











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用Numpy手动实现多层卷积神经网络教程详解
2018年03月10日 由 yuxiangyu 发表
351355
0
在过去,我曾写过一篇关于“理解在最大池化层和转置卷积的反向传播”的文章。现在我想要使用这些知识做一个多层(或者说多通道)的卷积神经网络。
在阅读本文之前我建议你可以看一下下面两个链接的内容(都是探讨舍弃反向传播给人工智能找到新方向的):
链接1:https://www.quora.com/Why-is-Geoffrey-Hinton-suspicious-of-backpropagation-and-wants-AI-to-start-over
链接2:https://medium.com/intuitionmachine/the-deeply-suspicious-nature-of-backpropagation-9bed5e2b085e
标准的反向传播对每个激活函数都有适当的导数。对于标准的全连接层来说,这没什么特别之处。
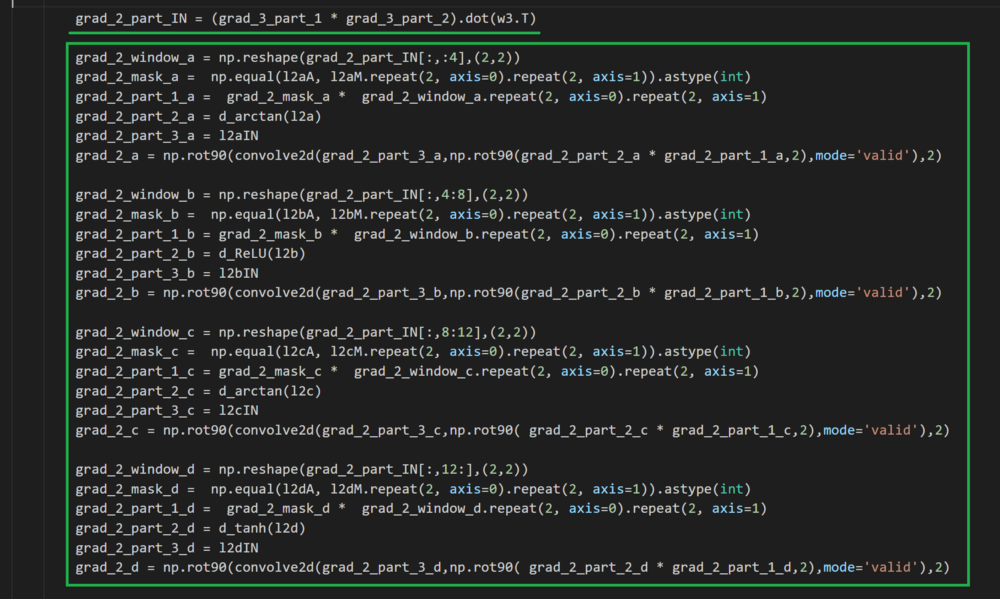
第一行代码(下划线绿色)→返回从前一层的传播
绿框→在W2a,W2b,W2c和W2d各自的规则中计算梯度。
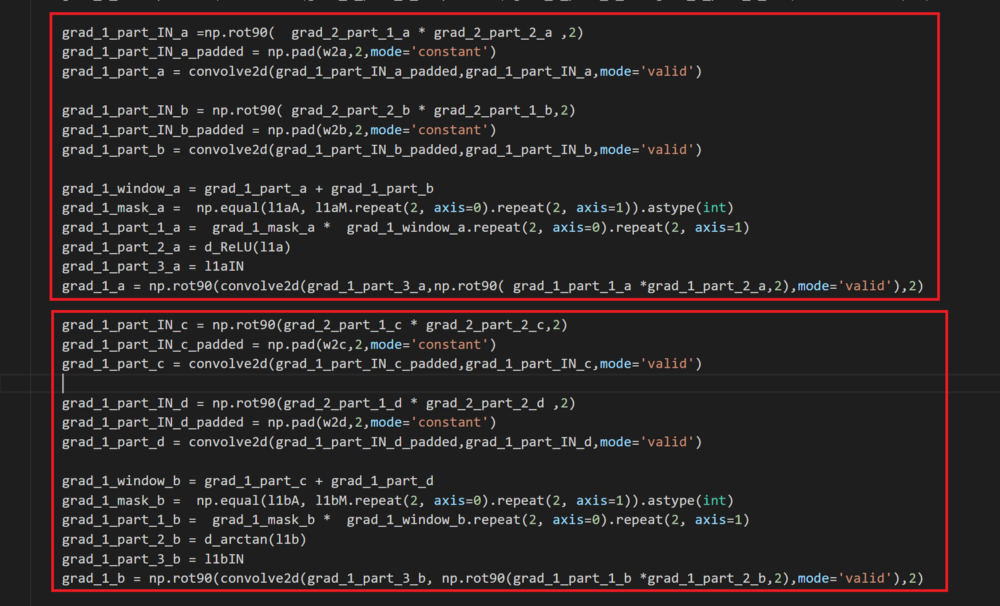
第一个红框→W1a的梯度
第二个红框→W2a的梯度
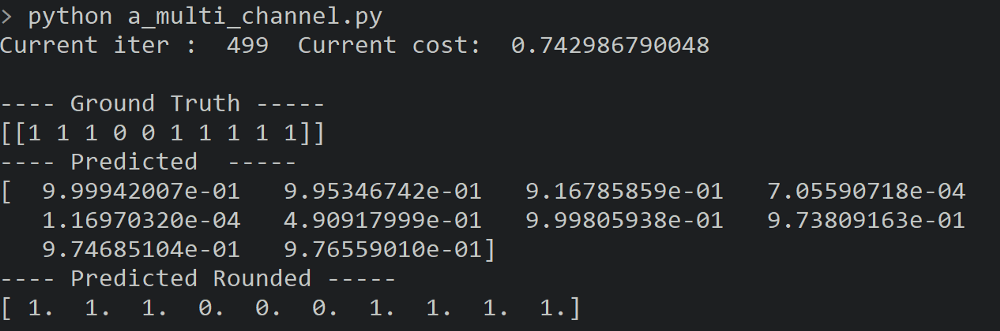
很好,结果最后的结果还不算太糟。如上所示,训练次数设置为500。网络将测试集中的每个图像分类(除了一个错的)。
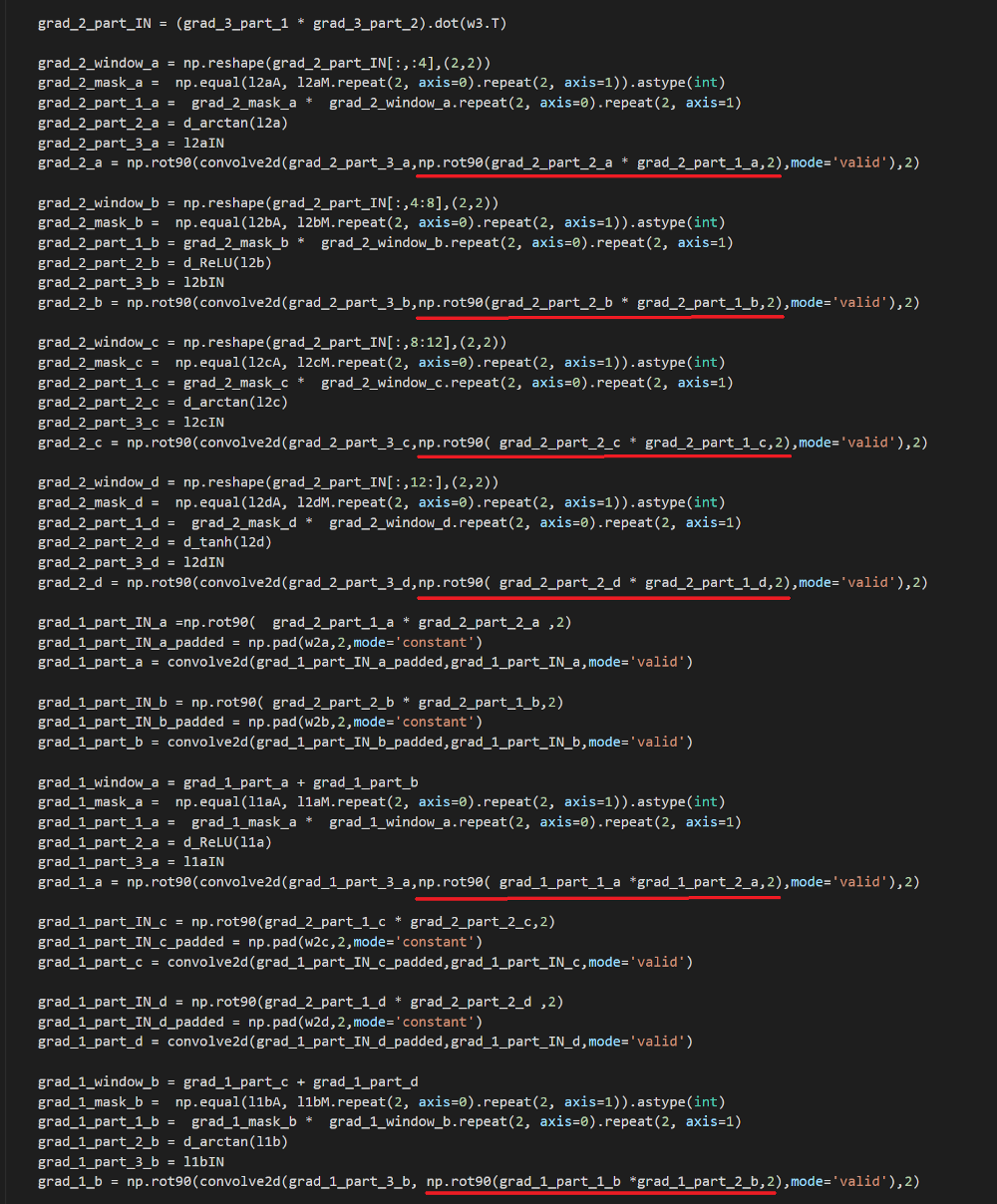
这样上面已经是合适的反向传播了,在这里,我们对上一层的导数和激活函数的导数进行微分运算。然而,出于好奇,我决定做下面的事情。
