










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
snunlp/KR-FinBert


 英文
英文KR-FinBert 和 KR-FinBert-SC
在自然语言处理(NLP)领域取得了很大的进展,大量研究表明,使用小规模语料库进行领域适应,并使用标注数据进行微调,对于整体性能的提升是有效的。我们提出了KR-FinBert模型,通过在金融语料库上进一步进行预训练,并在情感分析任务上进行微调。正如许多研究所显示的那样,通过适应和进行下游任务,在这个实验中也明显改善了性能。
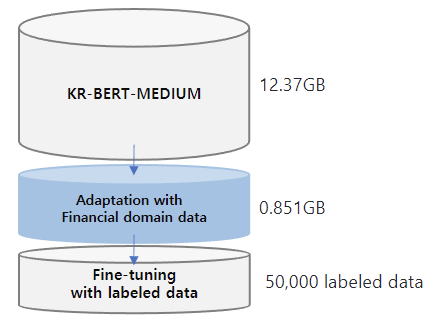
数据
该模型的训练数据是从 KR-BERT-MEDIUM 中扩充而来的,包括韩文维基百科中的文本、普通新闻文章、从国家法律信息中心爬取的法律文本,以及 Korean Comments dataset 。为了进行迁移学习,还添加了来自72家媒体源(如《金融时报》、《韩国经济日报》等)的与公司相关的经济新闻文章,以及来自16家证券公司(如Kiwoom证券、三星证券等)的分析报告。数据集中包括440,067个新闻标题及其内容和11,237份分析报告。总数据大小约为13.22GB。为了进行mlm训练,我们将数据按行分割,总行数为6,379,315。KR-FinBert模型进行了5.5M个步骤的训练,最大长度为512,训练批次大小为32,学习率为5e-5,使用NVIDIA TITAN XP训练模型共花费了67.48小时。
引用
@misc{kr-FinBert,
author = {Kim, Eunhee and Hyopil Shin},
title = {KR-FinBert: KR-BERT-Medium Adapted With Financial Domain Data},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://huggingface.co/snunlp/KR-FinBert}}
}