

















模型:
shi-labs/versatile-diffusion


 英文
英文Versatile Diffusion V1.0模型卡片
我们构建了Versatile Diffusion(VD),作为通往通用生成人工智能的一步,VD是第一个统一的多流多模态扩散框架。Versatile Diffusion可以原生地支持图像到文本、图像变化、文本到图像和文本变化,并且可以进一步扩展到其他应用,如语义-风格解缠、图像-文本双引导生成、潜在图像-文本-图像编辑等。未来版本将支持更多模态,如语音、音乐、视频和3D。
模型详情
Versatile Diffusion的一个单一流程包含一个VAE,一个扩散器和一个上下文编码器,因此可以在一个数据类型(例如图像)和一个上下文类型(例如文本)下处理一个任务(例如文本到图像)。Versatile Diffusion的多流程结构显示在以下图表中:
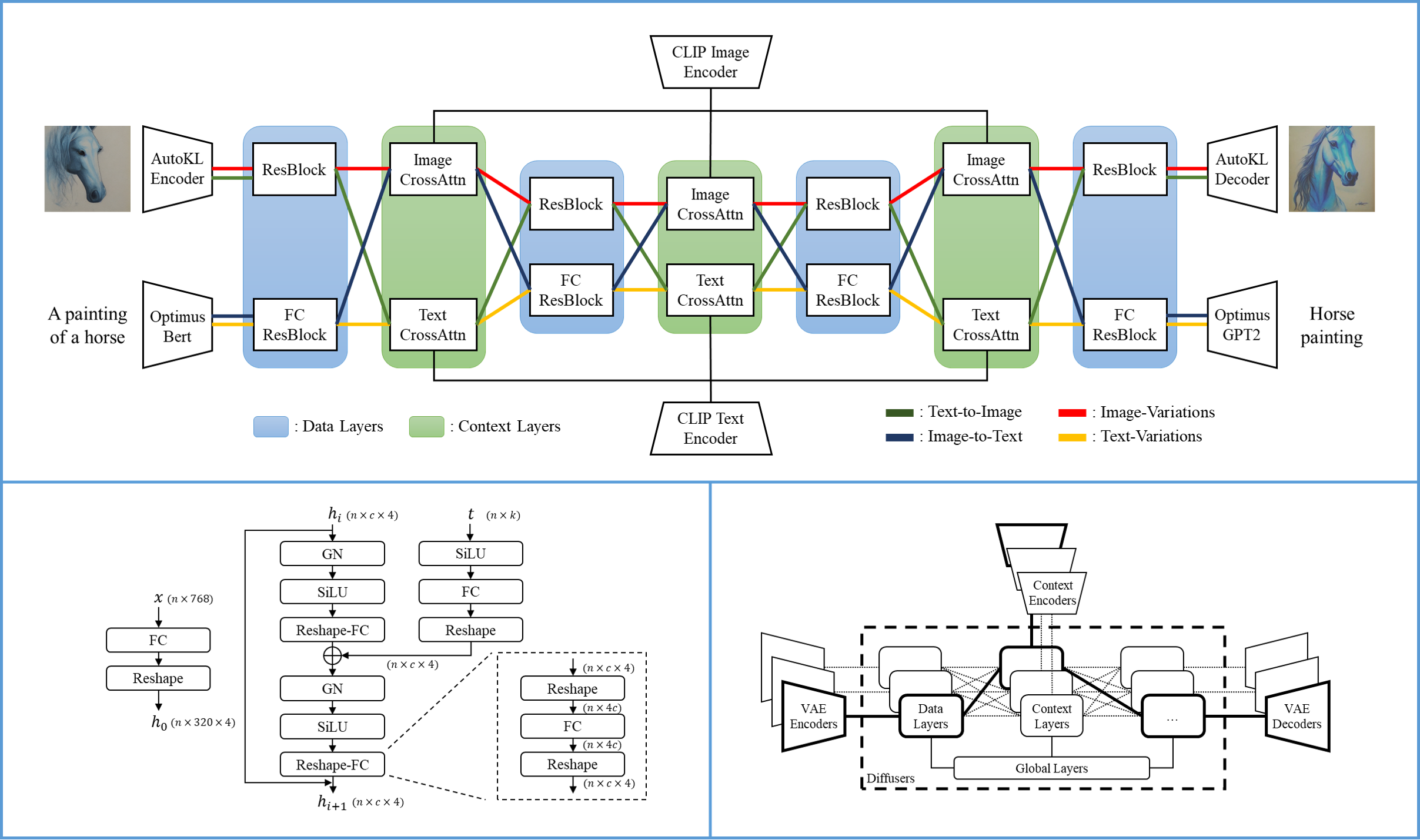
- 开发者:Xingqian Xu, Atlas Wang, Eric Zhang, Kai Wang和Humphrey Shi
- 模型类型:基于扩散的多模态生成模型
- 语言:英文
- 许可证:MIT
- 更多信息的资源: GitHub Repository , Paper
- 引用方式:
@article{xu2022versatile,
title = {Versatile Diffusion: Text, Images and Variations All in One Diffusion Model},
author = {Xingqian Xu, Zhangyang Wang, Eric Zhang, Kai Wang, Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2211.08332},
eprint = {2211.08332},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
使用方法
您可以使用模型与 ?Diffusers library 和 SHI-Labs Versatile Diffusion codebase 。
? 扩散器
扩散器可以让您同时使用统一和更省内存的、任务特定的流水线。
请确保安装transformers从"main"以使用此模型:
pip install git+https://github.com/huggingface/transformers
VersatileDiffusionPipeline
要在所有任务中使用Versatile Diffusion,建议使用 VersatileDiffusionPipeline
#! pip install git+https://github.com/huggingface/transformers diffusers torch
from diffusers import VersatileDiffusionPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
pipe = VersatileDiffusionPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# prompt
prompt = "a red car"
# initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
# text to image
image = pipe.text_to_image(prompt).images[0]
# image variation
image = pipe.image_variation(image).images[0]
# image variation
image = pipe.dual_guided(prompt, image).images[0]
特定任务
