











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Llama2模型功能介绍以及如何在本地计算机上运行
2023年07月28日 由 Alex 发表
947836
0
在本文中,我将指出Llama2模型的主要功能,并向你展示如何在本地计算机上运行Llama2模型。
让我们首先看一下有哪些关键变化。
关键变化:
1. 上下文大小从2,048个令牌增加到4,096个
2. 多训练40%的代币,在常见基准测试中获得更好的结果
3. 允许商业用途
4. 发布了微调的聊天版本(提供了比ChatGPT更有帮助的回复)
在我们开始研究如何在本地计算机上运行Llama2模型之前,让我们首先更好地了解Llama2模型中的新功能。
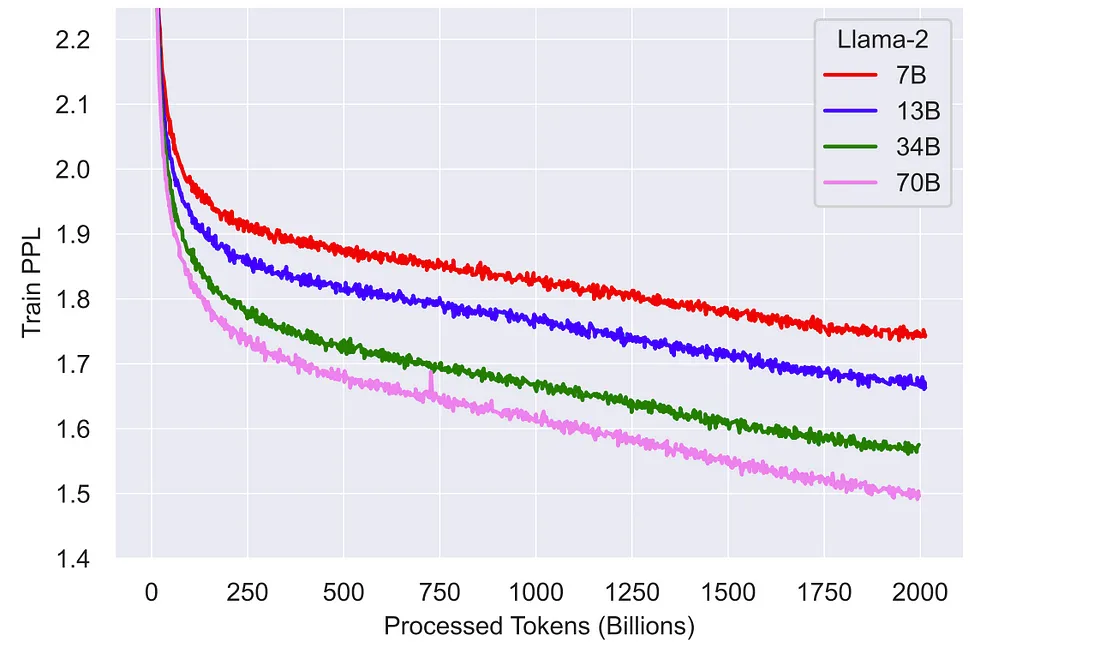
首先,上下文大小从2,048个令牌增加到4,096个。其次,与第一个版本相比,Llama2模型训练了大约40%的代币。有趣的是,这些模型(尤其是像70B模型这样有更多参数的模型)似乎还没有饱和,如果训练时间更长,使用更多的令牌,可能会表现得更好。这是论文中相应的图表:
根据人工评估,与ChatGPT相比,Llama2-70B-Chat模型的答案总体上更有帮助。我再次强调,这个模型可以免费使用。而且这次的许可证还允许商业使用,这真的很酷。至少在你的月活跃用户不少于7亿。但在我夸大其词之前,让我们仔细看看Llama2模型与该领域的大玩家相比是如何的:
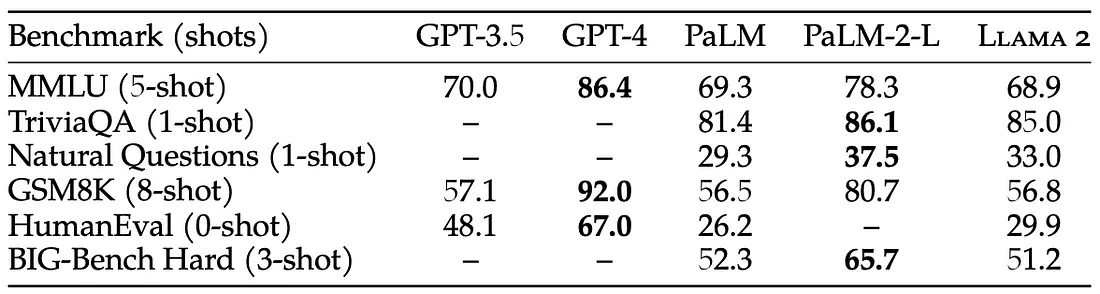
我们可以看到,在常见的学术基准测试中,Llama2模型的总体表现不如GPT-4或PaLM-2-L等最先进的模型。但是,请记住,这些都是闭源模型。如下表所示,Llama2模型似乎是最好的开源模型:
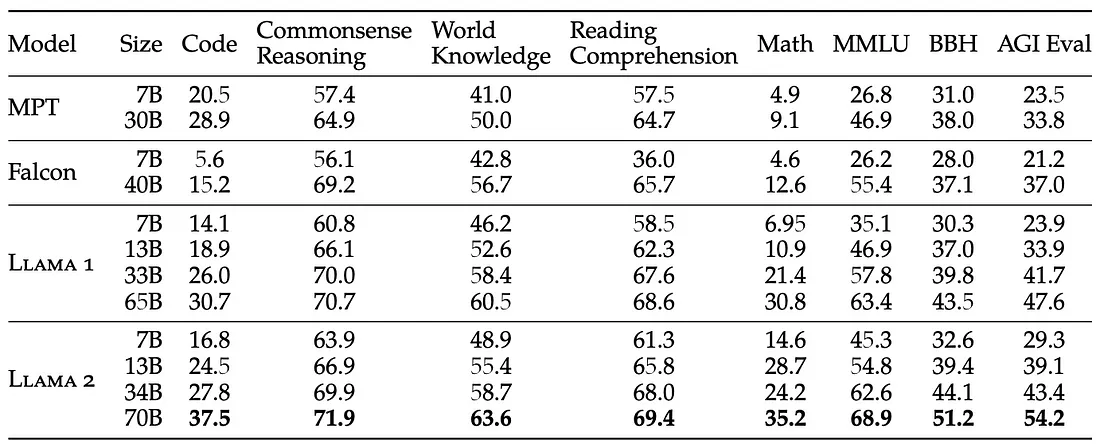
在这些表中需要注意的一件事是,Llama2模型似乎在大量任务上表现得非常好(MMLU基准测试特别涵盖了这一点),但在编码任务方面,它似乎表现得更差,从代码基准测试和HumanEval基准测试中可以看出这一点。
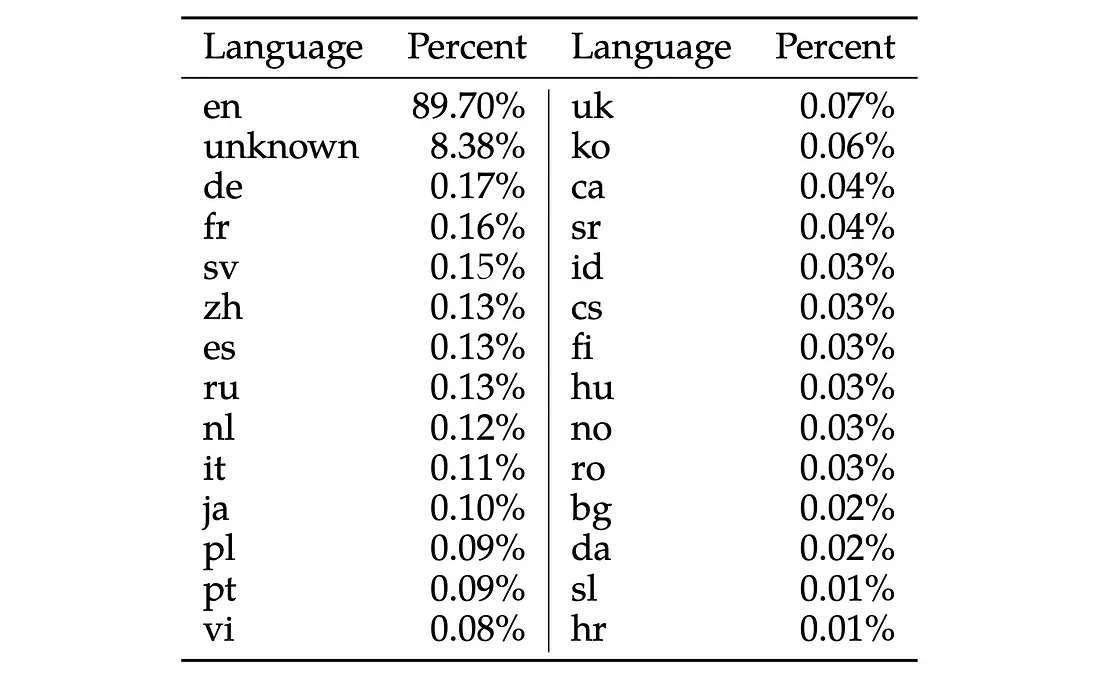
此外,Llama模型似乎是针对英语语言的,因为其他语言只占用于训练Llama2模型的数据集的很小一部分:
