










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
pierreguillou/whisper-medium-portuguese



 英文
英文Portuguese Medium Whisper
这个模型是在 common_voice_11_0 数据集上对 openai/whisper-medium 进行微调得到的。在评估集上,它达到了以下结果:
- 损失: 0.2628
- WER: 6.5987
博文
关于这个模型的所有信息在这篇博文中: Speech-to-Text & IA | Transcreva qualquer áudio para o português com o Whisper (OpenAI)... sem nenhum custo!
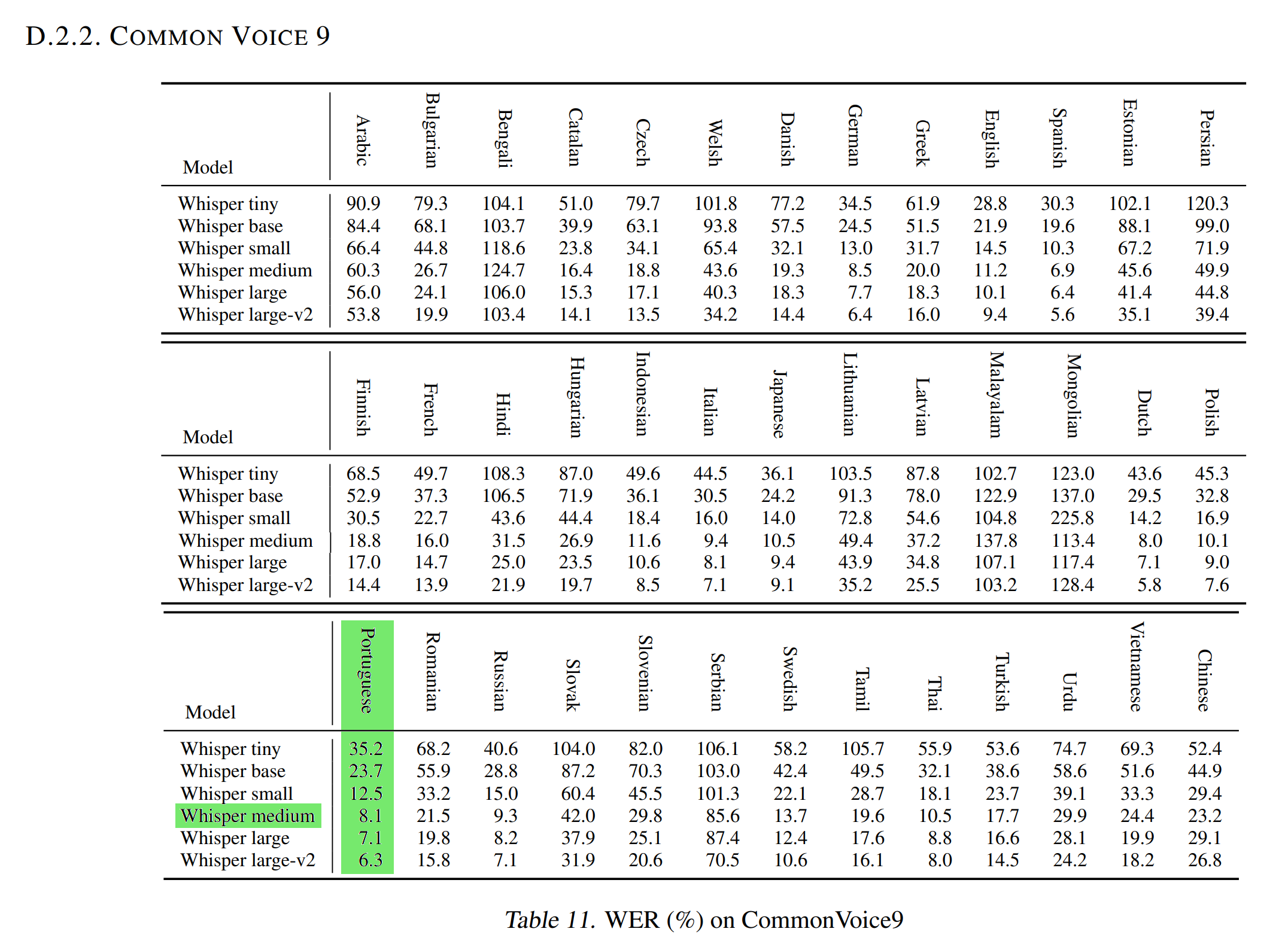
新的 SOTA
在 OpenAI Whisper article 上使用 Common Voice 9.0 的测试数据集的 WER 归一化为 8.1。
由于这个测试数据集与用于评估我们的模型的 Common Voice 11.0 测试数据集相似(WER 和归一化 WER),这意味着我们的 Portuguese Medium Whisper 在将葡萄牙语的音频转录为文本方面优于 Medium Whisper 模型(甚至比 WER 归一化为 7.1 的 Whisper Large 模型更好!)
训练过程
训练超参数
训练过程中使用了以下超参数:
- 学习率: 9e-06
- 训练批次大小: 32
- 评估批次大小: 16
- 种子: 42
- 优化器: Adam,beta=(0.9,0.999),epsilon=1e-08
- lr_scheduler 类型: 线性
- lr_scheduler_warmup_steps: 500
- 训练步数: 6000
- 混合精度训练: Native AMP
训练结果
| Training Loss | Epoch | Step | Validation Loss | Wer |
|---|---|---|---|---|
| 0.0333 | 2.07 | 1500 | 0.2073 | 6.9770 |
| 0.0061 | 5.05 | 3000 | 0.2628 | 6.5987 |
| 0.0007 | 8.03 | 4500 | 0.2960 | 6.6979 |
| 0.0004 | 11.0 | 6000 | 0.3212 | 6.6794 |
框架版本
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2