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis (06/02/2022)
模型描述
该模型在 512 个标记的重叠的段落块上进行了段落级别的微调。因此,模型使用了数据集的所有布局和文本数据进行了训练。
在推理时,通过计算最佳概率为每个段落边界框分配标签。
推理
训练和评估数据
训练过程
训练超参数
训练期间使用了以下超参数:
- 学习率:2e-05
- 训练批量大小:8
- 评估批量大小:16
- 种子:42
- 优化器:Adam,β=(0.9,0.999), ε=1e-08
- lr_scheduler_type:linear
- lr_scheduler_warmup_ratio:0.1
- num_epochs:4
- 混合精度训练:本机 AMP
训练结果
| Training Loss | Epoch | Step | Accuracy | F1 | Validation Loss | Precision | Recall |
|---|---|---|---|---|---|---|---|
| No log | 0.11 | 200 | 0.8842 | 0.1066 | 0.4428 | 0.1154 | 0.0991 |
| No log | 0.21 | 400 | 0.9243 | 0.4440 | 0.3040 | 0.4548 | 0.4336 |
| 0.7241 | 0.32 | 600 | 0.9359 | 0.5544 | 0.2265 | 0.5330 | 0.5775 |
| 0.7241 | 0.43 | 800 | 0.9479 | 0.6015 | 0.2140 | 0.6013 | 0.6017 |
| 0.2343 | 0.53 | 1000 | 0.9402 | 0.6132 | 0.2852 | 0.6642 | 0.5695 |
| 0.2343 | 0.64 | 1200 | 0.9540 | 0.6604 | 0.1694 | 0.6565 | 0.6644 |
| 0.2343 | 0.75 | 1400 | 0.9354 | 0.6198 | 0.2308 | 0.5119 | 0.7854 |
| 0.1913 | 0.85 | 1600 | 0.9594 | 0.6590 | 0.1601 | 0.7190 | 0.6082 |
| 0.1913 | 0.96 | 1800 | 0.9541 | 0.6597 | 0.1671 | 0.5790 | 0.7664 |
| 0.1346 | 1.07 | 2000 | 0.9612 | 0.6986 | 0.1580 | 0.6838 | 0.7140 |
| 0.1346 | 1.17 | 2200 | 0.9597 | 0.6897 | 0.1423 | 0.6618 | 0.7200 |
| 0.1346 | 1.28 | 2400 | 0.9663 | 0.6980 | 0.1580 | 0.7490 | 0.6535 |
| 0.098 | 1.39 | 2600 | 0.9616 | 0.6800 | 0.1394 | 0.7044 | 0.6573 |
| 0.098 | 1.49 | 2800 | 0.9686 | 0.7251 | 0.1756 | 0.6893 | 0.7649 |
| 0.0999 | 1.6 | 3000 | 0.9636 | 0.6985 | 0.1542 | 0.7127 | 0.6848 |
| 0.0999 | 1.71 | 3200 | 0.9670 | 0.7097 | 0.1187 | 0.7538 | 0.6705 |
| 0.0999 | 1.81 | 3400 | 0.9585 | 0.7427 | 0.1793 | 0.7602 | 0.7260 |
| 0.0972 | 1.92 | 3600 | 0.9621 | 0.7189 | 0.1836 | 0.7576 | 0.6839 |
| 0.0972 | 2.03 | 3800 | 0.9642 | 0.7189 | 0.1465 | 0.7388 | 0.6999 |
| 0.0662 | 2.13 | 4000 | 0.9691 | 0.7450 | 0.1409 | 0.7615 | 0.7292 |
| 0.0662 | 2.24 | 4200 | 0.9615 | 0.7432 | 0.1720 | 0.7435 | 0.7429 |
| 0.0662 | 2.35 | 4400 | 0.9667 | 0.7338 | 0.1440 | 0.7469 | 0.7212 |
| 0.0581 | 2.45 | 4600 | 0.9657 | 0.7135 | 0.1928 | 0.7458 | 0.6839 |
| 0.0581 | 2.56 | 4800 | 0.9692 | 0.7378 | 0.1645 | 0.7467 | 0.7292 |
| 0.0538 | 2.67 | 5000 | 0.9656 | 0.7619 | 0.1517 | 0.7700 | 0.7541 |
| 0.0538 | 2.77 | 5200 | 0.9684 | 0.7728 | 0.1676 | 0.8227 | 0.7286 |
| 0.0538 | 2.88 | 5400 | 0.9725 | 0.7608 | 0.1277 | 0.7865 | 0.7367 |
| 0.0432 | 2.99 | 5600 | 0.9693 | 0.7784 | 0.1532 | 0.7891 | 0.7681 |
| 0.0432 | 3.09 | 5800 | 0.9692 | 0.7783 | 0.1701 | 0.8067 | 0.7519 |
| 0.0272 | 3.2 | 6000 | 0.9732 | 0.7798 | 0.1159 | 0.8072 | 0.7542 |
| 0.0272 | 3.3 | 6200 | 0.9720 | 0.7797 | 0.1835 | 0.7926 | 0.7672 |
| 0.0272 | 3.41 | 6400 | 0.9730 | 0.7894 | 0.1481 | 0.8183 | 0.7624 |
| 0.0274 | 3.52 | 6600 | 0.9686 | 0.7655 | 0.1552 | 0.7958 | 0.7373 |
| 0.0274 | 3.62 | 6800 | 0.9698 | 0.7724 | 0.1523 | 0.8068 | 0.7407 |
| 0.0246 | 3.73 | 7000 | 0.9691 | 0.7720 | 0.1673 | 0.7960 | 0.7493 |
| 0.0246 | 3.84 | 7200 | 0.9688 | 0.7695 | 0.1333 | 0.7986 | 0.7424 |
| 0.0246 | 3.94 | 7400 | 0.1796 | 0.8062 | 0.7441 | 0.7739 | 0.9693 |
框架版本
- Transformers 4.27.3
- Pytorch 1.10.0+cu111
- Datasets 2.10.1
- Tokenizers 0.13.2
其他模型
- 行级别
- Document Understanding model (finetuned LiLT base at line level on DocLayNet base) (准确度 | 标记:85.84% - 行:91.97%)
- Document Understanding model (finetuned LayoutXLM base at line level on DocLayNet base) (准确度 | 标记:93.73% - 行:...)
- 段落级别
- Document Understanding model (finetuned LiLT base at paragraph level on DocLayNet base) (准确度 | 标记:86.34% - 段落:68.15%)
- Document Understanding model (finetuned LayoutXLM base at paragraph level on DocLayNet base) (准确度 | 标记:96.93% - 段落:86.55%)