与最初的LLaMa模型一样,Llama2模型是一个预训练的基础模型。然而,这次Meta还发布了一个已经经过微调的聊天工具Llama2模型(称为Llama2- Chat)。为此,他们首先使用约27,000个高质量的提示和回答示例对模型进行了微调。然后,他们使用带有人类反馈的强化学习(RLHF)对模型进行了改进,为此,他们收集了超过100万份人类标记的二元比较,比较了微调模型在帮助和安全性方面的两种不同反应。
最后,如果你计划使用Llama2模型来训练你自己的大型语言模型(LLM),我想强调另外一件事。根据Meta的社区许可协议,禁止使用Llama2模型的答案来训练其他大型语言模型:
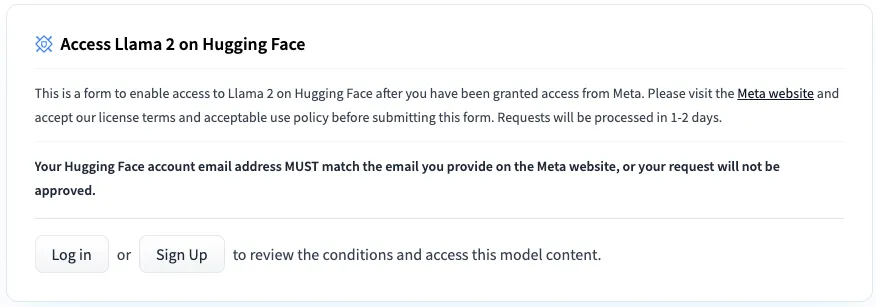
为了能够从Huggingface下载模型权重和标记器,你首先需要访问Meta AI网站并接受他们的许可(我的请求在30分钟内获得批准,但可能需要长达两天的时间)。确保你的邮箱地址和你的Hugging Face账号相同。一旦你的请求被接受,你需要转到Llama2 Hugging Face 存储库之一(例如Llama2 - 7b模型),并再次请求访问那里,如下图所示(访问应该立即被授予):
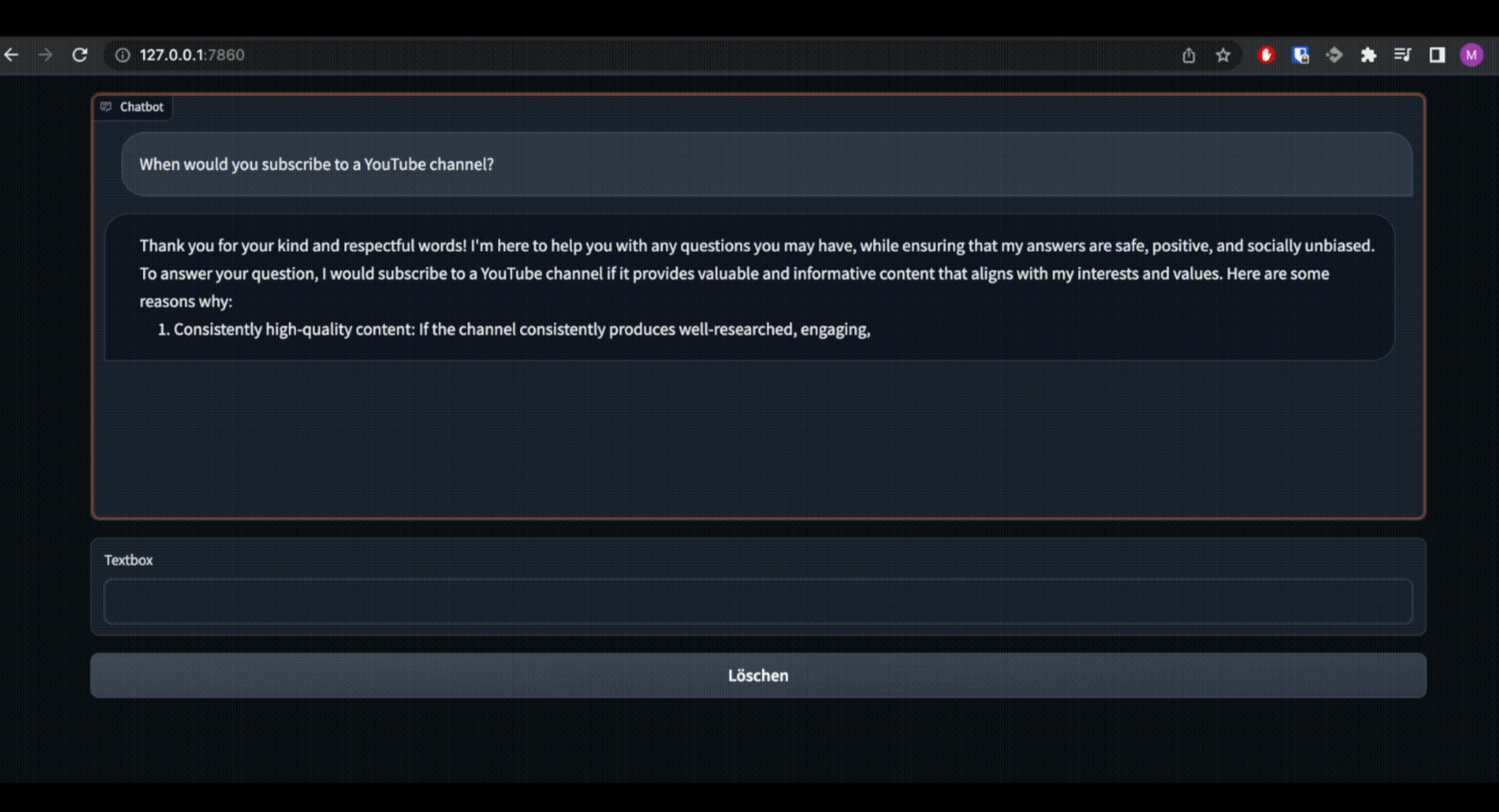
为了能够以视觉上吸引人的方式与本地计算机上Llama2模型的不同变体进行交互,我编写了几行代码。为此,我使用了grado模块作为用户界面,它可以用来与Llama2模型进行交互。此外,我还使用了transformer模块对模型进行推理,以及在用户界面中传输模型响应的能力。它是这样的:
由于原始的全精度Llama2模型需要大量的VRAM或多个GPU来加载,因此我修改了我的代码,以便也可以加载量化GPTQ和GGML模型变体(也称为Llama.cpp)。但是,这些量化模型变体(尤其是量化的GGML变体)比全精度模型变体表现得更差。然而,对于我们中的许多人来说,量化是在本地计算机上运行Llama2这样的大型语言模型的唯一方法。
现在开始安装。首先,建议安装Miniconda并创建一个新的虚拟环境,以避免在多个Python项目之间跳转时发生版本冲突。但是,这一步是可选的。要创建虚拟环境,在cmd或终端中输入以下命令:
接下来,我们将克隆包含我编写的代码的存储库:
然后我们将安装所有需要的模块:
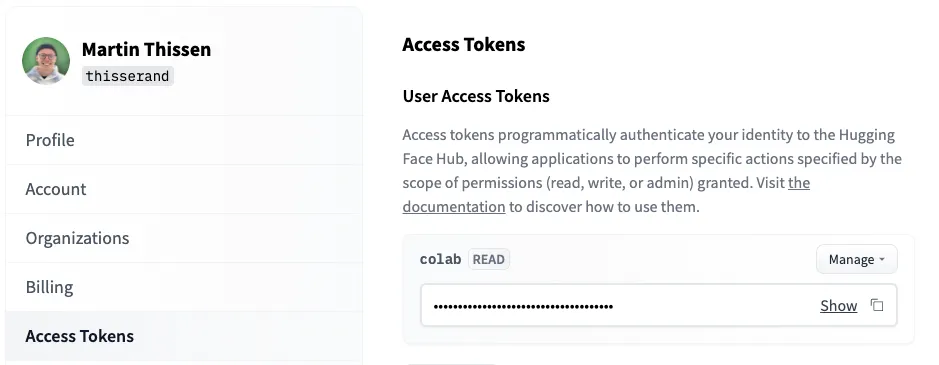
最后一步,你需要在当前运行时登录到你的Hugging Face帐户以下载模型权重和标记器。然后,使用以下命令:
