











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






比较分析:如何优化文本数据的分块方法
2023年07月25日 由 Alex 发表
750334
0
介绍
自然语言处理(NLP)中的“文本分块”过程涉及将非结构化文本数据转换为有意义的单元。这个看似简单的任务掩盖了实现它所采用的各种方法的复杂性,每种方法都有其优点和缺点。
在高层次上,这些方法通常分为两类。第一种是基于规则的方法,依赖于使用显式分隔符(如标点符号或空格字符)或应用复杂的系统(如正则表达式)将文本划分为块。第二类是语义聚类方法,它利用文本中嵌入的固有意义来指导分块过程。这些可能利用机器学习算法来辨别上下文并推断文本中的自然划分。
在本文中,我们将探索和比较这两种不同的文本分块方法。我们将使用NLTK、Space和Langchain表示基于规则的方法,并将其与两种不同的语义聚类技术进行对比:KMeans和用于Adjacent Sentences聚类的自定义技术。
目标是让从业者清楚地了解每种方法的优点、缺点和理想用例,以便在他们的NLP项目中做出更好的决策。
文本分块的用例
文本分块可以被多种不同的应用程序使用:
1. 文本摘要:通过将大量文本分解为可管理的块,我们可以单独总结每个部分,从而得到更准确的整体摘要。
2. 情感分析:与分析整个文档相比,分析较短、连贯的块的情感通常可以产生更精确的结果。
3. 信息提取:分块有助于在文本中定位特定的实体或短语,提高信息检索的过程。
4. 文本分类:将文本分解成块允许分类器专注于更小的、上下文有意义的单元,而不是整个文档,这可以提高性能。
5. 机器翻译:翻译系统通常对大块文本进行操作,而不是对单个单词或整个文档进行操作。分块法有助于保持译文的连贯性。
语义分块的不同方法比较
在本文的这一部分,我们将比较非结构化文本语义分块的流行方法:NLTK句子分词器、Langchain文本分词器、KMeans聚类和基于相似性的Adjacent Sentences聚类。
在下面的例子中,我们将使用从PDF中提取的文本来评估这种技术,并将其处理成句子及其簇。
为了从PDF中提取文本并使用NLTK将其分割成句子,我们使用了以下函数:
from PyPDF2 import PdfReader
import nltk
nltk.download('punkt')
# Extracting Text from PDF
def extract_text_from_pdf(file_path):
with open(file_path, 'rb') as file:
pdf = PdfReader(file)
text = " ".join(page.extract_text() for page in pdf.pages)
return text
# Extract text from the PDF and split it into sentences
text = extract_text_from_pdf(file_path)
像这样,我们以Wiki长度为210964个字符的字符串。
以下是维基文本的示例:
sample = text[1015:3037]
print(sample)
"""
=======
Output:
=======
Brazil is the world's fifth-largest country by area and the seventh most popul ous. Its capital
is Brasília, and its most popul ous city is São Paulo. The federation is composed of the union of the 26
states and the Federal District. It is the only country in the Americas to have Portugue se as an official
langua ge.[11][12] It is one of the most multicultural and ethnically diverse nations, due to over a century of
mass immigration from around t he world,[13] and the most popul ous Roman Catholic-majority country.
Bounde d by the Atlantic Ocean on the east, Brazil has a coastline of 7,491 kilometers (4,655 mi).[14] It
borders all other countries and territories in South America except Ecuador and Chile and covers roughl y
half of the continent's land area.[15] Its Amazon basin includes a vast tropical forest, home to diverse
wildlife, a variety of ecological systems, and extensive natural resources spanning numerous protected
habitats.[14] This unique environmental heritage positions Brazil at number one of 17 megadiverse
countries, and is the subject of significant global interest, as environmental degradation through processes
like deforestation has direct impacts on gl obal issues like climate change and biodiversity loss.