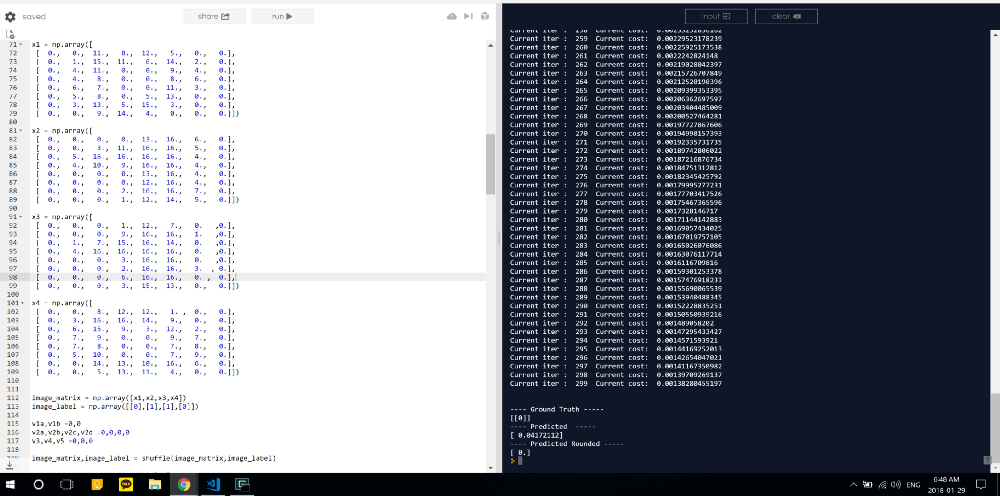
注意:在线编译器没有“从sklearn中导入数据集”,所以我无法复制和粘贴笔记本电脑上使用的代码。所以我复制了四个训练示例,它们分别代表0,1,1,0的手写数字,并调整了超参数。
访问原始网络代码:https://repl.it/@Jae_DukDuk/Multi-Channel-and-Layer-Original
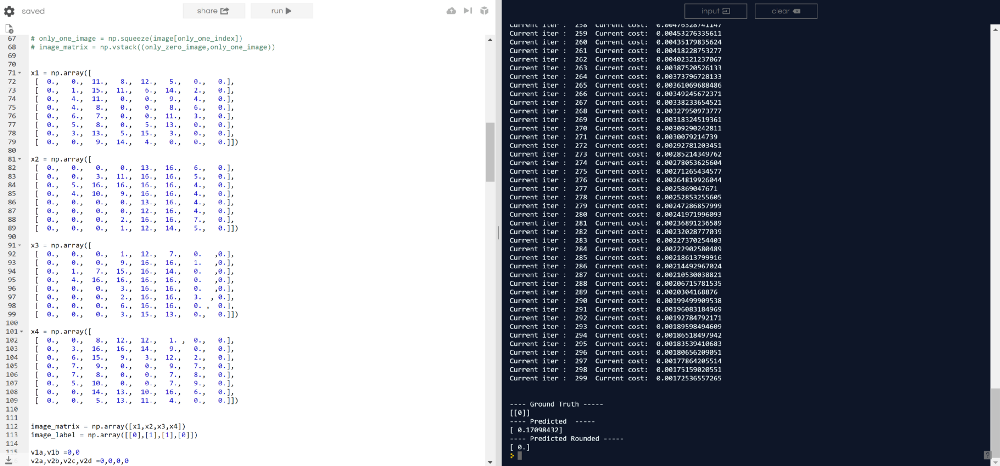
注意:在线编译器没有“从sklearn中导入数据集”,所以我无法复制和粘贴笔记本电脑上使用的代码。所以我复制了四个训练示例,它们分别代表0,1,1,0的手写数字,并调整了超参数。
访问折回网络代码:https://repl.it/@Jae_DukDuk/Multi-Channel-and-Layer-Broken
在阅读本文之前我建议你可以看一下下面两个链接的内容(都是探讨舍弃反向传播给人工智能找到新方向的):
