











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






深度学习浪潮下的自然语言处理,百度CTO分享前沿进展
2019年12月24日 由 TGS 发表
456075
0
 自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。百度是国内顶尖的科技巨头,在自然语言处理方面一直处于排头兵的位置,近日,百度CTO王海峰在新一代人工智能院士高峰论坛上,分享自然语言处理前沿进展。
深度学习下的自然语言处理
 前段时间,机器学习领域国际顶级会议 NeurIPS 2019于加拿大温哥华拉开帷幕。此次大会共吸引了全球1万余名专家学者共赴盛会。
前段时间,机器学习领域国际顶级会议 NeurIPS 2019于加拿大温哥华拉开帷幕。此次大会共吸引了全球1万余名专家学者共赴盛会。本年度自然语言处理领域在深度学习浪潮下取得了显著成就,成为大会重要议题之一。当时百度举办了自然语言处理专题研讨会,百度技术委员会主席、自然语言处理首席科学家吴华博士以及多名研究员和工程师,向现场参会者全面介绍了百度在这一领域的长期积累与全新突破。基于具有完全自主知识产权的飞桨平台,百度自然语言处理在语义计算、阅读理解、多轮对话、机器翻译、开放平台与数据等方向均取得了突破性进展,并进行了大规模产业化应用。
 机器阅读理解,已成为评估机器语言理解能力的重要方式,也是搜索引擎和对话系统等行业应用中的关键技术。百度发布了最大规模的中文阅读理解数据集DuReader,在泛化方面提出训练框架D-NET,从多模型融合、多任务学习的角度提升模型的泛化能力;对于对抗样本的攻击,则是提出了一种面向阅读理解的对抗训练方法,提出文本表示和知识表示的融合模型KT-NET,以解决需要外部知识和常识性的问题。百度自然语言处理领域产出的卓越成果背后所运用的底层框架,是自研的开源深度学习平台百度飞桨。
机器阅读理解,已成为评估机器语言理解能力的重要方式,也是搜索引擎和对话系统等行业应用中的关键技术。百度发布了最大规模的中文阅读理解数据集DuReader,在泛化方面提出训练框架D-NET,从多模型融合、多任务学习的角度提升模型的泛化能力;对于对抗样本的攻击,则是提出了一种面向阅读理解的对抗训练方法,提出文本表示和知识表示的融合模型KT-NET,以解决需要外部知识和常识性的问题。百度自然语言处理领域产出的卓越成果背后所运用的底层框架,是自研的开源深度学习平台百度飞桨。近两年来,飞桨围绕深度学习框架的基本功能、性能、芯片支持的完备性等技术指标进行了一系列的易用性开发和性能迭代,为开发者提供了优于其他深度学习框架的使用体验。在开发能力方面,飞桨除了支持对常用API的调用之外,还在编程范式上同时支持声明式编程和命令式编程,兼具很好的灵活性和稳定性,可满足不同开发者的开发习惯,更易上手。在训练方面,飞桨平台突破了超大规模深度学习模型训练技术,研制了千亿特征、万亿参数、数百节点的开源大规模训练平台,实现了万亿规模参数深度学习模型的实时更新。在自然语言处理领域,PADDLE-NLP提供了面向6类任务下的30+算法模型,包括上述工作中ERNIE、D-NET等多个国际竞赛的冠军模型。
自然语言处理前沿进展
 前两日,新一代人工智能产业技术创新战略联盟主办的“2019新一代人工智能院士高峰论坛”在深圳举行。百度首席技术官王海峰出席论坛,并发表题为《自然语言处理前沿》的主题演讲,向与会嘉宾介绍了自然语言处理相关研究的发展历史和趋势,以及百度在自然语言处理技术和产业应用中取得的成果。
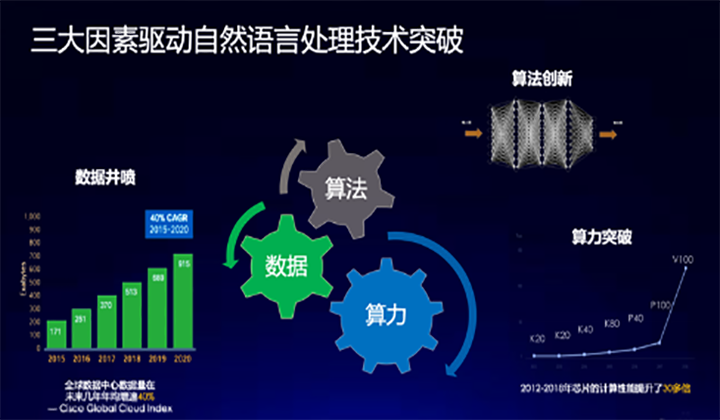
前两日,新一代人工智能产业技术创新战略联盟主办的“2019新一代人工智能院士高峰论坛”在深圳举行。百度首席技术官王海峰出席论坛,并发表题为《自然语言处理前沿》的主题演讲,向与会嘉宾介绍了自然语言处理相关研究的发展历史和趋势,以及百度在自然语言处理技术和产业应用中取得的成果。王海峰表示,自然语言处理(NLP)是用计算机来模拟、延伸及拓展人类语言能力的理论、技术及方法。近年来,算力持续突破、算法不断创新、数据爆发式增长,驱动自然语言处理技术飞速发展,呈现出很多新的变化:从传统 NLP进行层级式结构分析演变到直接的端到端语义表示;从过去局限于理解句子发展到现在多文本、跨模态的内容理解;而机器翻译经历了70年的发展,已经实现质量飞跃。
百度不仅在自然语言处理技术和产业应用中取得丰硕成果,更秉承开源开放、合作共赢的理念,构建了以飞桨深度学习平台为基础、集成语言与知识核心技术及多样化场景解决方案的开源开放大生产平台,赋能广大开发者技术创新,加速产业智能化转型升级。
随着百度自然语言处理技术能力增强,其平台化的能力也在显著增强,技术能力开放出来让技术应用的门槛越来越降低。基于飞桨深度学习平台的开源开放大生产平台百度大脑,已经具备了很高的标准化、自动化、模块化的工业大生产特征。同时,百度开放出来的所有语言和知识相关的技术,是基于百度的飞桨深度学习平台,有不同的部署,可以应用于不同场景,简而言之,就是可以满足不同的需求。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消