











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






决策树完全指南(下)
2019年05月20日 由 sunlei 发表
762902
0

上一篇文章中我们了解DTs的重要性以及DTs的一些基础知识及算法。
前文回顾:决策树完全指南(上)
今天我们继续以下内容。
CART
CART是一种DT算法,根据从属(或目标)变量是分类的还是数值的,生成二进制分类树或回归树。它以原始形式处理数据(不需要预处理),并且可以在同一DT的不同部分多次使用相同的变量,这可能会揭示变量集之间的复杂依赖关系。
在分类树的情况下,CART算法使用一个称为Gini杂质的度量来为分类任务创建决策点。Gini杂质给出了一个关于分裂有多精细的概念(一个节点的“纯度”的度量),通过分裂产生的两个组中类的混合程度。当所有的观察结果都属于同一个标签时,就有了一个完美的分类,Gini杂质值为0(最小值)。另一方面,当所有的观测值在不同的标签间均匀分布时,我们将面临最坏情况下的分割结果,Gini杂质值为1(最大值)。
[caption id="attachment_40420" align="aligncenter" width="500"]
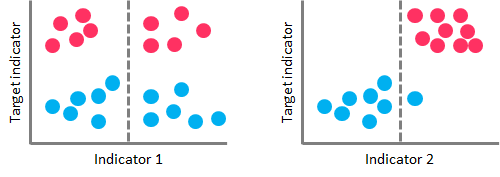 在左侧,高Gini杂质值导致分裂性能较差。在右边,较低的Gini杂质值实现了近乎完美的分裂[/caption]
在左侧,高Gini杂质值导致分裂性能较差。在右边,较低的Gini杂质值实现了近乎完美的分裂[/caption]在回归树的情况下,CART算法寻找最小化最小平方偏差(LSD)的分割,在所有可能的选项中选择最小化结果的分区。LSD(有时称为“方差减少”)度量最小化了观测值与预测值之间距离的平方(或偏差)之和。预测值与观测值之间的差异称为“残差”,即LSD选择参数估计值,使残差平方和最小化。
LSD非常适合度量数据,并且能够比其他算法正确地捕获更多关于分割质量的信息。
CART算法的思想是生成一个DTs序列,每个DTs序列都是“最优树”的候选树。通过测试(使用DT从未见过的新数据)或执行交叉验证(将数据集划分为“k”个折叠数,并在每个折叠上执行测试)来评估每棵树的性能,从而确定此最佳树。
CART不使用内部性能度量来选择树。相反,DTs性能总是通过测试或交叉验证来测量,并且只有在评估完成之后才进行树的选择。
ID3
迭代二分法(ID3)是一种DT算法,主要用于生成分类树。由于ID3在原始数据中构建回归树的有效性还没有被证明,所以它主要用于分类任务(尽管一些技术,如构建数值区间可以提高它在回归树上的性能)。
ID3分解数据属性(二分法)以找到最主要的特性,迭代地执行这个过程,以自顶向下的方式选择DT节点。
对于分割过程,ID3使用信息增益度量选择最有用的属性进行分类。信息增益是从信息论中提取出来的一个概念,它指的是一组数据中随机性水平的降低:基本上它衡量的是一个特征给我们提供了多少关于一个类的“信息”。ID3总是试图最大化这个度量,这意味着具有最高信息增益的属性将首先被分割。
信息增益与熵的概念直接相关,熵是对数据中不确定性或随机性的度量。熵值的范围从0(当所有成员都属于同一类或样本是完全齐次的)到1(当存在完全的随机性或不可预测性,或样本是等分的)。