The territory which would become know n as Brazil was inhabited by numerous tribal nations prior to the
landing in 1500 of explorer Pedro Álvares Cabral, who claimed the discovered land for the Portugue se
Empire. Brazil remained a Portugue se colony until 1808 when the capital of the empire was transferred
from Lisbon to Rio de Janeiro. In 1815, the colony was elevated to the rank of kingdom upon the
formation of the United Kingdom of Portugal, Brazil and the Algarves. Independence was achieved in
1822 with the creation of the Empire of Brazil, a unitary state gove rned unde r a constitutional monarchy
and a parliamentary system. The ratification of the first constitution in 1824 led to the formation of a
bicameral legislature, now called the National Congress.
"""
NLTK句子分词器
自然语言工具包(NLTK)提供了将文本分割成句子的有用功能。这个句子标记器将给定的文本块分成它的组成句子,然后这些句子可以用于进一步的处理。
执行
下面是一个使用NLTK句子分词器的例子:
import nltk
nltk.download('punkt')
# Splitting Text into Sentences
def split_text_into_sentences(text):
sentences = nltk.sent_tokenize(text)
return sentences
sentences = split_text_into_sentences(text)
这将返回从输入文本中提取的2670个列表sentences,平均每个句子有78个字符。
评价NLTK句子分词器
虽然NLTK句子分词器是一种简单有效的方法,可以将大量文本分成单独的句子,但它确实有一定的局限性:
1. 语言依赖性:NLTK句子分词器很大程度上依赖于文本的语言。它在英语中表现良好,但在没有额外配置的情况下,其他语言可能无法提供准确的结果。
2. 缩写和标点符号:标记器偶尔会误解句子末尾的缩写或其他标点符号。这可能导致句子的片段被视为独立的句子。
3. 缺乏语义理解:像大多数分词器一样,NLTK句子分词器不考虑句子之间的语义关系。因此,跨多个句子的上下文可能会在标记化过程中丢失。
Spacy分句器
另一个强大的NLP库Space提供了一个严重依赖于语言规则的句子标记化功能。这与NLTK的方法类似。
执行
实现Spacy的分句器非常简单。下面是如何在Python中做到这一点:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
sentences = list(doc.sents)
这将返回从输入文本中提取的2336个列表sentences,平均每个句子有89个字符。
评价Spacy分句器
与Langchain字符文本分配器相比,Spacy的句子分配器倾向于创建更小的块,因为它严格遵守句子边界。当分析需要更小的文本单元时,这是有利的。
然而,像NLTK一样,Spacy的性能取决于输入文本的质量。对于标点或结构不佳的文本,识别出的句子边界可能并不总是准确的。
现在,我们将看到Langchain如何为文本数据分块提供一个框架,并进一步将其与NLTK和Space进行比较。
Langchain文本分词器
Langchain字符文本分词器的工作原理是在特定字符处递归地划分文本。它对一般文本特别有用。
分词器由一个字符列表定义。它尝试根据这些字符分割文本,直到生成的块满足所需的大小标准。默认列表为[“\n\n”,“\n”,“”,“”],目的是尽可能地将段落、句子和单词放在一起,以保持语义连贯。
执行
考虑下面的示例,我们使用此方法拆分从PDF中提取的示例文本。
# Initialize the text splitter with custom parameters
custom_text_splitter = RecursiveCharacterTextSplitter(
# Set custom chunk size
chunk_size = 100,
chunk_overlap = 20,
# Use length of the text as the size measure
length_function = len,
)
# Create the chunks
texts = custom_text_splitter.create_documents([sample])
# Print the first two chunks
print(f'### Chunk 1: \n\n{texts[0].page_content}\n\n=====\n')
print(f'### Chunk 2: \n\n{texts[1].page_content}\n\n=====')
"""
=======
Output:
=======
### Chunk 1:
Brazil is the world's fifth-largest country by area and the seventh most popul ous. Its capital
=====
### Chunk 2:
is Brasília, and its most popul ous city is São Paulo. The federation is composed of the union of
=====
"""
最后,我们得到3205个文本块,由texts列表表示。65.8个字符是这里每个块的平均值——比NLTK的平均值(79个字符)要少一点。
改变参数和使用'\n'分隔符:
对于在Langchain Splitter上更自定义的方法,我们可以根据需要更改chunk_size和chunk_overlap参数。此外,我们只能为分割操作指定一个字符(或一组字符),例如\n。这将引导拆分器仅在新的行字符处将文本分隔成块。
让我们考虑一个示例,其中我们将chunk_size设置为300,chunk_overlap设置为30,并且仅使用\n作为分隔符。
# Initialize the text splitter with custom parameters
custom_text_splitter = RecursiveCharacterTextSplitter(
# Set custom chunk size
chunk_size = 300,
chunk_overlap = 30,
# Use length of the text as the size measure
length_function = len,
# Use only "\n\n" as the separator
separators = ['\n']
)
# Create the chunks
custom_texts = custom_text_splitter.create_documents([sample])
# Print the first two chunks
print(f'### Chunk 1: \n\n{custom_texts[0].page_content}\n\n=====\n')
print(f'### Chunk 2: \n\n{custom_texts[1].page_content}\n\n=====')
现在,让我们比较一下标准参数集和自定义参数集的输出:
# Print the sampled chunks
print("==== Sample chunks from 'Standard Parameters': ====\n\n")
for i, chunk in enumerate(texts):
if i < 4:
print(f"### Chunk {i+1}: \n{chunk.page_content}\n")
print("==== Sample chunks from 'Custom Parameters': ====\n\n")
for i, chunk in enumerate(custom_texts):
if i < 4:
print(f"### Chunk {i+1}: \n{chunk.page_content}\n")
"""
=======
Output:
=======
==== Sample chunks from 'Standard Parameters': ====
### Chunk 1:
Brazil is the world's fifth-largest country by area and the seventh most popul ous. Its capital
### Chunk 2:
is Brasília, and its most popul ous city is São Paulo. The federation is composed of the union of
### Chunk 3:
of the union of the 26
### Chunk 4:
states and the Federal District. It is the only country in the Americas to have Portugue se as an
==== Sample chunks from 'Custom Parameters': ====
### Chunk 1:
Brazil is the world's fifth-largest country by area and the seventh most popul ous. Its capital
is Brasília, and its most popul ous city is São Paulo. The federation is composed of the union of the 26
### Chunk 2:
states and the Federal District. It is the only country in the Americas to have Portugue se as an official
langua ge.[11][12] It is one of the most multicultural and ethnically diverse nations, due to over a century of
### Chunk 3:
mass immigration from around t he world,[13] and the most popul ous Roman Catholic-majority country.
