










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
s-nlp/Mutual_Implication_Score

 英文
英文模型概述
互相关得分是一种基于 RoBERTA 模型的文本语义相似度对称度量,该模型在自然语言推理上进行了预训练,并在同义检测数据集上进行了微调。
推理和评估模型的代码可在此处获取: here 。
这种度量方法特别适用于同义检测,但也可以应用于其他语义相似性任务,如文本风格转换中的内容相似度评分。
如何使用
以下代码段演示了代码的使用方法:
!pip install mutual-implication-score
from mutual_implication_score import MIS
mis = MIS(device='cpu')#cuda:0 for using cuda with certain index
source_texts = ['I want to leave this room',
'Hello world, my name is Nick']
paraphrases = ['I want to go out of this room',
'Hello world, my surname is Petrov']
scores = mis.compute(source_texts, paraphrases)
print(scores)
# expected output: [0.9748, 0.0545]
模型细节
我们稍微修改了 RoBERTa-Large NLI 模型架构(如下所示),并使用 QQP 同义检测数据集进行了微调。
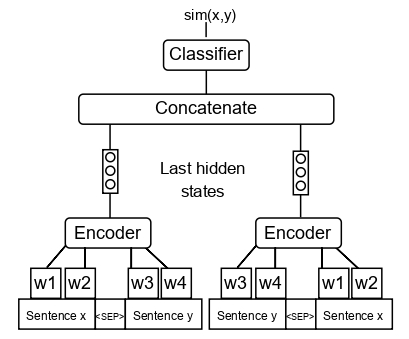
在文本风格转换和同义检测任务上的性能
这个度量方法是在文本风格转换和同义检测数据集上进行大规模比较的基础上开发的。
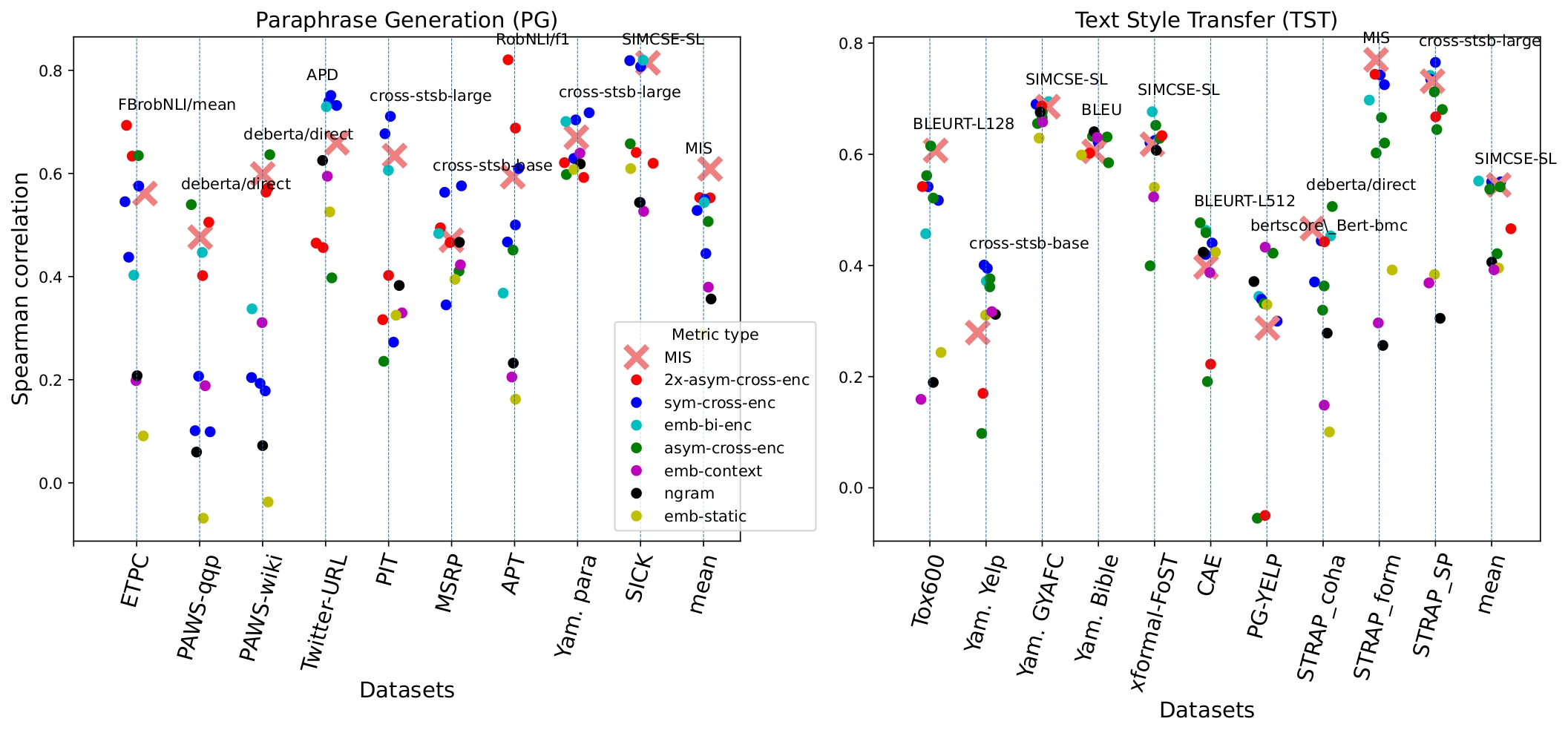
上面的图表显示了不同类别的度量方法与人工判断的同义检测和文本风格转换数据集之间的相关性。数据集上方的文本表示最佳表现的度量方法。最右侧的列显示了度量方法在数据集上的平均性能。
互相关得分在同义检测任务上表现优于所有其他度量方法,并在文本风格转换任务上与顶级度量方法的性能相当。
欲了解更多信息,请参阅我们的文章: A large-scale computational study of content preservation measures for text style transfer and paraphrase generation
引用
如果您觉得这个存储库有用,请随意引用我们的出版物:
@inproceedings{babakov-etal-2022-large,
title = "A large-scale computational study of content preservation measures for text style transfer and paraphrase generation",
author = "Babakov, Nikolay and
Dale, David and
Logacheva, Varvara and
Panchenko, Alexander",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-srw.23",
pages = "300--321",
abstract = "Text style transfer and paraphrasing of texts are actively growing areas of NLP, dozens of methods for solving these tasks have been recently introduced. In both tasks, the system is supposed to generate a text which should be semantically similar to the input text. Therefore, these tasks are dependent on methods of measuring textual semantic similarity. However, it is still unclear which measures are the best to automatically evaluate content preservation between original and generated text. According to our observations, many researchers still use BLEU-like measures, while there exist more advanced measures including neural-based that significantly outperform classic approaches. The current problem is the lack of a thorough evaluation of the available measures. We close this gap by conducting a large-scale computational study by comparing 57 measures based on different principles on 19 annotated datasets. We show that measures based on cross-encoder models outperform alternative approaches in almost all cases.We also introduce the Mutual Implication Score (MIS), a measure that uses the idea of paraphrasing as a bidirectional entailment and outperforms all other measures on the paraphrase detection task and performs on par with the best measures in the text style transfer task.",
}
许可信息
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License 。