你可以这样想:如果你想抛一枚硬币,完全随机或者熵值为1(“正面”和“反面”的概率相同,都是0.5)。另一方面,如果你抛硬币,比如一枚两面都有“反面”的硬币,那么事件的随机性就被去掉了,熵值为0(得到“反面”的概率将跳到1,得到“正面”的概率将降到0)。
[caption id="attachment_40421" align="aligncenter" width="640"]
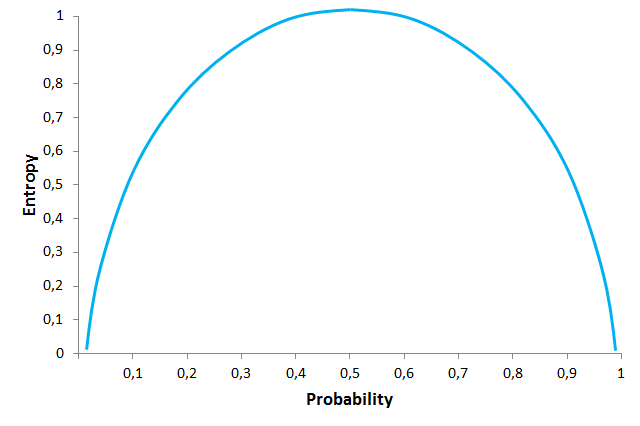 在这个图中,你可以看到熵和不同抛硬币概率之间的关系。在熵的最高水平,得到“反面”的概率等于得到“正面”的概率(各为0.5),我们面临着完全的不确定性。熵与事件发生的概率直接相关。示例取自空指针异常[/caption]
在这个图中,你可以看到熵和不同抛硬币概率之间的关系。在熵的最高水平,得到“反面”的概率等于得到“正面”的概率(各为0.5),我们面临着完全的不确定性。熵与事件发生的概率直接相关。示例取自空指针异常[/caption]这是很重要的,因为信息增益是熵的减少,并且为DT节点选择产生最大信息增益的属性。
但是ID3有一些缺点:它不能处理数值属性或丢失的值,这可能代表严重的局限性。
C4.5
C4.5是ID3的继承者,代表了几个方面的改进。C4.5可以同时处理连续数据和分类数据,适用于生成回归树和分类树。此外,它可以通过忽略包含不存在数据的实例来处理丢失的值。
与ID3(使用信息增益作为分割准则)不同,C4.5在分割过程中使用增益比。增益比是对信息增益概念的一种修正,它在选择属性时考虑到分支的数量和大小,从而减少了对具有大量分支的DTs的偏见。由于信息增益表现出对属性的不公平偏爱,且结果较多,因此增益比通过考虑每个分割的内在信息来修正这一趋势(它基本上是使用一个分割的信息值来“正常化”信息增益)。这样,选择增益比最大的属性作为分割属性。
此外,C4.5还包括一种称为窗口的技术,它最初是为了克服早期计算机的内存限制而开发的。窗口化意味着算法随机选择训练数据的子集(称为“窗口”),并根据该选择构建DT。然后用这个DT对剩余的训练数据进行分类,如果分类正确,就完成了DT。否则,所有分类错误的数据点都被添加到窗口中,循环往复,直到训练集中的每个实例都被当前DT正确分类为止。由于使用了随机化,这种技术通常会产生比标准过程更精确的DTs,因为它捕获了所有“罕见”的实例和足够的“普通”情况。
C4.5的另一个功能是可以修剪DTs。
C4.5的剪枝方法是基于估计每一个内部节点的错误率,如果叶子的估计错误率较低,则用叶子节点代替。简而言之,算法估计,如果删除节点的“子节点”并将该节点设置为叶子节点,则DT将更准确,那么C4.5将删除这些子节点。
这个算法的最新版本叫做C5.0,它是在专有许可下发布的,比C4.5有一些改进,比如:
- 改进的速度:0明显快于C4.5(几个数量级)。
- 内存使用:0比C4.5更有效。
- 可变误分类成本:在5中,所有的错误都被同等对待,但在实际应用中,一些分类错误比其他错误更严重。C5.0允许为每个预测的/实际的类对定义单独的成本。
- 更小的决策树:0使用更小的DTs获得与C4.5类似的结果。
- 附加数据类型:0可以处理日期、时间,并允许将值标注为“不适用”。
- 筛选:0可以在构造分类器之前自动筛选属性,丢弃那些可能没有帮助或看起来不相关的属性。
树的阴暗面
当然,DTs有很多优势。由于它们的简单性以及易于理解和实现的事实,它们被广泛用于许多行业的不同解决方案。但你也需要意识到它的缺点。