链接1:https://www.quora.com/Why-is-Geoffrey-Hinton-suspicious-of-backpropagation-and-wants-AI-to-start-over
链接2:https://medium.com/intuitionmachine/the-deeply-suspicious-nature-of-backpropagation-9bed5e2b085e
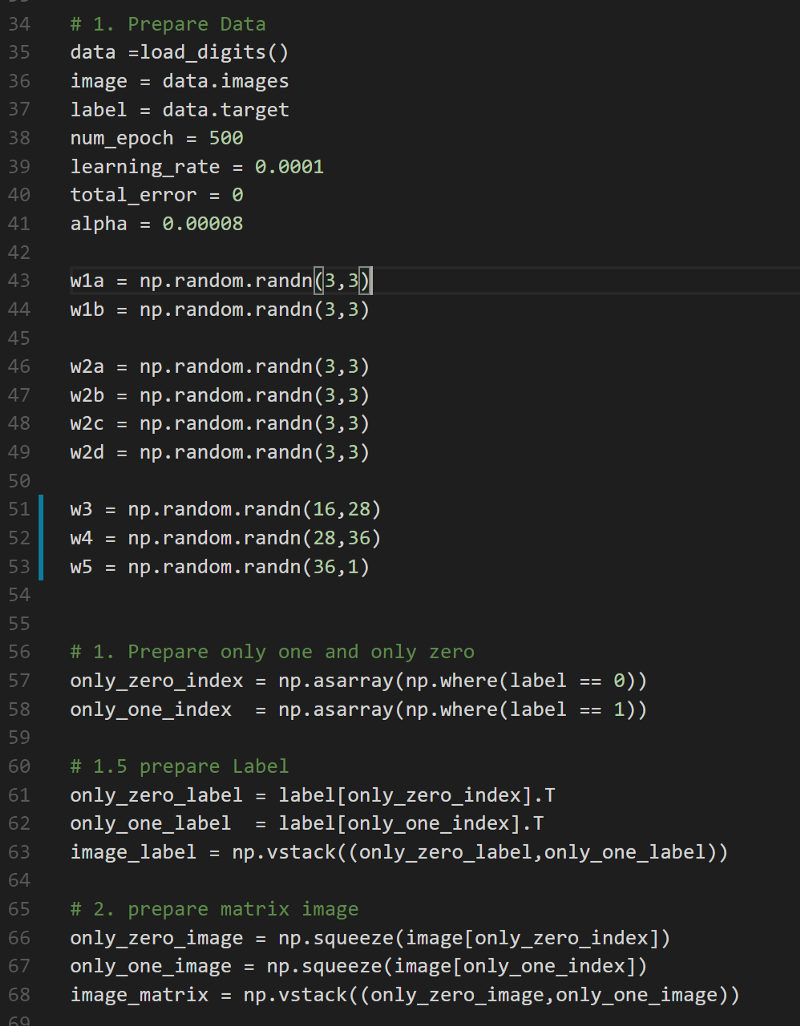
加载训练数据并声明超参数
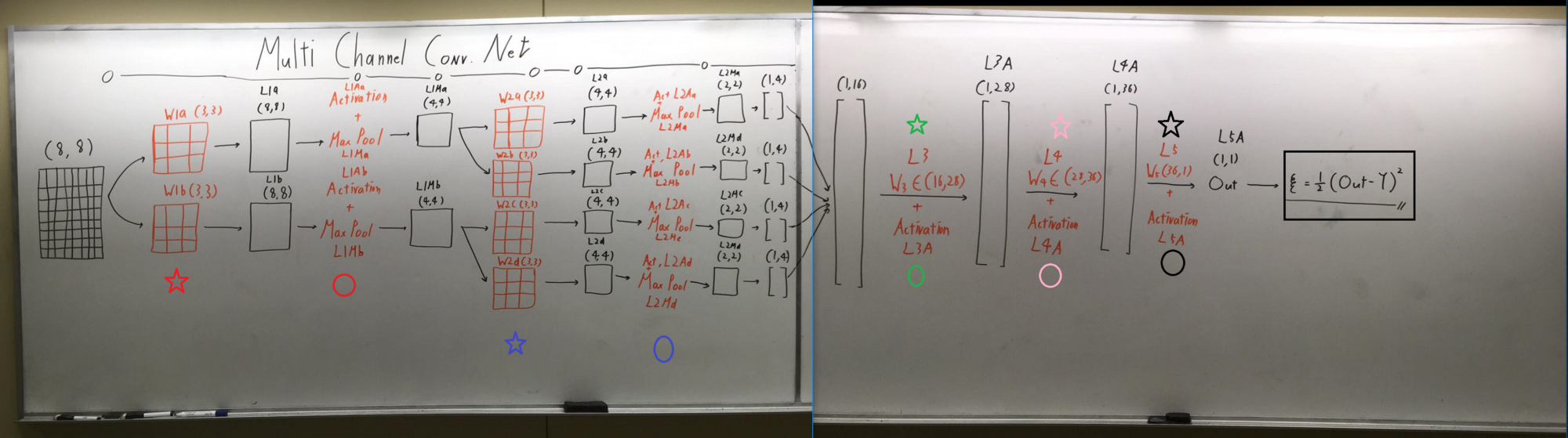
网络架构
输入→尺寸为(8 * 8)的图像
红星→具有两个不同通道的第1层
红圈→将激活和最大池化层应用在第1层
蓝星→具有四个不同通道的第2层
蓝圈→将激活和最大池化的操作应用在第2层
绿星→全连接权重(W3)尺寸为(16 * 28)的第3层