Bounde d by the Atlantic Ocean on the east, Brazil has a coastline of 7,491 kilometers (4,655 mi).[14] It
### Chunk 4:
borders all other countries and territories in South America except Ecuador and Chile and covers roughl y
half of the continent's land area.[15] Its Amazon basin includes a vast tropical forest, home to diverse
"""
我们已经可以看到,这些自定义参数产生更大的块,因此比默认参数集保留更多的内容。
评价Langchain文本分词器
在使用不同的参数将文本分成块之后,我们获得了两个块列表:texts和custom_texts,分别包含3205和1404个文本块。现在,让我们绘制这两个场景的块长度分布,以便更好地理解更改参数的影响。
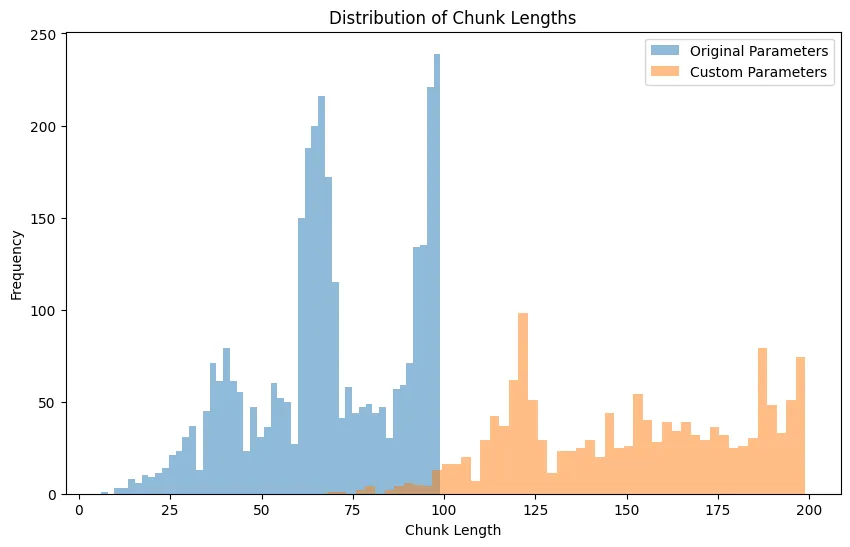
图 1:具有不同参数的 Langchain splitter 的块长度分布图
在这个直方图中,x轴表示块长度,y轴表示每个长度的频率。蓝色条表示原始参数的块长度分布,橙色条表示自定义参数的分布。通过比较这两个分布,我们可以看到参数的变化是如何影响生成的块长度的。
Langchain 文本分词器与NLTK和space
前面,我们使用带有默认参数的Langchain分词器生成了3205个块。另一方面,NLTK句子标记器将相同的文本分成总共2670个句子。
为了更直观地理解这些方法之间的差异,我们可以可视化块长度的分布。下图显示了每种方法的块长度密度,使我们能够看到长度是如何分布的以及大部分长度位于何处。
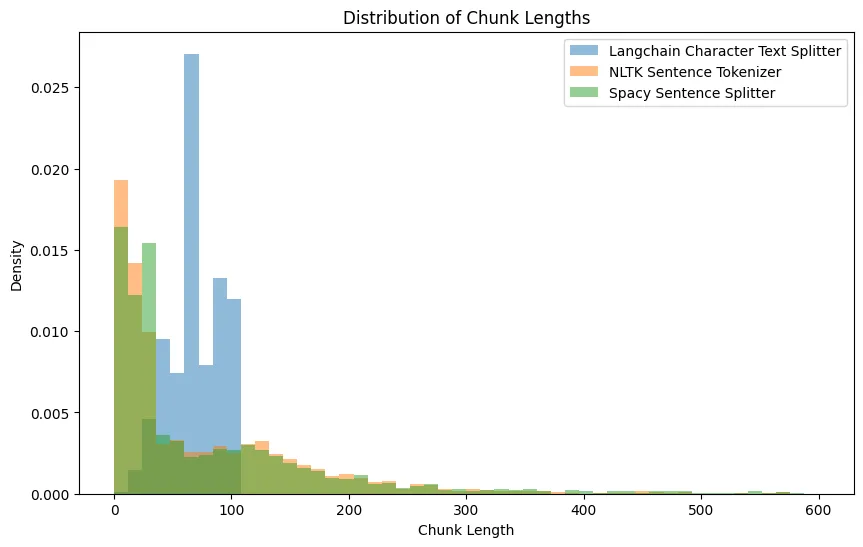
图 2:具有自定义参数的 Langchain Splitter 与 NLTK 和 Spacy 产生的块长度分布图
从图1中,我们可以看到Langchain分词器产生了更简洁的簇长度密度,并且倾向于产生更多更长的簇,而NLTK和space在簇长度方面似乎产生了非常相似的输出,它们更喜欢更小的句子,同时有许多长度可达1400个字符的异常值,并且长度有减少的趋势。
KMeans聚类
KMeans聚类是一种基于语义相似度对句子进行分组的技术。通过使用句子嵌入和K-means等聚类算法,我们可以实现句子聚类。
执行
下面是一个简单的示例代码片段,使用Python库sentence-transformer生成句子嵌入,使用scikit-learn生成K-means聚类:
from sentence_transformers import SentenceTransformer
from sklearn.cluster import KMeans
# Load the Sentence Transformer model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Define a list of sentences (your text data)
sentences = ["This is an example sentence.", "Another sentence goes here.", "..."]