DTs倾向于过度匹配他们的训练数据,如果之前显示给他们的数据与之后显示的不匹配,他们的表现就会很差。
他们还遭受着高方差的困扰,这意味着数据中的一个小变化可能导致一组非常不同的分割,使得解释有些复杂。它们存在固有的不稳定性,因为由于它们的层次性,顶部分割中的错误影响会传播到下面的所有分割。
在分类树中,对某些类别的观测结果进行错误分类的后果比其他类别更为严重。例如,预测一个人在他/她真正会心脏病发作的时候不会心脏病发作可能比预测他/她不会心脏病发作的时候更糟糕。这个问题在C5.0等算法中得到了缓解,但在其他算法中仍然是一个严重的问题。
如果某些类占主导地位,则DTs还可以创建有偏差的树。这是不平衡数据集中的一个问题(数据集中不同的类有不同数量的观察值),在这种情况下,建议在构建DT之前平衡数据集。
在回归树的情况下,DTs只能根据他们之前看到的数据在他们创建的值的范围内进行预测,这意味着他们对他们能够生成的值有边界。
在每个级别上,DTs寻找可能的最佳分割,以便优化相应的分割标准。
但是DTs分裂算法只能看到当前运行的水平(它们是“贪婪的”),这意味着它们在每一步都在寻找局部最优,而不是全局最优。
DTs算法根据一定的分割准则,一次生成一个节点,不实现任何回溯技术。
集体的力量
有个好消息是:有不同的策略可以克服这些缺点。集成方法结合了多个DTs来提高单个DTs的性能,是克服上述问题的一个重要资源。其思想是使用相同的学习算法训练多个模型,以获得更好的结果。
可能最常见的两种表演合奏的技术是Bagging and Boosting。
当目标是减少DT的方差时,使用Bagging(或Bootstrap聚合)。方差与这样一个事实有关:DTs可能非常不稳定,因为数据中的微小变化可能导致生成完全不同的树。因此,Bagging的思想是通过创建并行随机数据子集(来自训练数据)来解决这个问题,其中任何观察都有相同的概率出现在新的子集数据中。接下来,使用每个子集数据集合来训练DTs,从而得到不同DTs的集合。最后,使用这些不同DTs的所有预测的平均值,从而产生比单个DTs更健壮的性能。Random Forest是Bagging的一个扩展,它需要额外的步骤:除了获取数据的随机子集,它还需要随机选择特性,而不是使用所有特性来增长DTs。
Boosting是另一种技术,它创建了一组预测因子来减少DT的方差,但方法不同。它使用一种顺序的方法来匹配连续的DTS,并且在每个步骤中,都试图减少来自前一个树的错误。利用增强技术,对每个分类器进行数据训练,同时考虑到之前分类器的成功。在每个训练步骤之后,根据之前的表现重新分配权重。这样,错误分类的数据会增加其权重,强调最困难的情况,以便后续的DTs在训练阶段将重点放在这些情况上,提高准确性。与Bagging不同的是,在增加观测值时要对观测值进行加权,因此其中一些观测值将更频繁地参与新的数据子集。在此基础上,将整个系统组合起来,提高了DTs的性能。
在Boosting中,有几种方法可以确定训练和分类步骤中要使用的权重(例如,Gradient Boost、XGBoost、Adaboost和其他方法)。感兴趣的话您可以去了解一下这两种技术之间的相似性和不同点的描述。
我的这篇文章您还满意吗?有问题可以留言给我。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
决策树完全指南(上)








广告


写评论取消
回复取消