绿圈→激活函数应用于第3层
粉星→全连接权重(W4)尺寸为(28 * 36)的第4层
粉圈→激活层应用于第4层
黑星→全连接权重(W5)尺寸为(36 * 1)的第5层
黑圈→应用于第5层的激活层
黑匣子→使用L2范数的代价函数
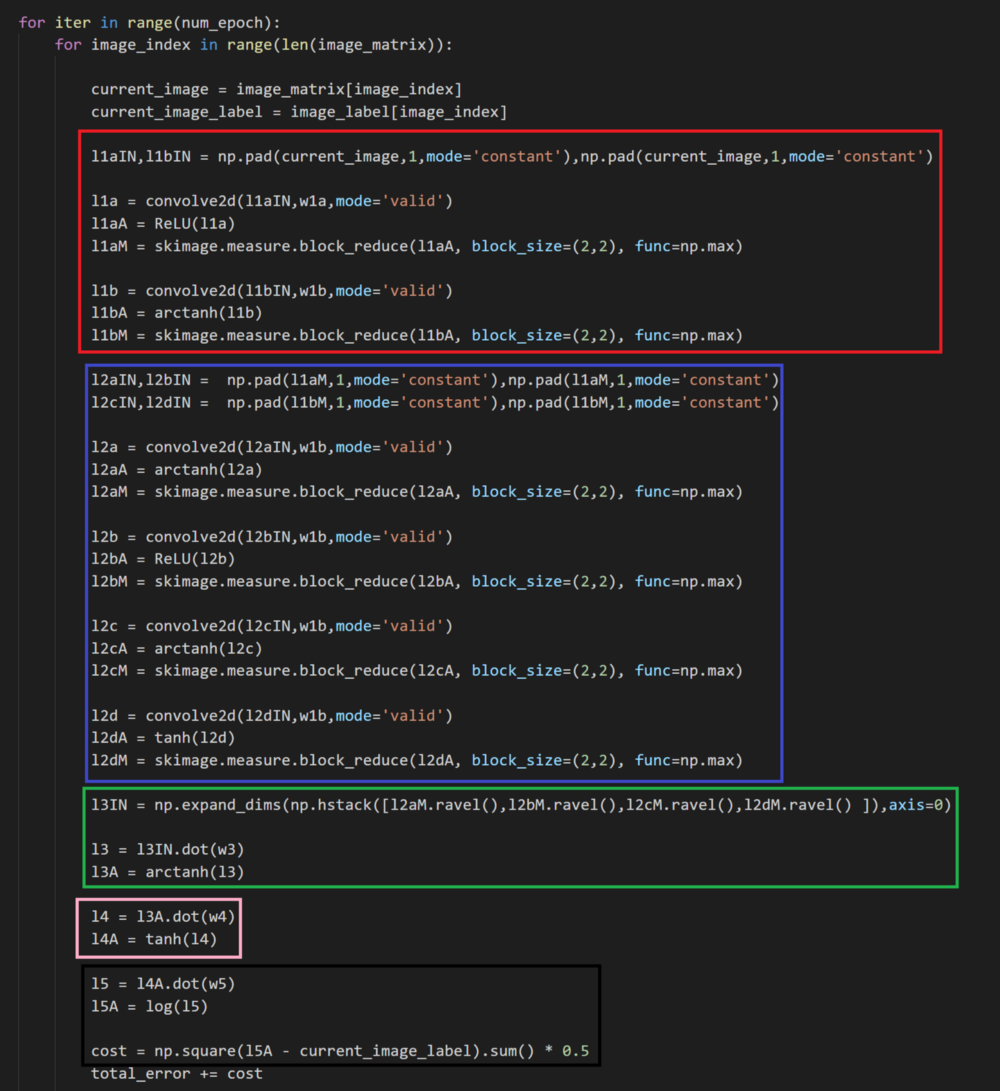
前馈操作的实现
每自颜色的框代表了该层的操作,这里需要注意两点。
- 我在每个卷积层之前执行零填充以维持尺寸。
- 每个层使用激活函数是不同的。
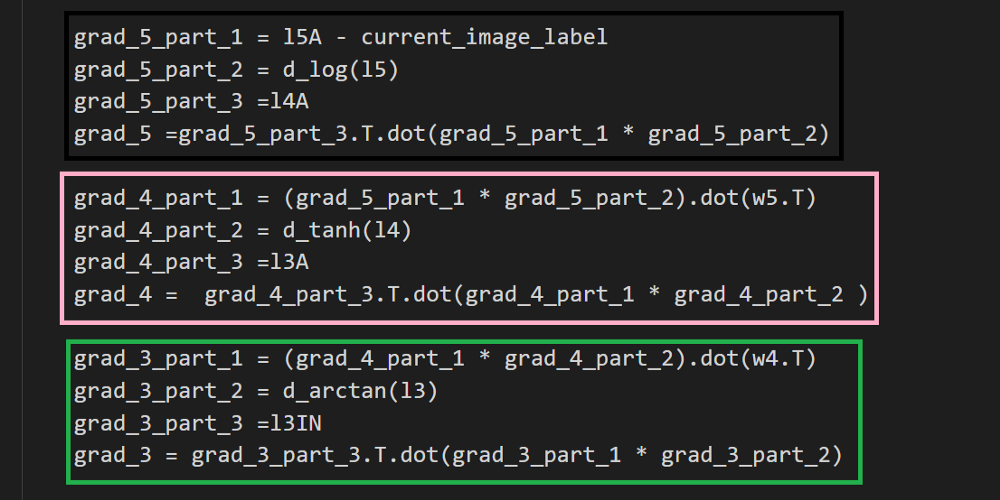
对W5、W4和W3的实施反向传播
标准的反向传播对每个激活函数都有适当的导数。对于标准的全连接层来说,这没什么特别之处。
对所有W2(W2a,W2b,W2c和W2d)实施反向传播
第一行代码(下划线绿色)→返回从前一层的传播
绿框→在W2a,W2b,W2c和W2d各自的规则中计算梯度。