特定任务的流水线只会加载需要的权重到GPU。您可以在 here 中找到所有任务特定的流水线。
您可以按照以下方式使用它们:
文本到图像
from diffusers import VersatileDiffusionTextToImagePipeline
import torch
pipe = VersatileDiffusionTextToImagePipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe.remove_unused_weights()
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
image = pipe("an astronaut riding on a horse on mars", generator=generator).images[0]
image.save("./astronaut.png")
图像变化from diffusers import VersatileDiffusionImageVariationPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
# download an initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
pipe = VersatileDiffusionImageVariationPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
image = pipe(image, generator=generator).images[0]
image.save("./car_variation.png")
双引导生成from diffusers import VersatileDiffusionDualGuidedPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
# download an initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
text = "a red car in the sun"
pipe = VersatileDiffusionDualGuidedPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe.remove_unused_weights()
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
text_to_image_strength = 0.75
image = pipe(prompt=text, image=image, text_to_image_strength=text_to_image_strength, generator=generator).images[0]
image.save("./red_car.png")
原始GitHub仓库
请按照 here 中的说明操作。
注意事项、偏见和内容声明
我们希望提醒用户注意此演示可能存在的问题和关注点。与之前的大型基础模型类似,Versatile Diffusion在某些情况下可能存在问题,部分原因是由于不完善的训练数据和词向量编码器/上下文编码器等预训练网络的局限性。在其未来的研究阶段,VD可能在文本到图像、图像到文本等任务上表现更好,通过更强大的VAE、更复杂的网络设计和更干净的数据进行改进。到目前为止,我们保持了所有功能可用于研究测试,以展示VD框架的巨大潜力,并收集重要反馈以改进模型。我们欢迎研究人员和用户通过HuggingFace社区讨论功能或通过电子邮件向作者报告问题。
请注意,VD可能输出强化或加剧社会偏见的内容,以及逼真的面孔、色情和暴力。VD是在LAION-2B数据集上训练的,该数据集抓取了未经筛选的在线图像和文本,可能包含意外的例外,因为我们删除了非法内容。此演示中的VD仅用于研究目的。