










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
stanfordnlp/backpack-gpt2



 英文
英文Backpack-GPT2背包模型卡片
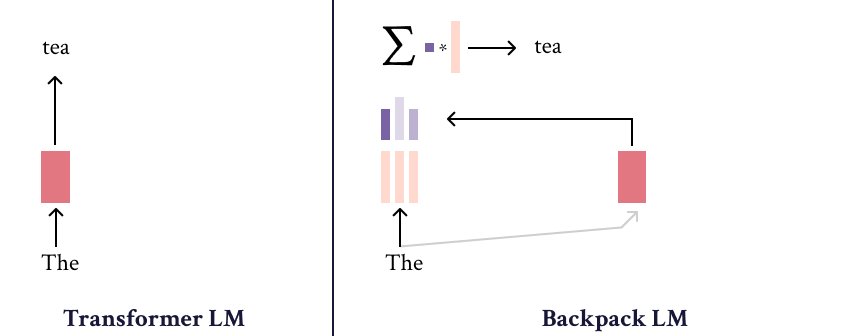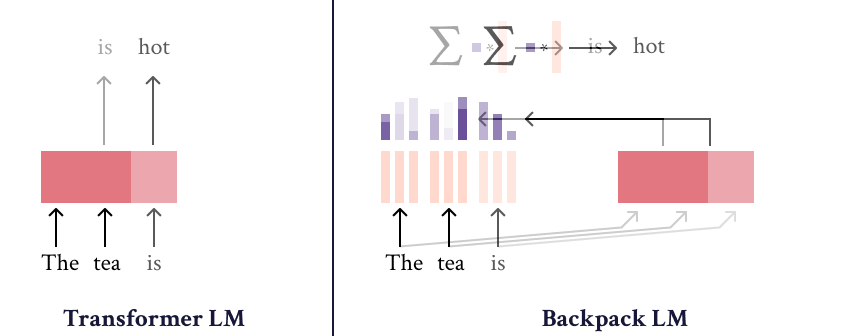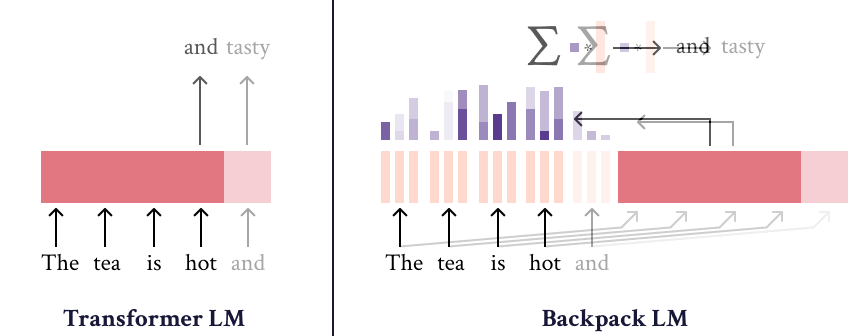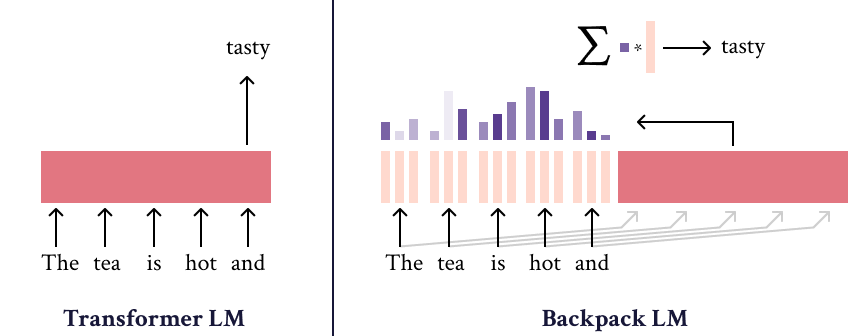
Backpack-GPT2语言模型是的一种实例,旨在将强大的建模性能与可解释性和控制界面相结合。关于该模型及其训练的大部分细节应在论文中查阅。
详见 backpackmodels.science。
目录
- Backpack-GPT2背包模型卡片
- 目录
- 模型详情
- 模型描述
- 用途
- 偏见、风险和限制
- 训练详情
- 训练数据
- 训练过程
- 环境影响
- 技术规格 [可选]
- 模型结构和目标
- 计算基础设施
- 硬件
- 软件
- 引用
- 模型卡片作者 [可选]
- 模型卡片联系方式
- 如何开始使用该模型
模型详情
模型描述
Backpack-GPT2是一种的 Backpack-based language model ,旨在将强大的建模性能与可解释性和控制界面相结合。
- 开发者:John Hewitt,John Thickstun,Christopher D. Manning,Percy Liang
- 共享者 [可选]:需要更多信息
- 模型类型:语言模型
- 语言(NLP):英语
- 许可证:apache-2.0
- 获取更多信息的资源:
用途
该模型用于研究和开发自然语言处理中越来越可解释的方法。它不适用于任何实际生产用途。
偏见、风险和限制
大量研究已探讨语言模型的偏见和公平性问题(参见例如 Sheng et al. (2021) 和 Bender et al. (2021) )。模型生成的预测可能包含保护类别、身份特征以及敏感的社会与职业群体之间的令人不安和有害的刻板印象。这个特定模型在能力上有限,由于是全新的架构,对其偏见的了解较少,相比Transformer模型等模型来说。
训练详情
训练数据
该模型在 OpenWebText 语料库上进行了训练。
训练过程
该模型通过100k个梯度步骤进行了训练,批量大小为512k个标记,学习率从6e-4线性衰减至零,具有5k步的线性预热。
环境影响
- 硬件类型:4个A100 GPU(40G)
- 使用时间:大约4天
- 云提供商:Stanford计算机
- 计算区域:Stanford能源网络
模型架构和目标
该模型经过训练以最小化交叉熵损失,是一个 Backpack language model 模型。
计算基础设施
该模型在一个slurm集群上进行了训练。
硬件
该模型在4个A100上进行了训练。
软件
该模型使用了 FlashAttention 和 PyTorch 进行训练。
引用
BibTeX:
@InProceedings{hewitt2023backpack,
author = "Hewitt, John and Thickstun, John and Manning, Christopher D. and Liang, Percy",
title = "Backpack Language Models",
booktitle = "Proceedings of the Association for Computational Linguistics",
year = "2023",
publisher = "Association for Computational Linguistics",
location = "Toronto, Canada",
}
模型卡片作者 [可选]
John Hewitt
模型卡片联系方式
johnhew@cs.stanford.edu
如何开始使用该模型
import torch
import transformers
from transformers import AutoModelForCausalLM
model_id = "stanfordnlp/backpack-gpt2"
config = transformers.AutoConfig.from_pretrained(model_id, trust_remote_code=True)
torch_model = AutoModelForCausalLM.from_pretrained(model_id, config=config, trust_remote_code=True)
torch_model.eval()
input = torch.randint(0, 50264, (1, 512), dtype=torch.long)
torch_out = torch_model(
input,
position_ids=None,
)
torch_out = torch.nn.functional.softmax(torch_out.logits, dim=-1)
print(torch_out)
点击展开 需要更多信息