系统会要求你提供Hugging Face访问令牌,你可以在这里找到该令牌:https://huggingface.co/settings/tokens
现在我们终于可以在本地计算机上运行各个Llama2模型变体了。这非常简单,你只需要运行一行代码。例如,要在CPU上运行ggml量化的Llama2-7B聊天变体,请使用以下命令:
在这里你可以找到其他型号的更详细的列表:
Llama2-7B:
Llama2-7B-Chat:
Llama2-13B:
Llama2-13B-Chat:
Llama2-70B:
Llama2-70B-Chat:
Llama2-7B:
Llama2-7B-Chat:
Llama2-13B:
Llama2-13B-Chat:
Llama2-70B:
Llama2-70B-Chat:
Llama2-7B:
Llama2-7B-Chat:
Llama2-13B:
Llama2-13B-Chat:
来源:https://medium.com/@martin-thissen/llama2-chat-on-your-local-computer-free-gpt-4-alternative-41b7638033a8
让我们首先看一下有哪些关键变化。
关键变化:
1. 上下文大小从2,048个令牌增加到4,096个
2. 多训练40%的代币,在常见基准测试中获得更好的结果
3. 允许商业用途
4. 发布了微调的聊天版本(提供了比ChatGPT更有帮助的回复)
看看Llama2论文
在我们开始研究如何在本地计算机上运行Llama2模型之前,让我们首先更好地了解Llama2模型中的新功能。
首先,上下文大小从2,048个令牌增加到4,096个。其次,与第一个版本相比,Llama2模型训练了大约40%的代币。有趣的是,这些模型(尤其是像70B模型这样有更多参数的模型)似乎还没有饱和,如果训练时间更长,使用更多的令牌,可能会表现得更好。这是论文中相应的图表:
根据人工评估,与ChatGPT相比,Llama2-70B-Chat模型的答案总体上更有帮助。我再次强调,这个模型可以免费使用。而且这次的许可证还允许商业使用,这真的很酷。至少在你的月活跃用户不少于7亿。但在我夸大其词之前,让我们仔细看看Llama2模型与该领域的大玩家相比是如何的:
我们可以看到,在常见的学术基准测试中,Llama2模型的总体表现不如GPT-4或PaLM-2-L等最先进的模型。但是,请记住,这些都是闭源模型。如下表所示,Llama2模型似乎是最好的开源模型:
在这些表中需要注意的一件事是,Llama2模型似乎在大量任务上表现得非常好(MMLU基准测试特别涵盖了这一点),但在编码任务方面,它似乎表现得更差,从代码基准测试和HumanEval基准测试中可以看出这一点。
此外,Llama模型似乎是针对英语语言的,因为其他语言只占用于训练Llama2模型的数据集的很小一部分:
与最初的LLaMa模型一样,Llama2模型是一个预训练的基础模型。然而,这次Meta还发布了一个已经经过微调的聊天工具Llama2模型(称为Llama2- Chat)。为此,他们首先使用约27,000个高质量的提示和回答示例对模型进行了微调。然后,他们使用带有人类反馈的强化学习(RLHF)对模型进行了改进,为此,他们收集了超过100万份人类标记的二元比较,比较了微调模型在帮助和安全性方面的两种不同反应。
最后,如果你计划使用Llama2模型来训练你自己的大型语言模型(LLM),我想强调另外一件事。根据Meta的社区许可协议,禁止使用Llama2模型的答案来训练其他大型语言模型:
“你不得使用Llama材料或Llama材料的任何输出或结果来改进任何其他大型语言模型(不包括Llama 2或其衍生作品)。”
在本地电脑上运行Llama2和Llama2- Chat
为了能够从Huggingface下载模型权重和标记器,你首先需要访问Meta AI网站并接受他们的许可(我的请求在30分钟内获得批准,但可能需要长达两天的时间)。确保你的邮箱地址和你的Hugging Face账号相同。一旦你的请求被接受,你需要转到Llama2 Hugging Face 存储库之一(例如Llama2 - 7b模型),并再次请求访问那里,如下图所示(访问应该立即被授予):
安装
为了能够以视觉上吸引人的方式与本地计算机上Llama2模型的不同变体进行交互,我编写了几行代码。为此,我使用了grado模块作为用户界面,它可以用来与Llama2模型进行交互。此外,我还使用了transformer模块对模型进行推理,以及在用户界面中传输模型响应的能力。它是这样的:
由于原始的全精度Llama2模型需要大量的VRAM或多个GPU来加载,因此我修改了我的代码,以便也可以加载量化GPTQ和GGML模型变体(也称为Llama.cpp)。但是,这些量化模型变体(尤其是量化的GGML变体)比全精度模型变体表现得更差。然而,对于我们中的许多人来说,量化是在本地计算机上运行Llama2这样的大型语言模型的唯一方法。
现在开始安装。首先,建议安装Miniconda并创建一个新的虚拟环境,以避免在多个Python项目之间跳转时发生版本冲突。但是,这一步是可选的。要创建虚拟环境,在cmd或终端中输入以下命令:
conda create -n llama2_local python=3.9
conda activate llama2_local
接下来,我们将克隆包含我编写的代码的存储库:
git clone https://github.com/thisserand/llama2_local.git
cd llama2_local
然后我们将安装所有需要的模块:
pip install -r requirements.txt
最后一步,你需要在当前运行时登录到你的Hugging Face帐户以下载模型权重和标记器。然后,使用以下命令:
huggingface-cli login
系统会要求你提供Hugging Face访问令牌,你可以在这里找到该令牌:https://huggingface.co/settings/tokens
用法
现在我们终于可以在本地计算机上运行各个Llama2模型变体了。这非常简单,你只需要运行一行代码。例如,要在CPU上运行ggml量化的Llama2-7B聊天变体,请使用以下命令:
python llama.py --model_name="TheBloke/Llama-2-7B-Chat-GGML" --file_name="llama-2-7b-chat.ggmlv3.q4_K_M.bin"
在这里你可以找到其他型号的更详细的列表:
全精度(原)
Llama2-7B:
python llama.py --model_name="meta-llama/Llama-2-7b-hf"
Llama2-7B-Chat:
python llama.py --model_name="meta-llama/Llama-2-7b-chat-hf"
Llama2-13B:
python llama.py --model_name="meta-llama/Llama-2-13b-hf"
Llama2-13B-Chat:
python llama.py --model_name="meta-llama/Llama-2-13b-chat-hf"
Llama2-70B:
python llama.py --model_name="meta-llama/Llama-2-70b-hf"
Llama2-70B-Chat:
python llama.py --model_name="meta-llama/Llama-2-70b-chat-hf"
GPTQ量化