# Generate embeddings for the sentences
embeddings = model.encode(sentences)
# Choose an appropriate number of clusters (here we choose 5 as an example)
num_clusters = 3
# Perform K-means clustering
kmeans = KMeans(n_clusters=num_clusters)
clusters = kmeans.fit_predict(embeddings)
你可以在这里看到聚类对句子列表的步骤是:
1. 加载句子转换模型。在本例中,我们将使用HuggingFace的sentence-transformers/all-MiniLM-L6-v2中的all-MiniLM-L6-v2模型。
2. 定义句子并使用模型中的encode()方法生成它们的嵌入。
3. 定义聚类技术和聚类数量(这里我们使用3个聚类的KMeans),最后将其拟合到数据集中。
评价KMeans聚类
最后,我们为每个集群绘制一个WordCloud。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import string
nltk.download('stopwords')
# Define a list of stop words
stop_words = set(stopwords.words('english'))
# Define a function to clean sentences
def clean_sentence(sentence):
# Tokenize the sentence
tokens = word_tokenize(sentence)
# Convert to lower case
tokens = [w.lower() for w in tokens]
# Remove punctuation
table = str.maketrans('', '', string.punctuation)
stripped = [w.translate(table) for w in tokens]
# Remove non-alphabetic tokens
words = [word for word in stripped if word.isalpha()]
# Filter out stop words
words = [w for w in words if not w in stop_words]
return words
# Compute and print Word Clouds for each cluster
for i in range(num_clusters):
cluster_sentences = [sentences[j] for j in range(len(sentences)) if clusters[j] == i]
cleaned_sentences = [' '.join(clean_sentence(s)) for s in cluster_sentences]
text = ' '.join(cleaned_sentences)
wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate(text)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.title(f"Cluster {i}")
plt.show()
下面是生成的集群的WordCloud图:

图 3:KMeans 聚类的词云图 — 聚类 0
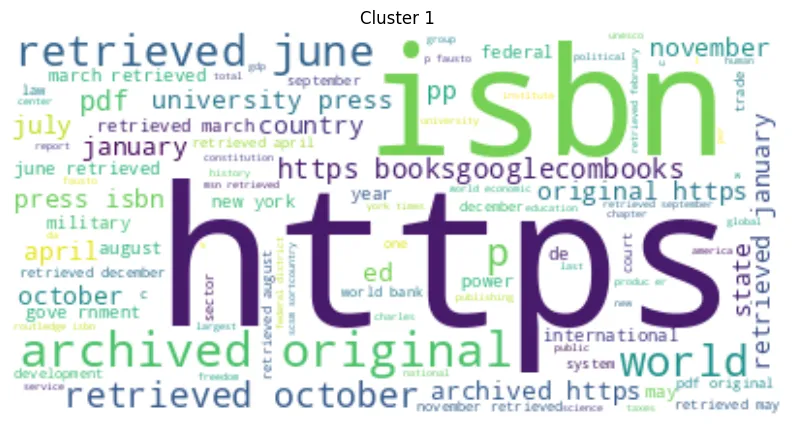
图 4:KMeans 聚类的词云图 — 聚类 1

图 5:KMeans 聚类的词云图 — 聚类 2
在我们对KMeans聚类的词云的分析中,很明显,每个聚类都基于其最常见单词的语义进行了独特的区分。这表明了集群之间强烈的语义分化。此外,观察到簇大小的显著变化,表明每个簇包含的序列数量存在显着差异。
KMeans聚类的局限性
KMeans聚类虽然有益,但也有一些明显的缺点。主要的限制包括:
1. 句子顺序丢失:KMeans聚类不保留句子的原始顺序,这可能会扭曲叙事的自然流程。这很重要。
2. 计算效率:KMeans可能是计算密集型的,并且速度很慢,特别是在使用大型文本语料库或使用大量集群时。对于实时应用程序或处理大数据来说,这可能是一个重大缺陷。
Adjacent Sentences聚类
为了克服KMeans聚类的一些限制,特别是句子顺序的丢失,一种替代方法是基于语义相似度对Adjacent Sentences进行聚类。这种方法的基本前提是,在文本中连续出现的两个句子比相隔较远的两个句子更有可能在语义上相关。
执行
下面是使用Spacy 句子作为输入的启发式的扩展实现:
import numpy as np
import spacy
# Load the Spacy model
nlp = spacy.load('en_core_web_sm')
def process(text):
doc = nlp(text)
