










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
speechbrain/m-ctc-t-large



 英文
英文M-CTC-T
Meta AI提供的面向多语种的大规模语音识别器。该模型是一个具有10亿参数的Transformer编码器,其中带有8065个字符标签的CTC头部和60个语言ID标签的语言识别头部。它是在Common Voice(版本6.1,2020年12月发布)和VoxPopuli上进行训练的。在Common Voice和VoxPopuli上训练之后,该模型仅在Common Voice上进行训练。标签是未归一化的字符级转录(不移除标点符号和大写字母)。该模型接收16kHz音频信号的Mel滤波器组特征作为输入。
原始的Flashlight代码、模型检查点和Colab笔记本可在此处找到。
引用
作者:Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, Ronan Collobert
@article{lugosch2021pseudo,
title={Pseudo-Labeling for Massively Multilingual Speech Recognition},
author={Lugosch, Loren and Likhomanenko, Tatiana and Synnaeve, Gabriel and Collobert, Ronan},
journal={ICASSP},
year={2022}
}
贡献
特别感谢 Chan Woo Kim 将该模型从Flashlight C++转换为PyTorch。
训练方法
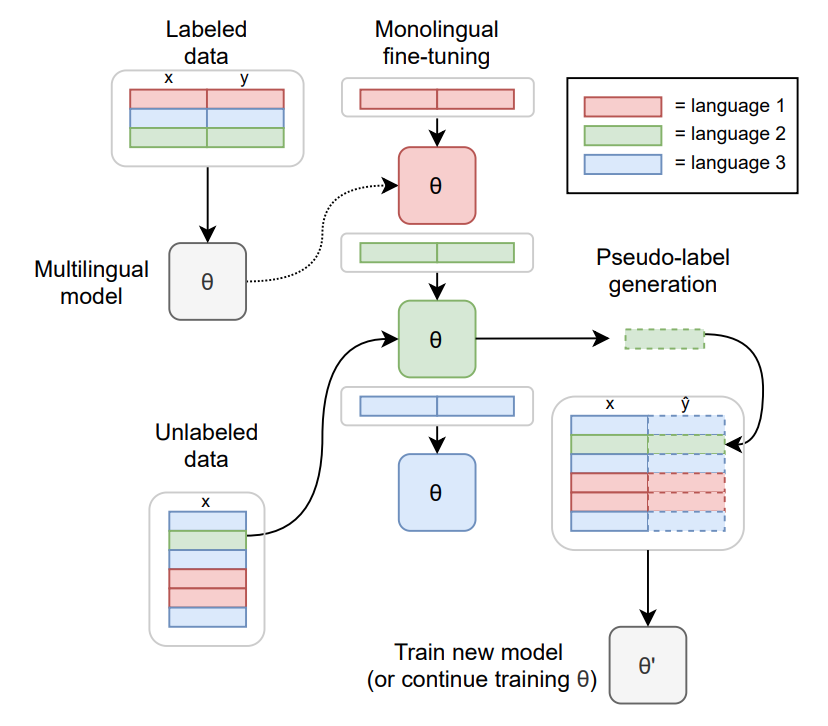 有关模型训练方法的更多信息,请参阅此处。
有关模型训练方法的更多信息,请参阅此处。
使用
可以将该模型用作独立的声学模型来转录音频文件,方法如下:
import torch
import torchaudio
from datasets import load_dataset
from transformers import MCTCTForCTC, MCTCTProcessor
model = MCTCTForCTC.from_pretrained("speechbrain/m-ctc-t-large")
processor = MCTCTProcessor.from_pretrained("speechbrain/m-ctc-t-large")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# feature extraction
input_features = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt").input_features
# retrieve logits
with torch.no_grad():
logits = model(input_features).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
在所有语言上的Common Voice结果的平均值:
字符错误率(CER):
| "Valid" | "Test" |
|---|---|
| 21.4 | 23.3 |
问题和帮助
如果您对此模型有疑问或需要帮助,请考虑在该存储库上开启讨论或拉取请求,并标记@lorenlugosch、@cwkeam或@patrickvonplaten