对所有W1(W1a和W1b)实施反向传播
第一个红框→W1a的梯度
第二个红框→W2a的梯度
训练和结果
很好,结果最后的结果还不算太糟。如上所示,训练次数设置为500。网络将测试集中的每个图像分类(除了一个错的)。
破解在反向传播中的数学原理
这样上面已经是合适的反向传播了,在这里,我们对上一层的导数和激活函数的导数进行微分运算。然而,出于好奇,我决定做下面的事情。
蓝线→简单的元素智能乘法
绿线→仅对计算后的最大池层的导数进行转置
红线→仅在最大池层面的掩码执行转置。
为了方便起见,我将把上述网络称为折回网络(back prop net)。
我并不期待网络在改变之后表现更好,只是好奇而已。但是,看看下面显示的结果。我每次都用不同的超参数进行了三次不同的实验。(只更改最后全连接层的尺寸。)
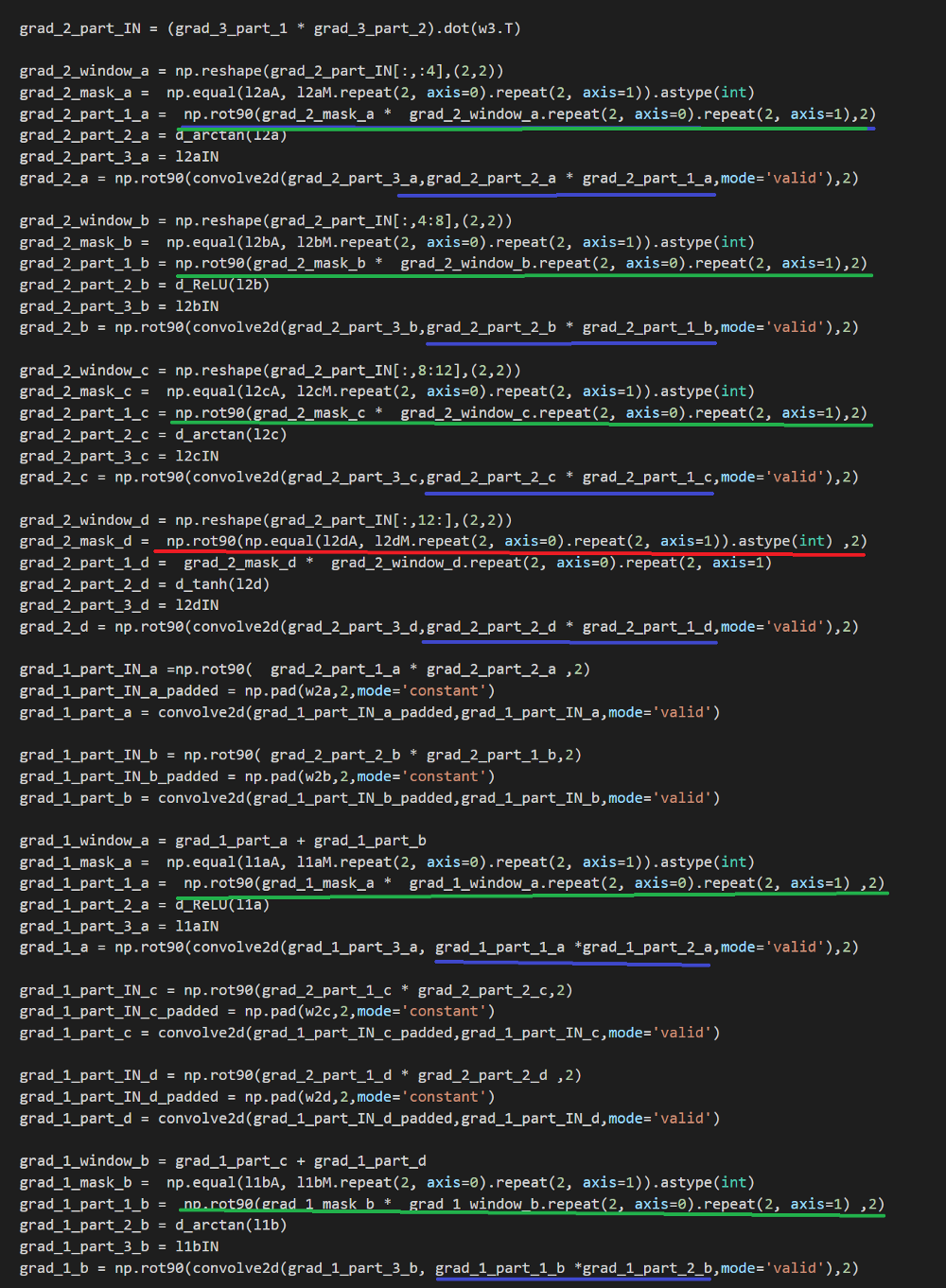
结果1:W3(16 * 18),W4(18 * 20)和W5(20,1)
红框→折回网络的结果。