sents = list(doc.sents)
vecs = np.stack([sent.vector / sent.vector_norm for sent in sents])
return sents, vecs
def cluster_text(sents, vecs, threshold):
clusters = [[0]]
for i in range(1, len(sents)):
if np.dot(vecs[i], vecs[i-1]) < threshold:
clusters.append([])
clusters[-1].append(i)
return clusters
def clean_text(text):
# Add your text cleaning process here
return text
# Initialize the clusters lengths list and final texts list
clusters_lens = []
final_texts = []
# Process the chunk
threshold = 0.3
sents, vecs = process(text)
# Cluster the sentences
clusters = cluster_text(sents, vecs, threshold)
for cluster in clusters:
cluster_txt = clean_text(' '.join([sents[i].text for i in cluster]))
cluster_len = len(cluster_txt)
# Check if the cluster is too short
if cluster_len < 60:
continue
# Check if the cluster is too long
elif cluster_len > 3000:
threshold = 0.6
sents_div, vecs_div = process(cluster_txt)
reclusters = cluster_text(sents_div, vecs_div, threshold)
for subcluster in reclusters:
div_txt = clean_text(' '.join([sents_div[i].text for i in subcluster]))
div_len = len(div_txt)
if div_len < 60 or div_len > 3000:
continue
clusters_lens.append(div_len)
final_texts.append(div_txt)
else:
clusters_lens.append(cluster_len)
final_texts.append(cluster_txt)
这段代码的关键要点:
1. 文本处理:将每个文本块传递给处理函数。该函数使用SpaCy库创建句子嵌入,句子嵌入用于表示文本块中每个句子的语义。
2. 聚类创建:cluster_text函数根据其嵌入的余弦相似性来形成句子的聚类。如果余弦相似度小于指定的阈值,则开始一个新的群集。
3. 长度检查:代码检查每个簇的长度。如果簇太短(少于60个字符)或太长(超过3000个字符),则调整阈值,并针对特定集群重复该过程,直到达到可接受的长度。
让我们来看看这种方法的一些输出块,并将它们与Langchain Splitter进行比较:
==== Sample chunks from 'Langchain Splitter with Custom Parameters': ====
### Chunk 1:
Brazil is the world's fifth-largest country by area and the seventh most popul ous. Its capital
is Brasília, and its most popul ous city is São Paulo. The federation is composed of the union of the 26
### Chunk 2:
states and the Federal District. It is the only country in the Americas to have Portugue se as an official
langua ge.[11][12] It is one of the most multicultural and ethnically diverse nations, due to over a century of
==== Sample chunks from 'Adjacent Sentences Clustering': ====
### Chunk 1:
Brazil is the world's fifth-largest country by area and the seventh most popul ous. Its capital
is Brasília, and its most popul ous city is São Paulo.
