

















模型:
pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512



 英文
英文文档理解模型(在DocLayNet基础上对LiLT基础模型进行段落级微调)
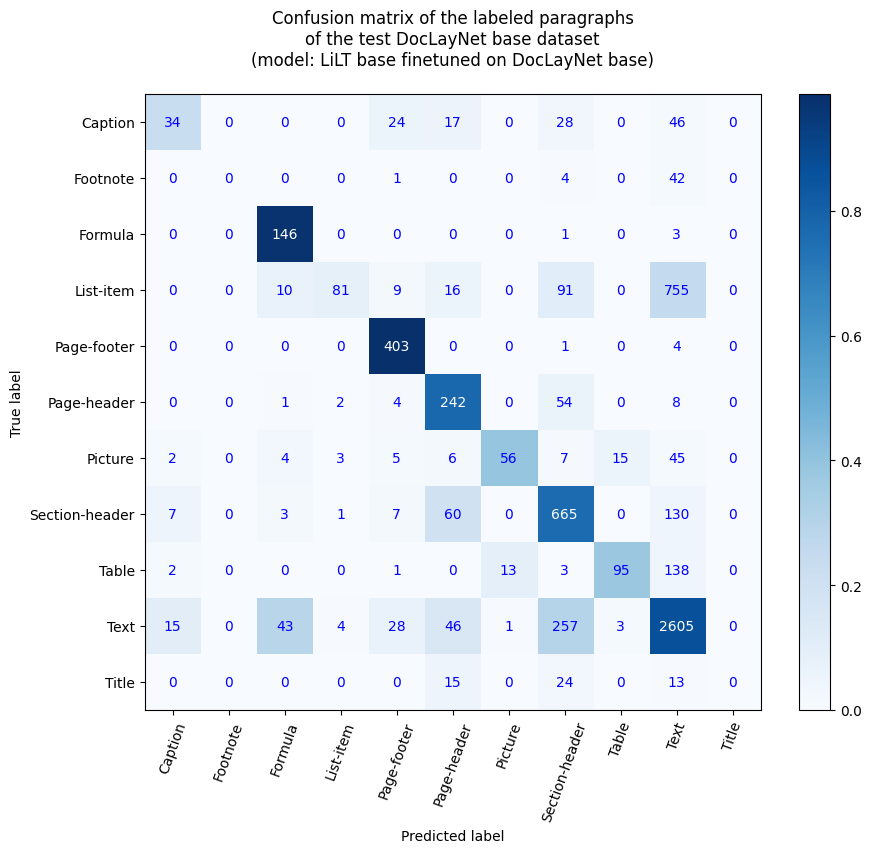
这个模型是在 nielsr/lilt-xlm-roberta-base 数据集上对 DocLayNet base 进行微调的版本。它在评估集上实现了以下结果:
- 损失:0.4104
- 准确率:0.8634
- 召回率:0.8634
- F1得分:0.8634
- 词元准确率:0.8634
- 段落准确率:0.6815
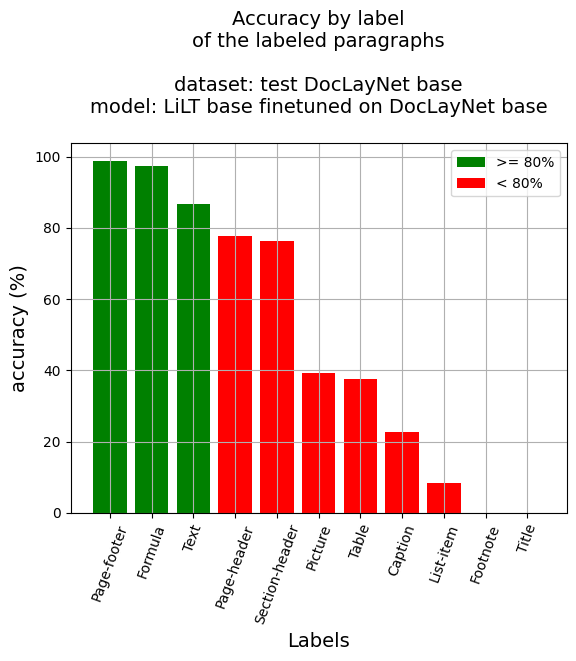
段落级准确率
- 段落准确率:68.15%
- 按标签的准确率
- 标题:22.82%
- 脚注:0.0%
- 公式:97.33%
- 列表项:8.42%
- 页脚:98.77%
- 页眉:77.81%
- 图片:39.16%
- 章节标题:76.17%
- 表格:37.7%
- 文本:86.78%
- 标题:0.0%
参考资料
博客文章
- Layout XLM基础模型
- LiLT基础模型
- (02/16/2023) Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level
- (02/14/2023) Document AI | Inference APP for Document Understanding at line level
- (02/10/2023) Document AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet dataset
- (01/31/2023) Document AI | DocLayNet image viewer APP
- (01/27/2023) Document AI | Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)
笔记本(段落级)
- LiLT基础模型
- Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)
笔记本(行级)
- Layout XLM基础模型
- Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)
- Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- LiLT基础模型
- Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- DocLayNet image viewer APP
- 用于Hugging Face hub布局模型的DocLayNet数据集的处理(微调,推理)
应用