Llama2-7B:
python llama.py --model_name="TheBloke/Llama-2-7B-GPTQ"
Llama2-7B-Chat:
python llama.py --model_name="TheBloke/Llama-2-7b-Chat-GPTQ"
Llama2-13B:
python llama.py --model_name="TheBloke/Llama-2-13B-GPTQ"
Llama2-13B-Chat:
python llama.py --model_name="TheBloke/Llama-2-13B-Chat-GPTQ"
Llama2-70B:
python llama.py --model_name="TheBloke/Llama-2-70B-GPTQ"
Llama2-70B-Chat:
python llama.py --model_name="TheBloke/Llama-2-70B-Chat-GPTQ"
GGML量化
Llama2-7B:
python llama.py --model_name="TheBloke/Llama-2-7B-GGML" --file_name="llama-2-7b.ggmlv3.q4_K_M.bin"
Llama2-7B-Chat:
python llama.py --model_name="TheBloke/Llama-2-7B-Chat-GGML" --file_name="llama-2-7b-chat.ggmlv3.q4_K_M.bin"
Llama2-13B:
python llama.py --model_name="TheBloke/Llama-2-13B-GGML" --file_name="llama-2-13b.ggmlv3.q4_K_M.bin"
Llama2-13B-Chat:
python llama.py --model_name="TheBloke/Llama-2-13B-Chat-GGML" --file_name="llama-2-13b-chat.ggmlv3.q4_K_M.bin"
来源:https://medium.com/@martin-thissen/llama2-chat-on-your-local-computer-free-gpt-4-alternative-41b7638033a8

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消