### Chunk 2:
The federation is composed of the union of the 26
states and the Federal District. It is the only country in the Americas to have Portugue se as an official
langua ge.[11][12]
很好,现在让我们比较final_texts的块长度分布与Langchain字符文本分词器和NLTK句子分词器的分布。要做到这一点,我们首先需要计算final_texts中块的长度:
final_texts_lengths = [len(chunk) for chunk in final_texts]len(chunk) for chunk in final_texts]
现在我们可以绘制出这三种方法的分布:
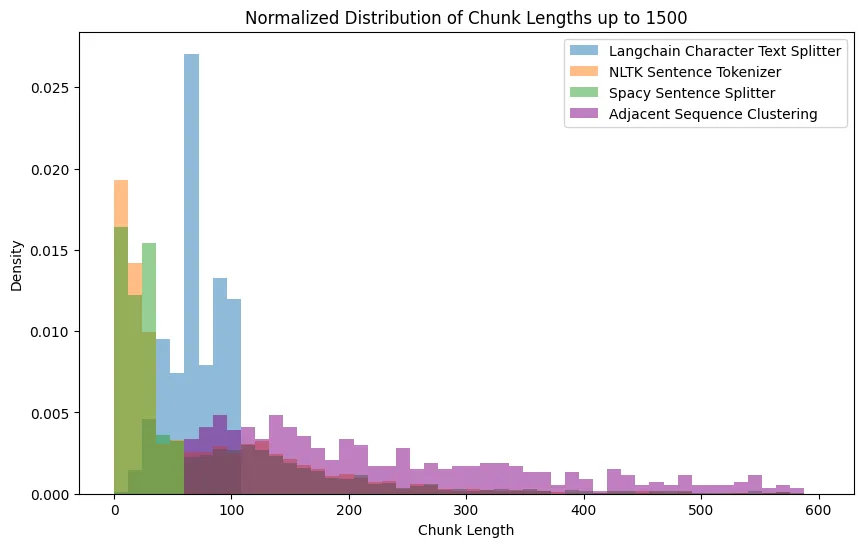
图 6:所有不同测试方法得出的块长度分布图
从图6中,我们可以得出,使用其预定义的块大小的Langchain拆分器创建了均匀的分布,这意味着一致的块长度。
另一方面,space Sentence Splitter和NLTK Sentence Tokenizer似乎更喜欢较小的句子,尽管有许多较大的异常值,这表明它们依赖于语言线索来确定分割并可能产生不规则大小的块。
最后,基于语义相似度聚类的自定义Adjacent Sentences聚类方法呈现出更多样化的分布。这可能是一种更加上下文敏感的方法,在保持块内内容的一致性的同时允许更大的大小灵活性。
评价Adjacent Sentences聚类方法
Adjacent Sentences聚类方法具有独特的优点:
1. 语境连贯:通过考虑语义和语境的连贯,生成主题一致的语块。
2. 灵活性:平衡上下文保存和计算效率,提供可调整的块大小。
3. 阈值调整:允许用户根据自己的需要,通过调整相似度阈值来微调分块过程。
4. 序列保存:保留文本中句子的原始顺序,这对于顺序语言模型和文本顺序重要的任务至关重要。
比较文本分块方法:见解总结
Langchain 文本分词器
此方法提供一致的块长度,从而产生均匀分布。当下游处理或分析需要标准尺寸时,这可能是有益的。该方法对文本的特定语言结构不太敏感,而是更侧重于生成预定义字符长度的块。