您可以使用Hugging Face Spaces中的此应用测试此模型: Inference APP for Document Understanding at paragraph level (v1) 。
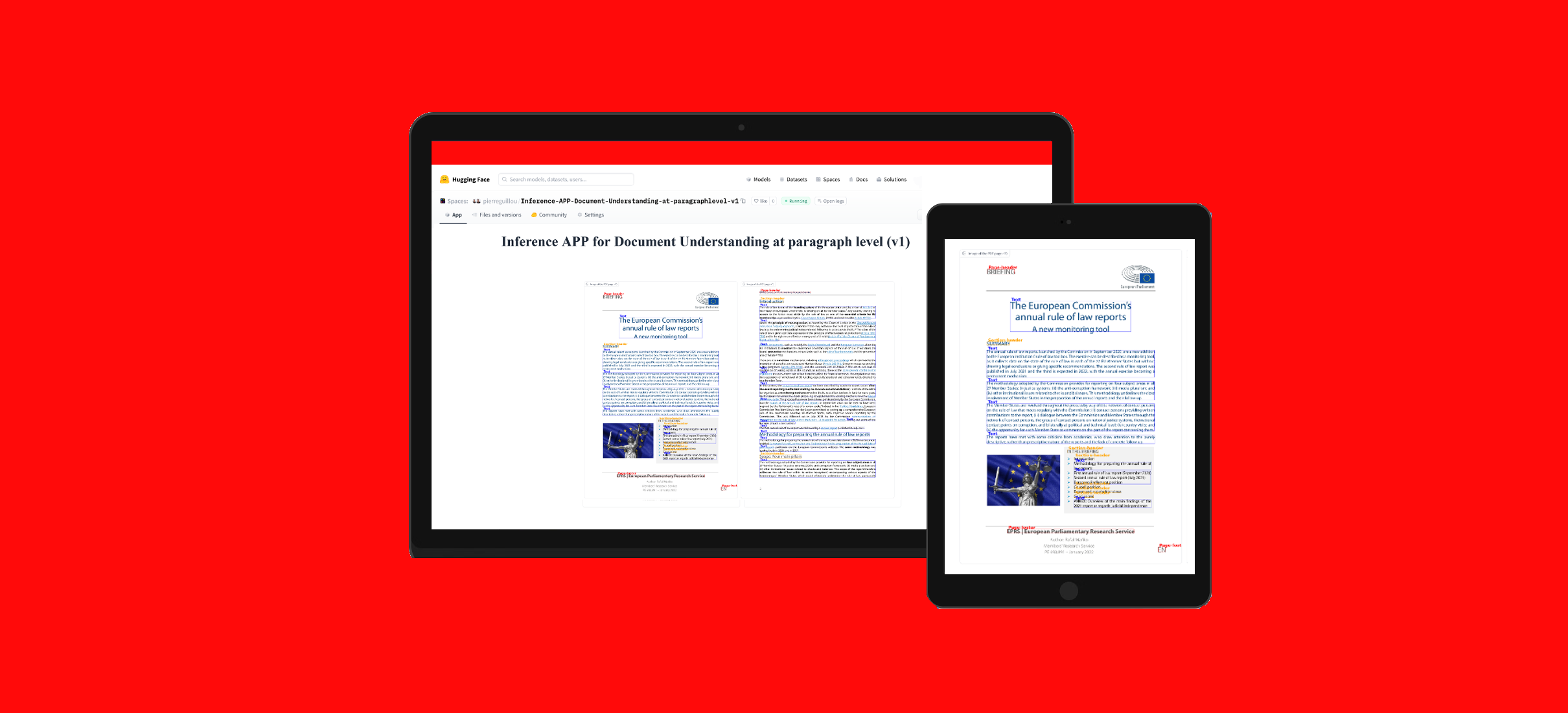
您还可以运行相应的笔记本: Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
DocLayNet数据集
DocLayNet dataset (IBM)使用边界框提供了80863个唯一页面的11个不同类别标签的逐页面布局分割的基本真值,在6个文档类别中。
到目前为止,该数据集可以通过直接链接或作为Hugging Face数据集进行下载:
- 直接链接: doclaynet_core.zip (28 GiB), doclaynet_extra.zip (7.5 GiB)
- Hugging Face数据集库: dataset DocLayNet
论文: DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis (06/02/2022)
模型描述
该模型在512个词元重叠128个词元的块上进行了段落级微调。因此,模型使用了数据集的所有布局和文本数据进行训练。
在推理时,通过计算最佳概率为每个段落的边界框分配标签。
推理
训练和评估数据
训练过程
训练超参数
训练过程中使用了以下超参数:
- 学习率:2e-05
- 训练批量大小:8
- 评估批量大小:16
- 种子:42
- 优化器:使用betas=(0.9,0.999)和epsilon=1e-08的Adam
- lr_scheduler_type:linear
- 迭代次数:1
- 混合精度训练:原生AMP
训练结果
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|---|---|---|---|---|---|---|---|
| No log | 0.05 | 100 | 0.9875 | 0.6585 | 0.6585 | 0.6585 | 0.6585 |
| No log | 0.11 | 200 | 0.7886 | 0.7551 | 0.7551 | 0.7551 | 0.7551 |
| No log | 0.16 | 300 | 0.5894 | 0.8248 | 0.8248 | 0.8248 | 0.8248 |
| No log | 0.21 | 400 | 0.4794 | 0.8396 | 0.8396 | 0.8396 | 0.8396 |
| 0.7446 | 0.27 | 500 | 0.3993 | 0.8703 | 0.8703 | 0.8703 | 0.8703 |
| 0.7446 | 0.32 | 600 | 0.3631 | 0.8857 | 0.8857 | 0.8857 | 0.8857 |
| 0.7446 | 0.37 | 700 | 0.4096 | 0.8630 | 0.8630 | 0.8630 | 0.8630 |