蓝色框→原始网络结果
你能看到,在第一个实验中,两个网络测试数据具有100%的准确率,然而在第250个周期时折回网络的代价(或者说成本cost)较低。
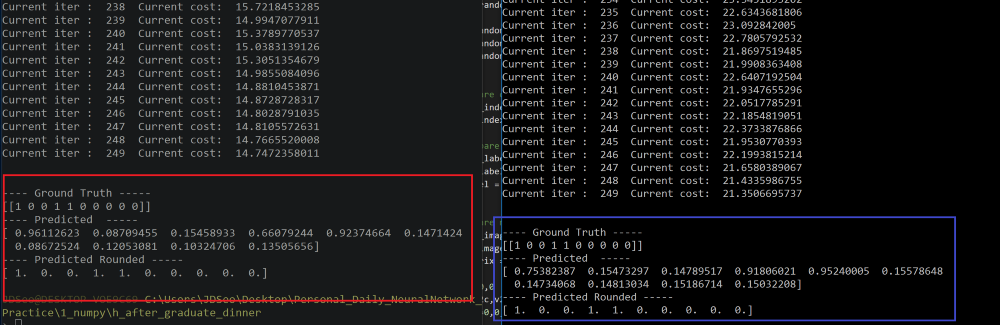
结果2:W3(16 * 48),W4(48 * 56)和W5(56,1)
红框→折回网络的结果
蓝框结果→原网络的结果
绿星结果→网络预测错误
这次有趣的是,折回网络的代价更高,但测试数据的准确率达到了100%。尽管原始网络的成本较低,但一些预测是错误的。
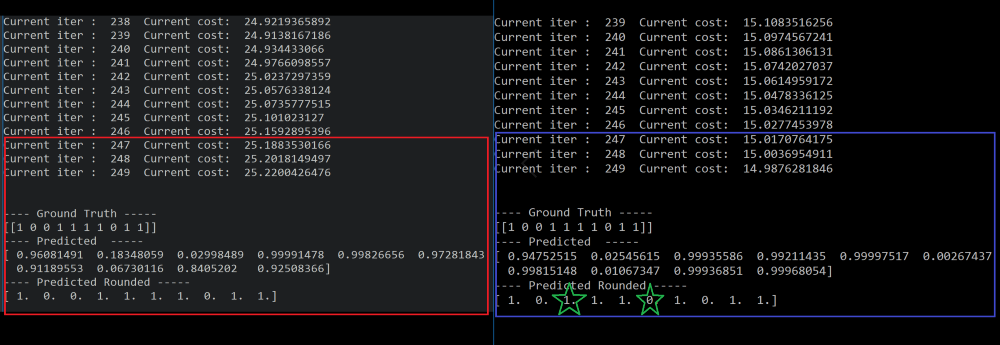
结果3:我忘记了这次的权重尺寸,但两个网络肯定是一样的。
红框→折回网络的结果
蓝框结果→原网络的结果
这次准确率都是100%。但折回网络的代价较高。
原始网络
注意:在线编译器没有“从sklearn中导入数据集”,所以我无法复制和粘贴笔记本电脑上使用的代码。所以我复制了四个训练示例,它们分别代表0,1,1,0的手写数字,并调整了超参数。
访问原始网络代码:https://repl.it/@Jae_DukDuk/Multi-Channel-and-Layer-Original
折回网络
注意:在线编译器没有“从sklearn中导入数据集”,所以我无法复制和粘贴笔记本电脑上使用的代码。所以我复制了四个训练示例,它们分别代表0,1,1,0的手写数字,并调整了超参数。
访问折回网络代码:https://repl.it/@Jae_DukDuk/Multi-Channel-and-Layer-Broken
结语
像这样的结果让我着迷,这就是我要做手动执行反向传播的原因。即使是Hinton博士自己,也怀疑反向传播,他希望人工智能有新的起点。然而对于我们来说,深入理解反向传播是非常重要的,尝试创造性的方法来看看,是否有其他方法可以做的更好。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消