NLTK句子分词器和Spacy 句子分词器
这些方法表现出对较小句子的偏好,但也包含许多较大的异常值。虽然这可以产生语言上更连贯的块,但它也会导致块大小的高度可变性。
这些方法可以产生良好的结果,也可以作为下游任务的输入。
Adjacent Sentences聚类
这种方法产生了一个更多样化的分布,表明了它对上下文敏感的方法。通过基于语义相似性的聚类,它确保每个块内的内容是一致的,同时允许块大小的灵活性。当需要保持文本数据的语义连续性时,这种方法可能是有利的。
为了更直观和抽象的表示,让我们看看下面的图7,并试着找出哪种菠萝“切”更能代表所讨论的方法:
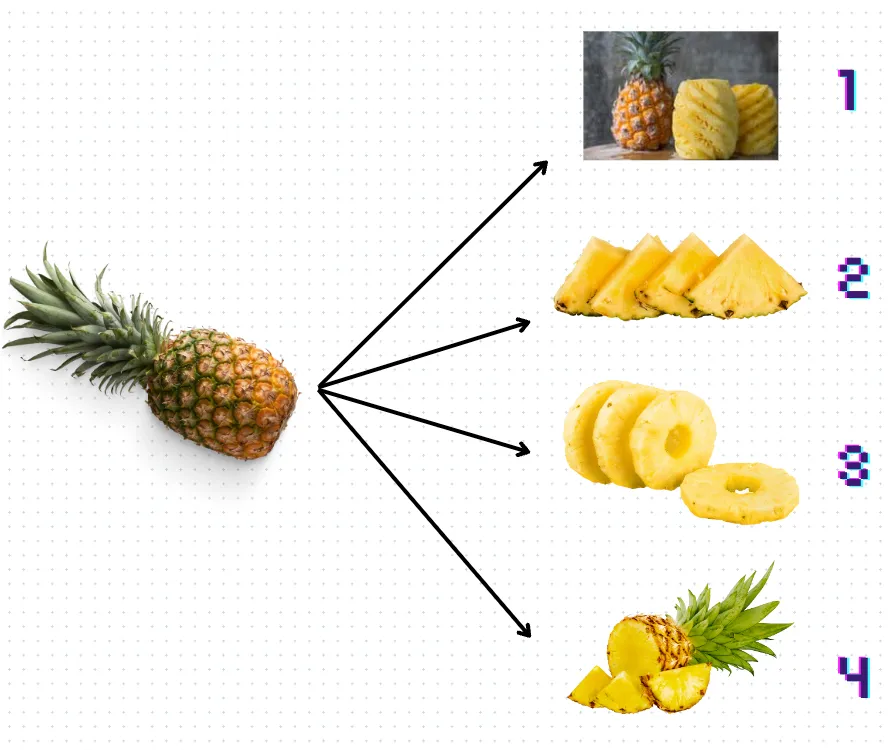
图 7:显示为菠萝剪切的不同文本分块方法
将它们按顺序列出:
1. 第1号方法代表的是基于规则的方法,你可以根据过滤器或正则表达式来“去除”所需的“垃圾”文本。
2. Langchain就像切割方式2一样,大小非常相似,但并没有保留整个所需的上下文(它是一个三角形,所以也可以是一个西瓜)。
3. 第三号切割方法是KMeans。你甚至可以仅按照自己认为有意义的方式进行分组-但你无法获取其核心。没有核心部分,这些块失去了所有的结构和含义。
4. 最后,第四号切割方法是Adjacent Sentences聚类方法。块的大小可以有所不同,但它们通常保留上下文信息,类似于不均匀的菠萝块,仍然可以指示水果的整体结构。
总结
在本文中,我们比较了三种文本分块方法及其独特的优点。Langchain提供一致的块大小,但语言结构退居次要地位。NLTK和Spacy提供语言上连贯的块,但大小差异很大。Adjacent Sentences聚类基于语义相似性聚类,提供灵活块大小的内容一致性。最终,最佳选择取决于你的特定需求,包括语言一致性、块大小的一致性和可用的计算能力。
来源:https://medium.com/towards-data-science/how-to-chunk-text-data-a-comparative-analysis-3858c4a0997a

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消