| 0.7446 | 0.43 | 800 | 0.4492 | 0.8528 | 0.8528 | 0.8528 | 0.8528 |
| 0.7446 | 0.48 | 900 | 0.3839 | 0.8834 | 0.8834 | 0.8834 | 0.8834 |
| 0.4464 | 0.53 | 1000 | 0.4365 | 0.8498 | 0.8498 | 0.8498 | 0.8498 |
| 0.4464 | 0.59 | 1100 | 0.3616 | 0.8812 | 0.8812 | 0.8812 | 0.8812 |
| 0.4464 | 0.64 | 1200 | 0.3949 | 0.8796 | 0.8796 | 0.8796 | 0.8796 |
| 0.4464 | 0.69 | 1300 | 0.4184 | 0.8613 | 0.8613 | 0.8613 | 0.8613 |
| 0.4464 | 0.75 | 1400 | 0.4130 | 0.8743 | 0.8743 | 0.8743 | 0.8743 |
| 0.3672 | 0.8 | 1500 | 0.4535 | 0.8289 | 0.8289 | 0.8289 | 0.8289 |
| 0.3672 | 0.85 | 1600 | 0.3681 | 0.8713 | 0.8713 | 0.8713 | 0.8713 |
| 0.3672 | 0.91 | 1700 | 0.3446 | 0.8857 | 0.8857 | 0.8857 | 0.8857 |
| 0.3672 | 0.96 | 1800 | 0.4104 | 0.8634 | 0.8634 | 0.8634 | 0.8634 |
框架版本
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
其他模型
- 行级
- Document Understanding model (finetuned LiLT base at line level on DocLayNet base) (准确率|词元:85.84% - 行:91.97%)
- Document Understanding model (finetuned LayoutXLM base at line level on DocLayNet base) (准确率|词元:93.73% - 行:...)
- 段落级
- Document Understanding model (finetuned LiLT base at paragraph level on DocLayNet base) (准确率|词元:86.34% - 段落:68.15%)
- Document Understanding model (finetuned LayoutXLM base at paragraph level on DocLayNet base) (准确率|词元:96.93% - 段落:86.55%)